
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

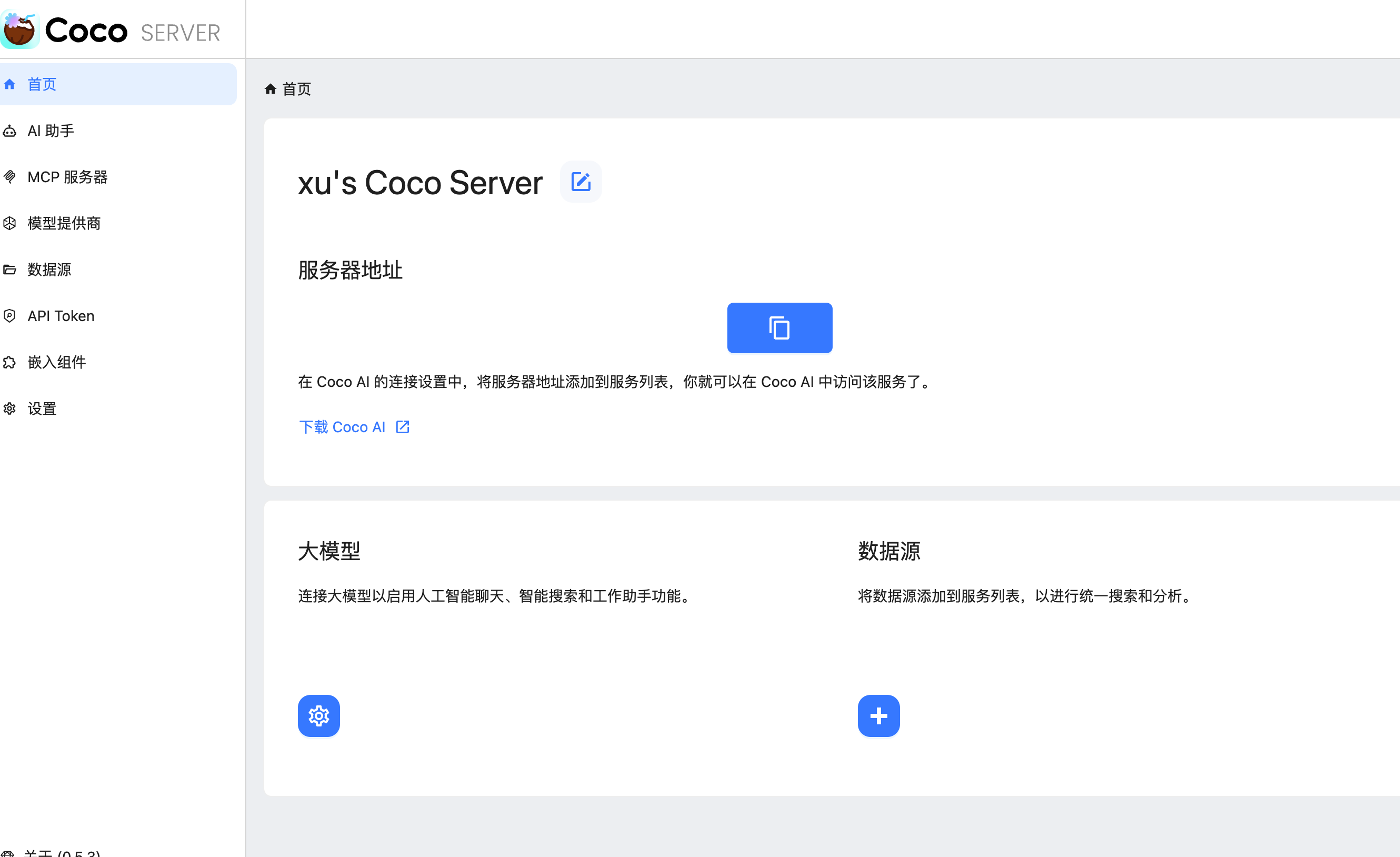
coco-ai
🥥 Coco AI App - Search, Connect, Collaborate, Your Personal AI Search and Assistant, all in one space.
安装次数
点赞
应用评论
催更次数
桌面端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
🥥 Coco AI App - Search, Connect, Collaborate, Your Personal AI Search and Assistant, all in one space.
相关攻略

Coco-AI × Amazon S3:秒搜你的云端文件
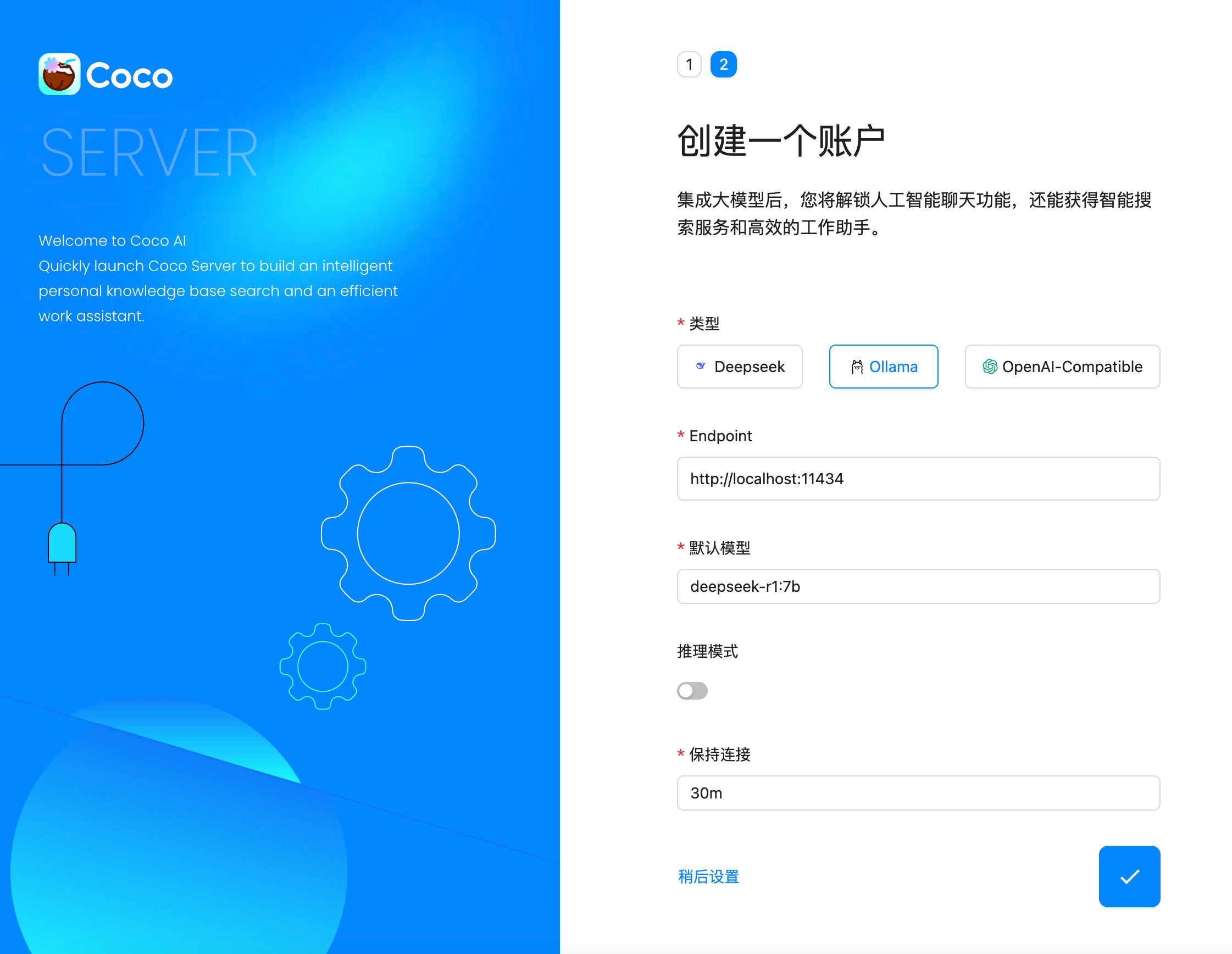
随着企业和个人数据量的激增,如何高效管理与搜索云端资料,成为提升工作效率的关键。 **Coco-AI** 新增的 **S3 对象存储连接器**,可以将 **Amazon S3** 存储桶直接接入智能检索系统,实现秒级搜索、即时访问,让云端文件像本地文档一样触手可及。 本篇将详细介绍如何通过 **Docker 快速部署 Coco Server**,并配置 S3 连接器,完成与亚马逊云科技的无缝集成。 ### 一、快速部署 Coco Server Coco Server 是连接器功能的运行核心,部署好它后才能接入 S3。 生产环境建议使用持久化存储方式,避免数据丢失。 在应用商店中下载 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai --- ### 二、配置 AI 模型 创建用户后,我选择 **Ollama** 作为模型提供商: - 地址:`http://localhost:11434` - 模型:`deepseek-r1:7b`  在「模型提供商」界面可以看到默认开启的 **Coco AI**,它会直接调用我配置的 Ollama,也支持其他兼容 OpenAI API 的 LLM。 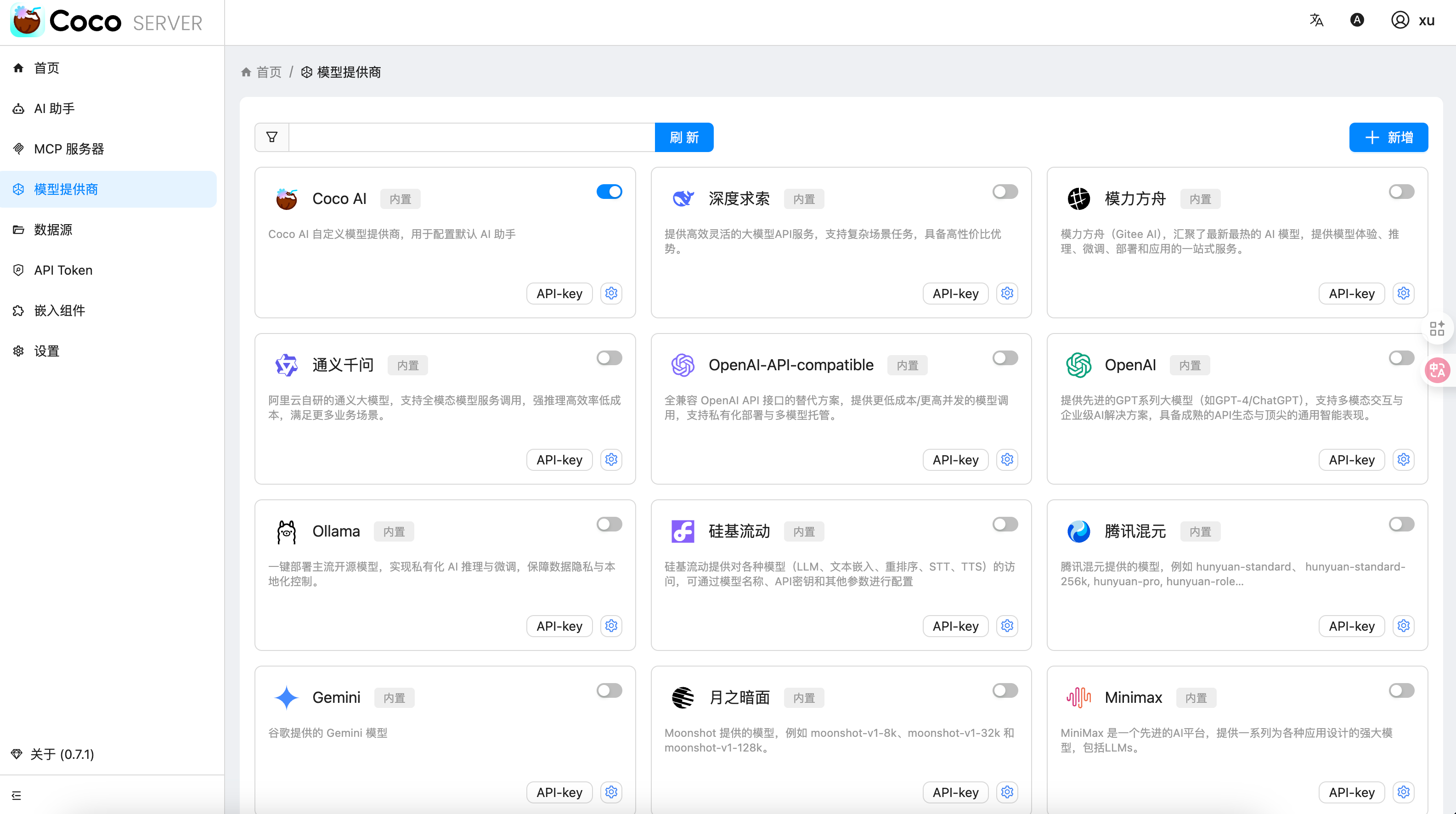 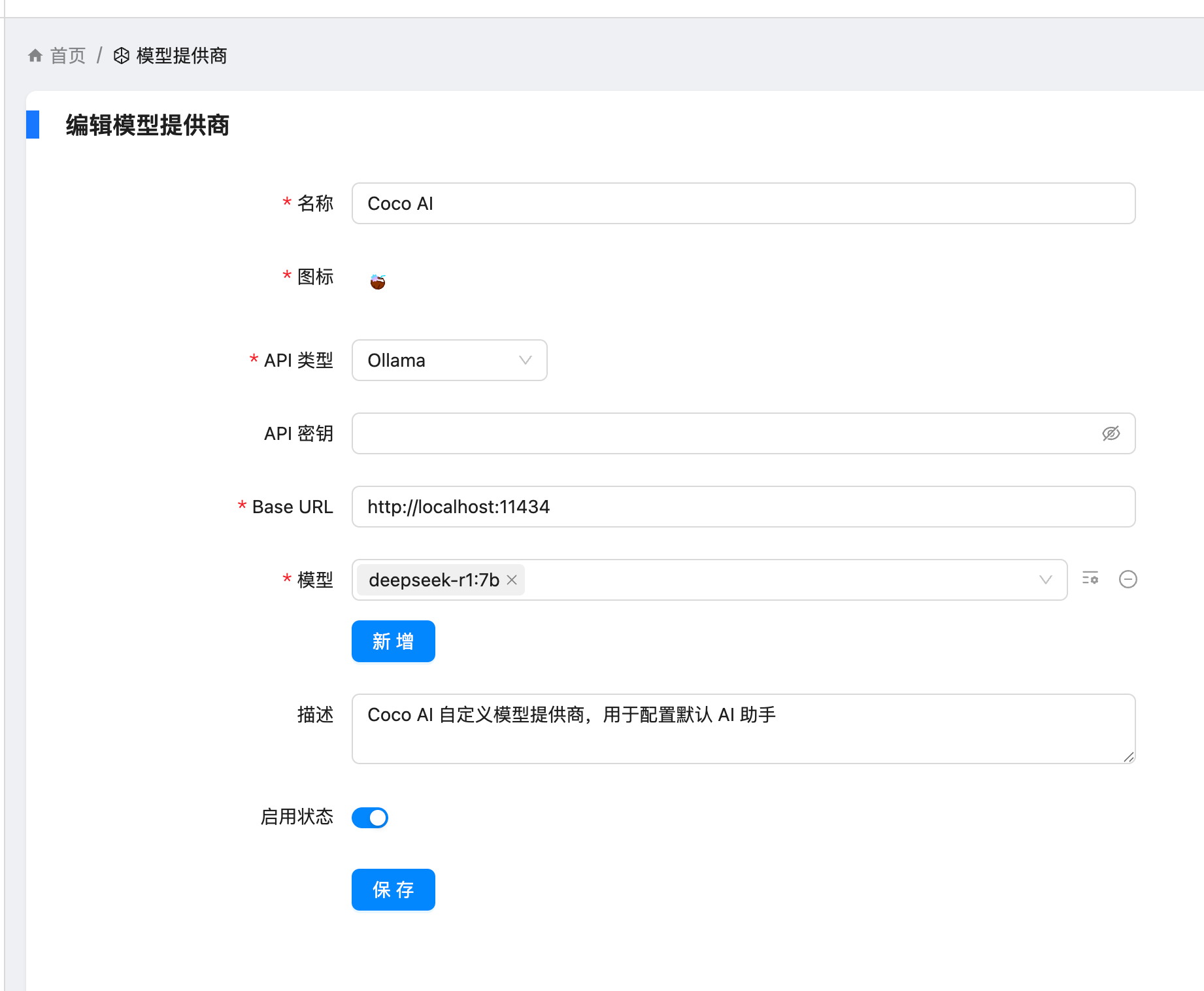 --- ### 三、数据源概览 Coco-AI 默认内置官方文档和 Hacker News 数据源,近期新增三类连接器: 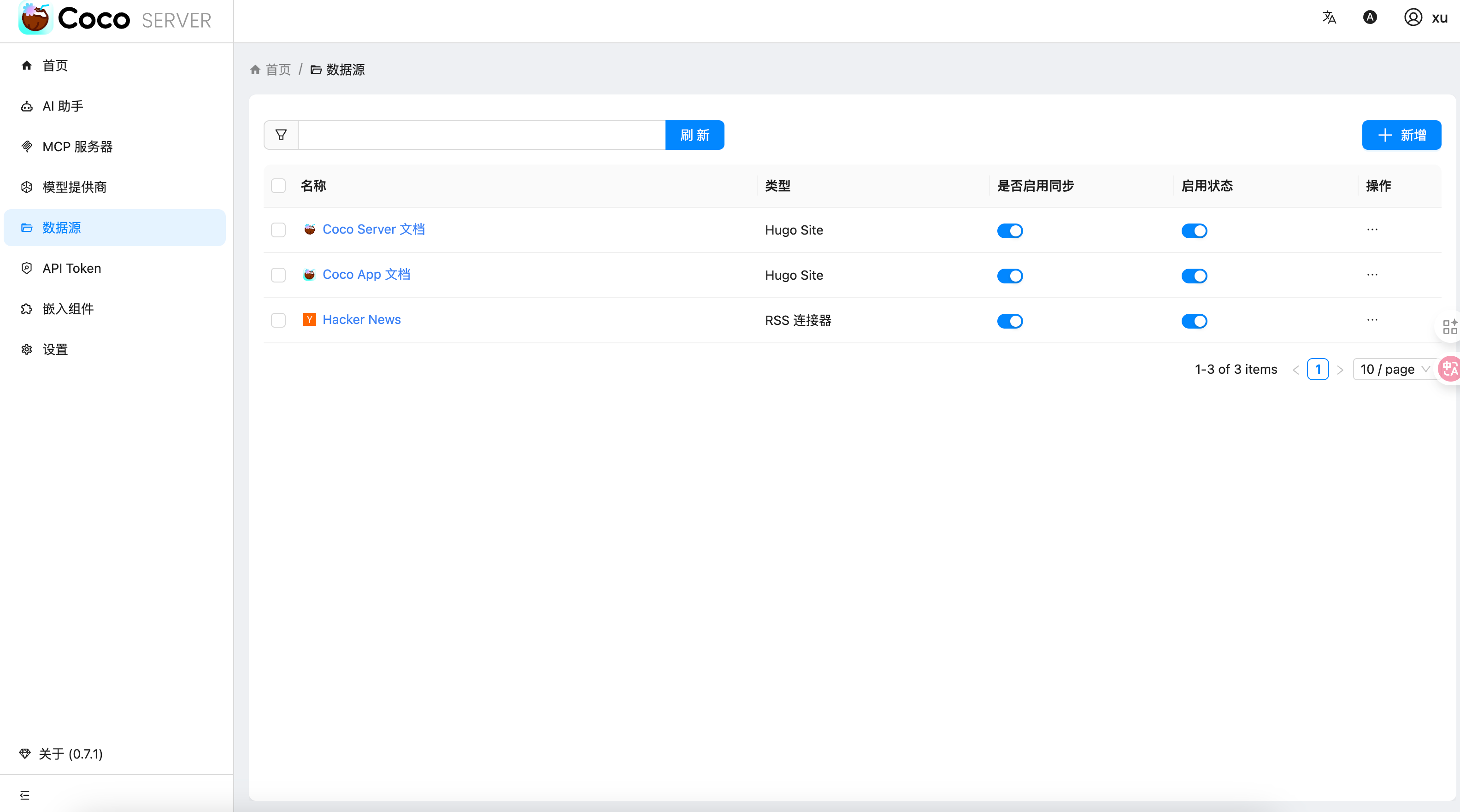 - **S3 连接器**(本篇重点) - 本地文件连接器 - RSS 连接器 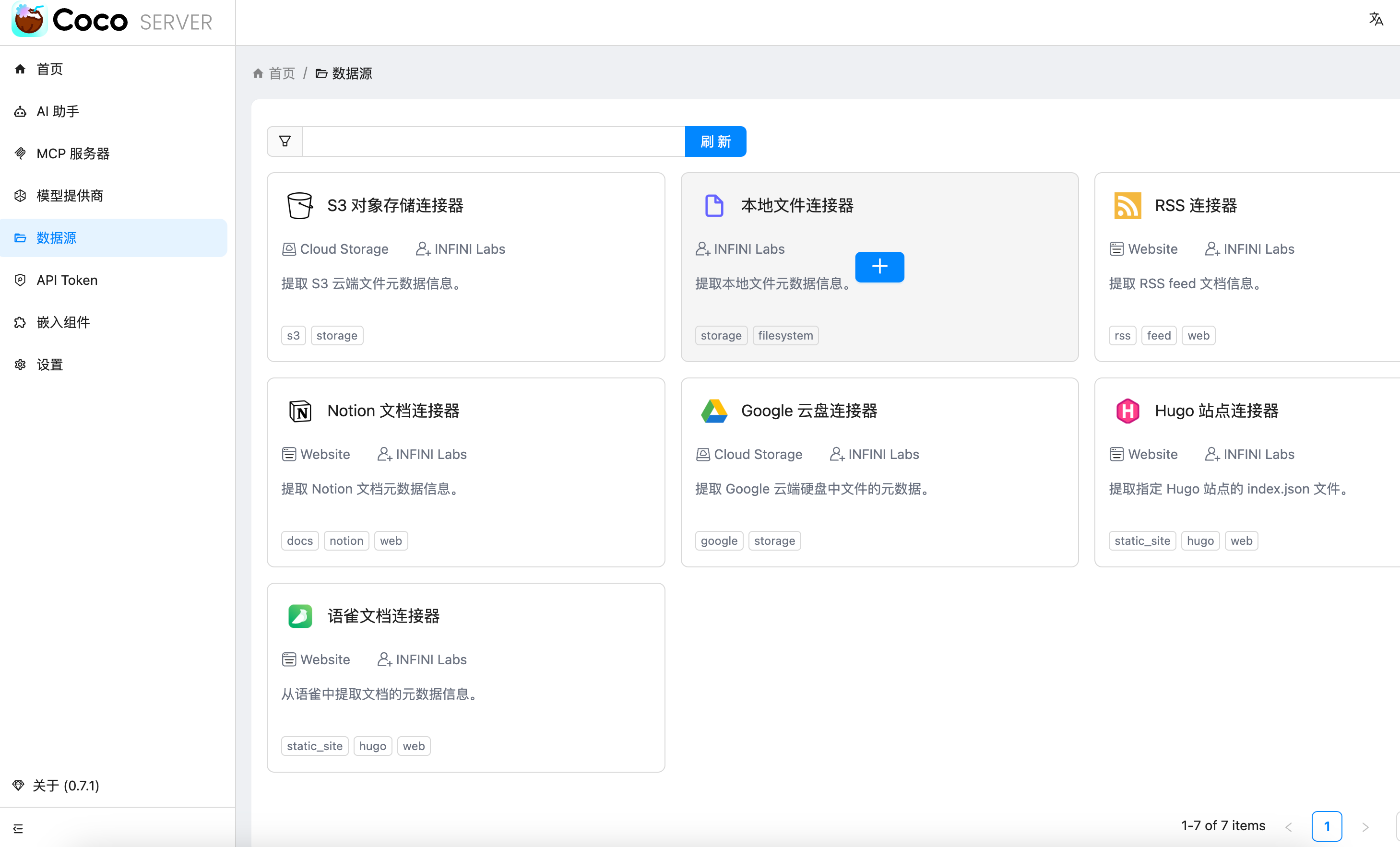 --- ### 四、接入 Amazon S3 1. **选择 S3 对象存储连接器** 填写 **Endpoint**(例:东京区 `s3.ap-northeast-1.amazonaws.com`)、**Bucket 名称**、**亚马逊云科技凭证(Access Key ID / Secret Access Key)**,刷新间隔建议保持 **1 分钟** 默认值。 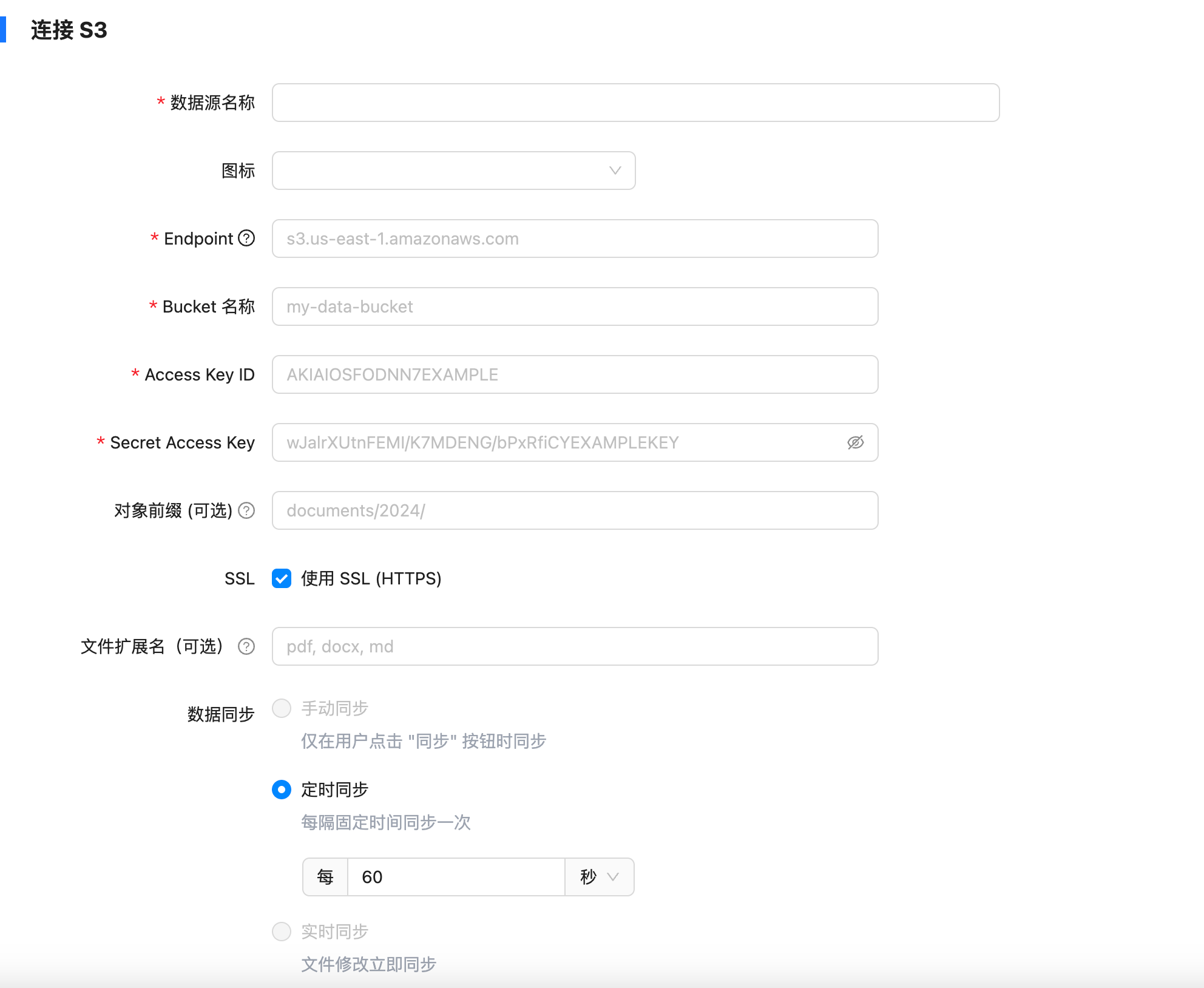 2. **获取亚马逊云科技访问凭证** - 登录 **亚马逊云科技 IAM 控制台** - 创建访问密钥(Access Key ID / Secret Access Key) - 为用户分配最小化 S3 访问权限(推荐遵循最小权限原则) 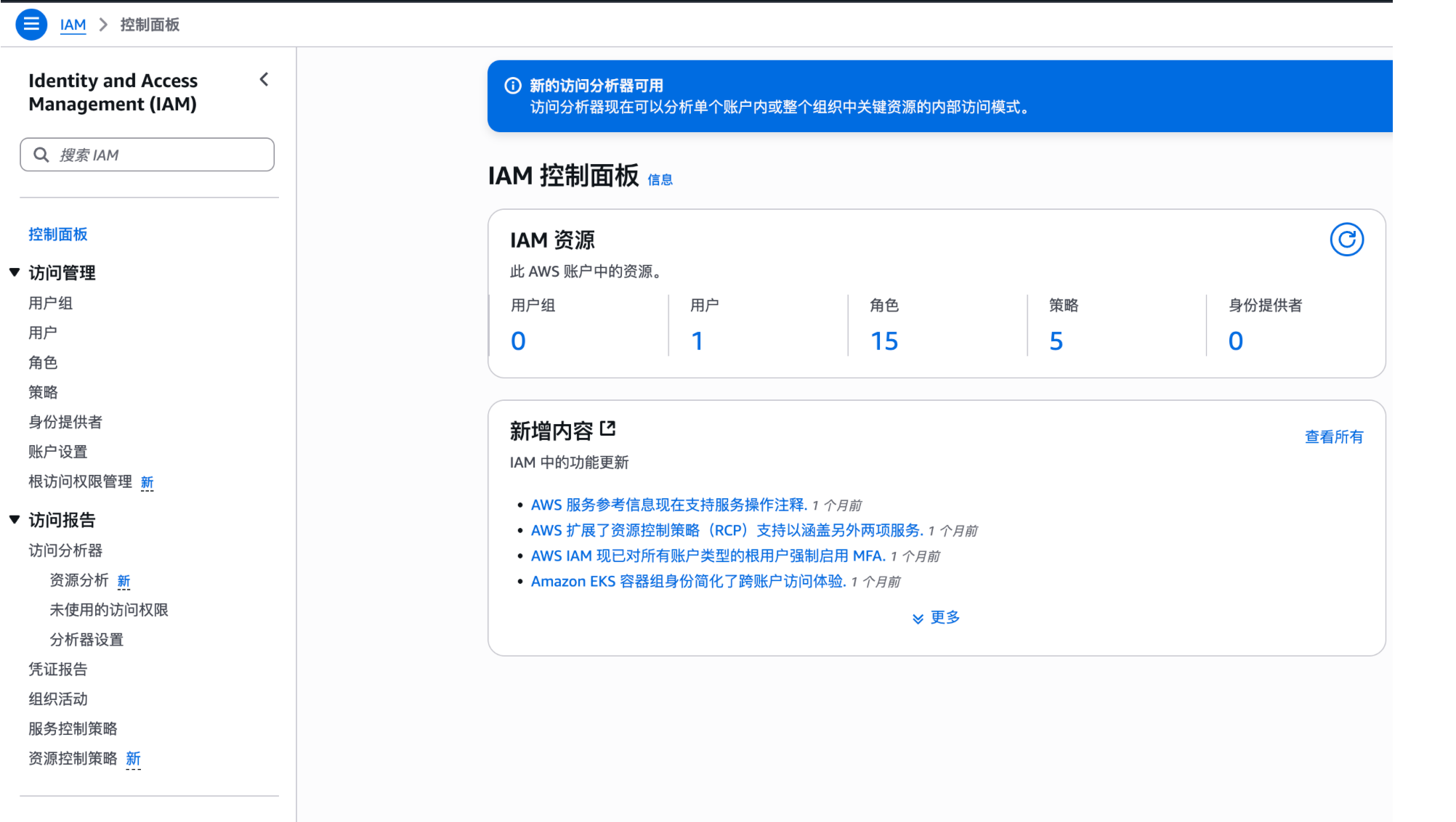 这里选择访问密钥 - 创建访问密钥,然后保存 Access Key ID / Secret Access Key 就好。 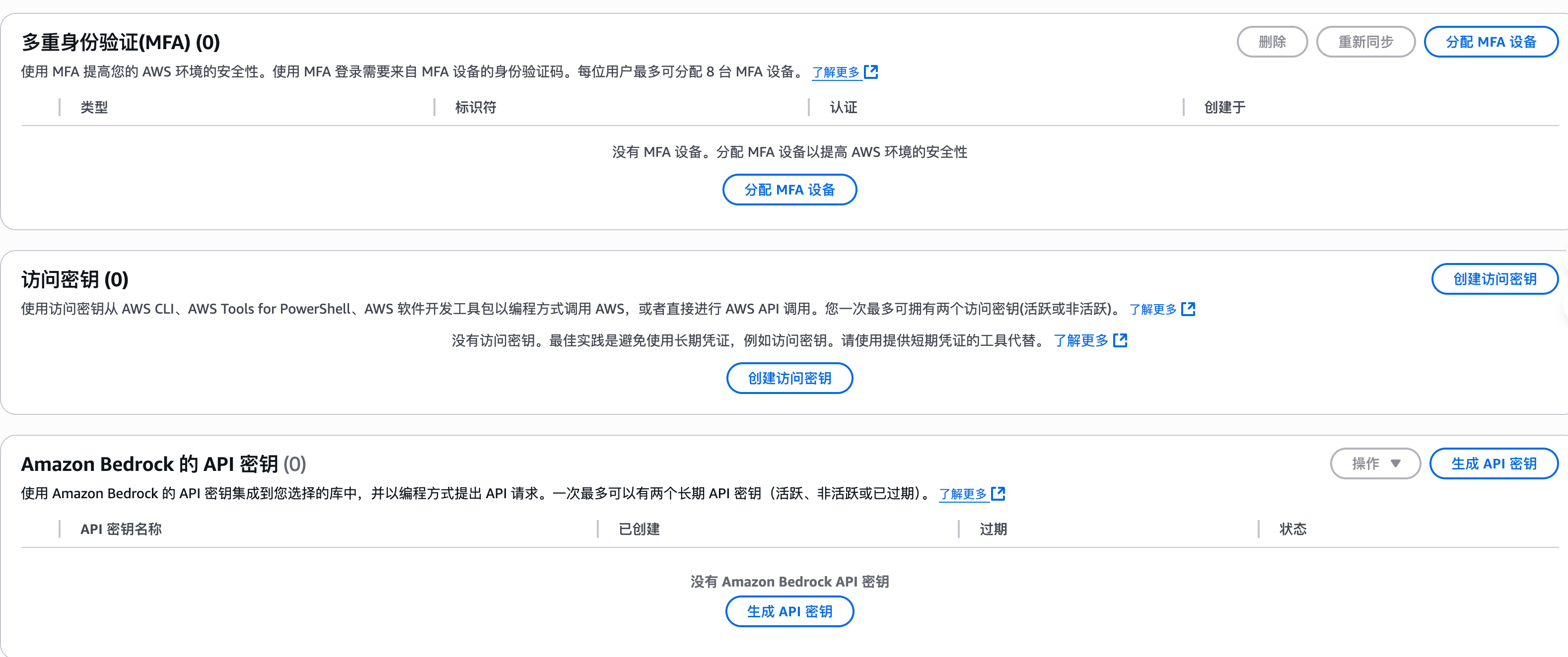 创建过程中会出现最佳实践提示,不影响后续配置,下载密钥即可使用。 其他的凭证方式虽然有 IAM Role 和 Role anywhere,但是我们这次不会用到。 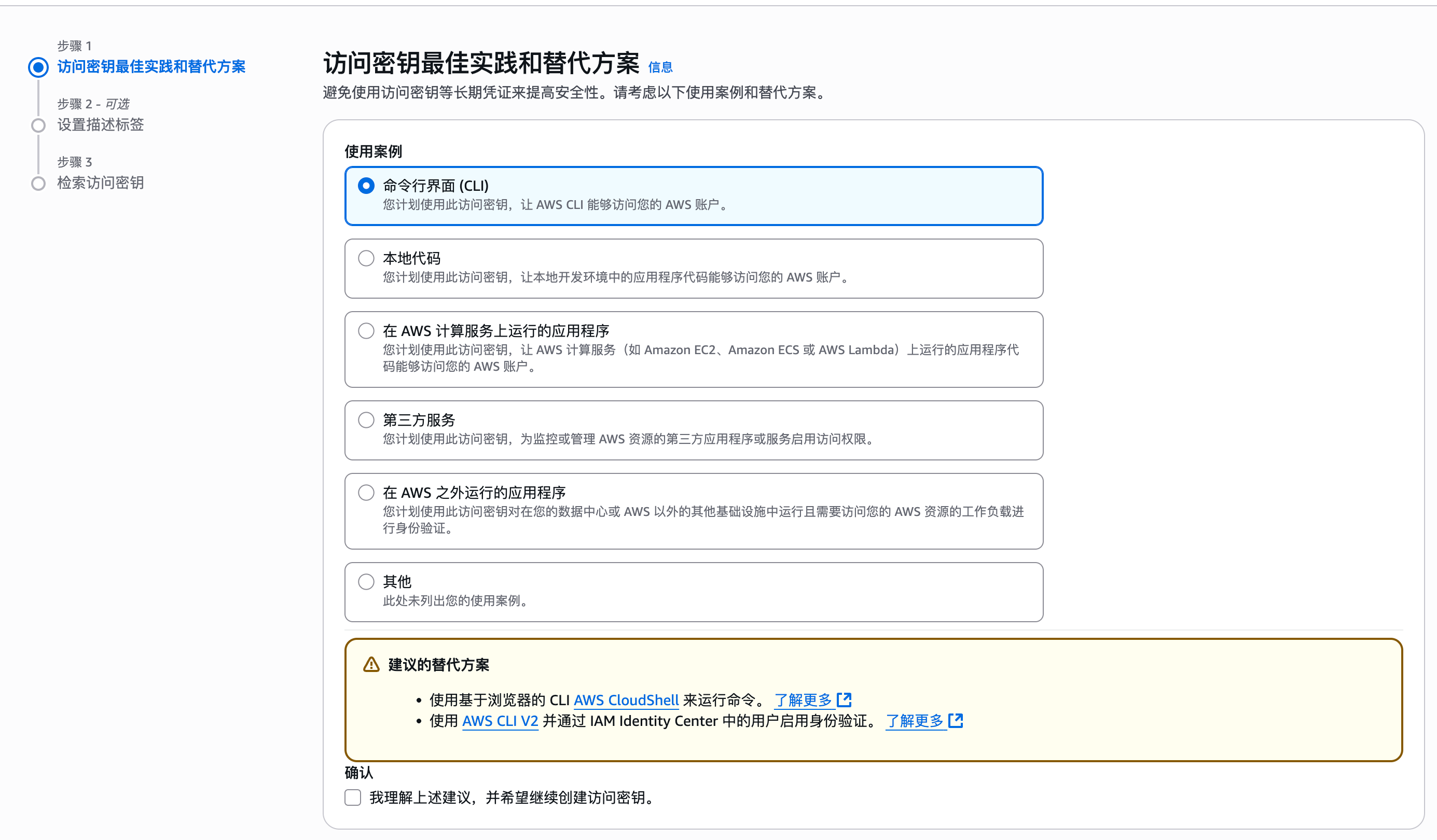 确保这个用户有访问 S3 的权限,如果是生产的环境的话,确保要采用最小权限原则来防止不必要的麻烦。如果你在存储桶上配置了对应桶策略也可以。 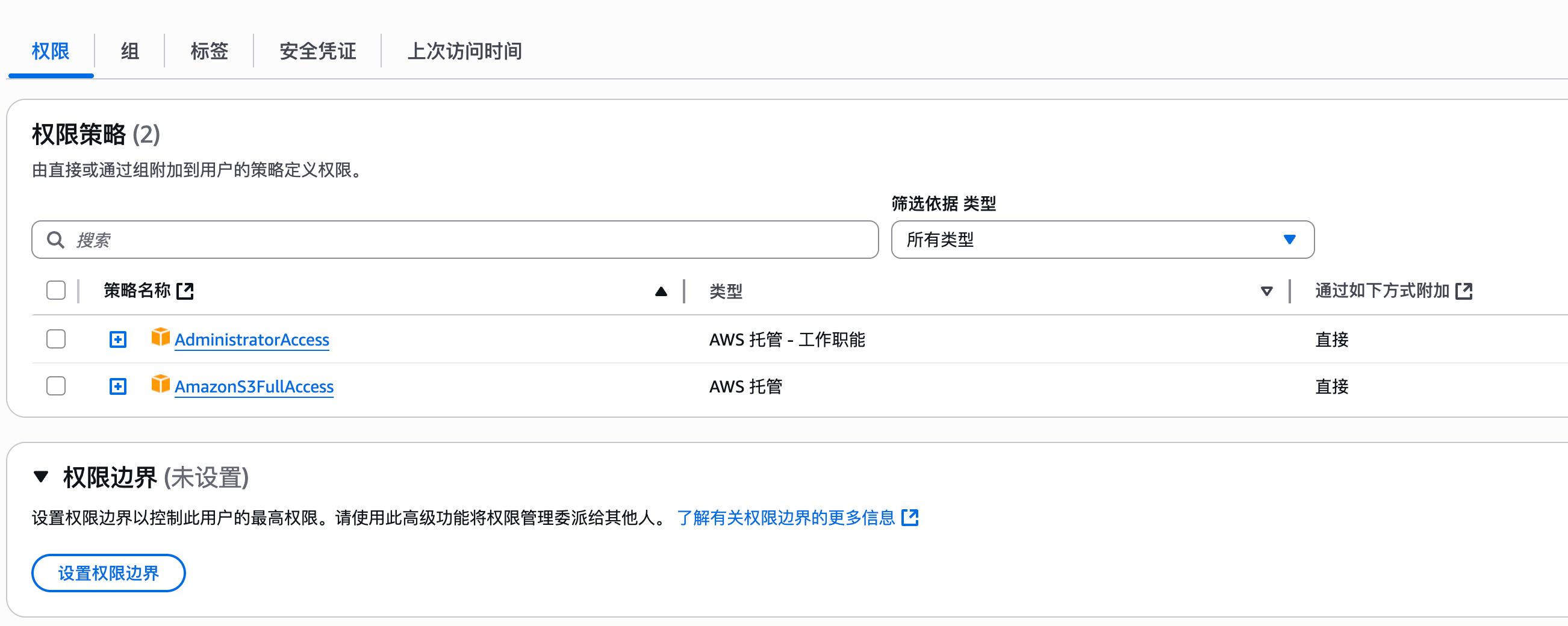 3. **对象前缀(Prefix)配置** 这个是我在 S3 上的对象存储,放了一些 markdown 文件上去。 还是这张图,我使用的是东京区的存储桶 dify233,所以 endpoint 是 s3.ap-northeast-1.amazonaws.com。  这里的对象前缀可以理解为目录,在 S3 设置之初会把所有文件夹的名称当作前缀加到文件名前面,所以也有 S3 是扁平化管理一说。 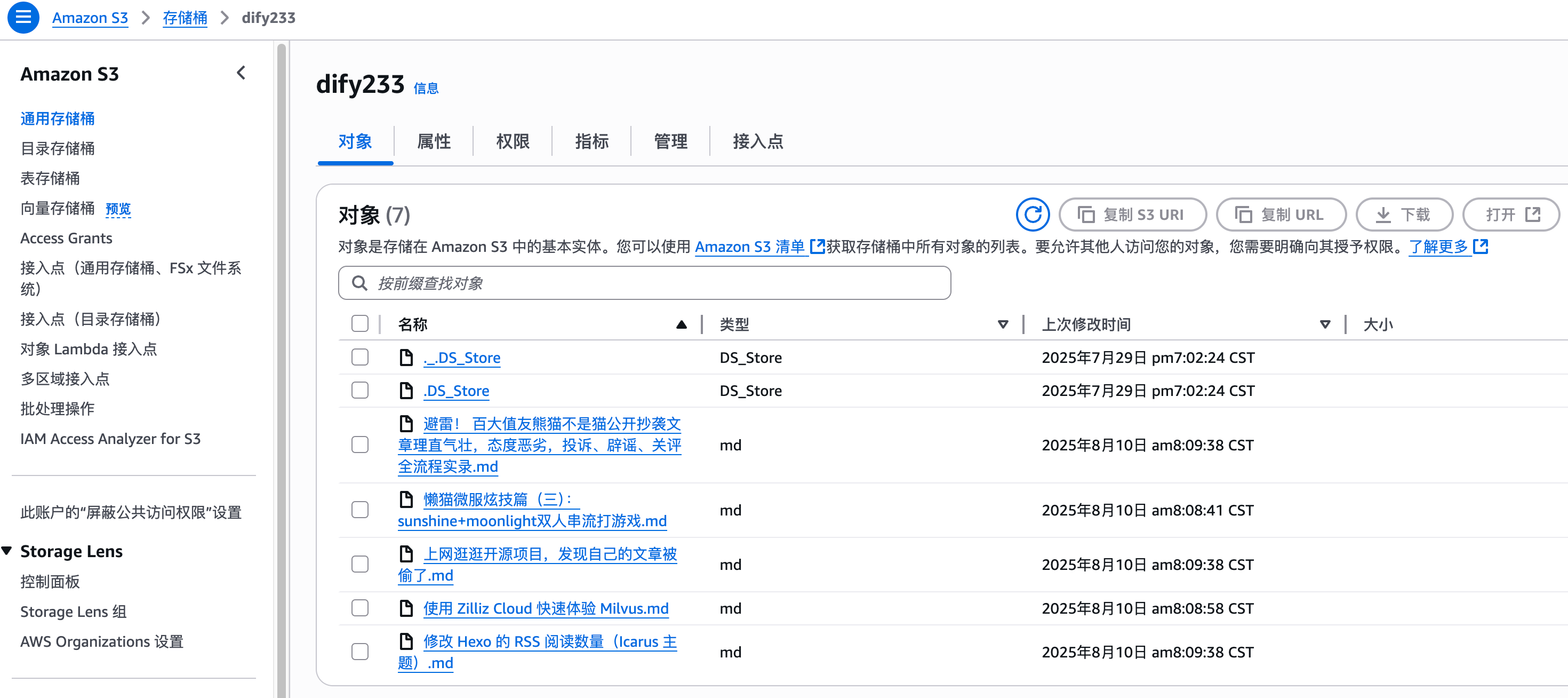 --- ### 五、集成效果 完成连接后,S3 中的 Markdown 文件可被 Coco-AI **实时索引与检索**,点击搜索结果即可跳转到 S3 公网访问链接,例如: ``` https://<bucket>.s3.<region>.amazonaws.com/<对象名> ``` 不仅支持标题关键词搜索,还可结合 LLM 实现**语义检索**,极大提升信息获取效率。 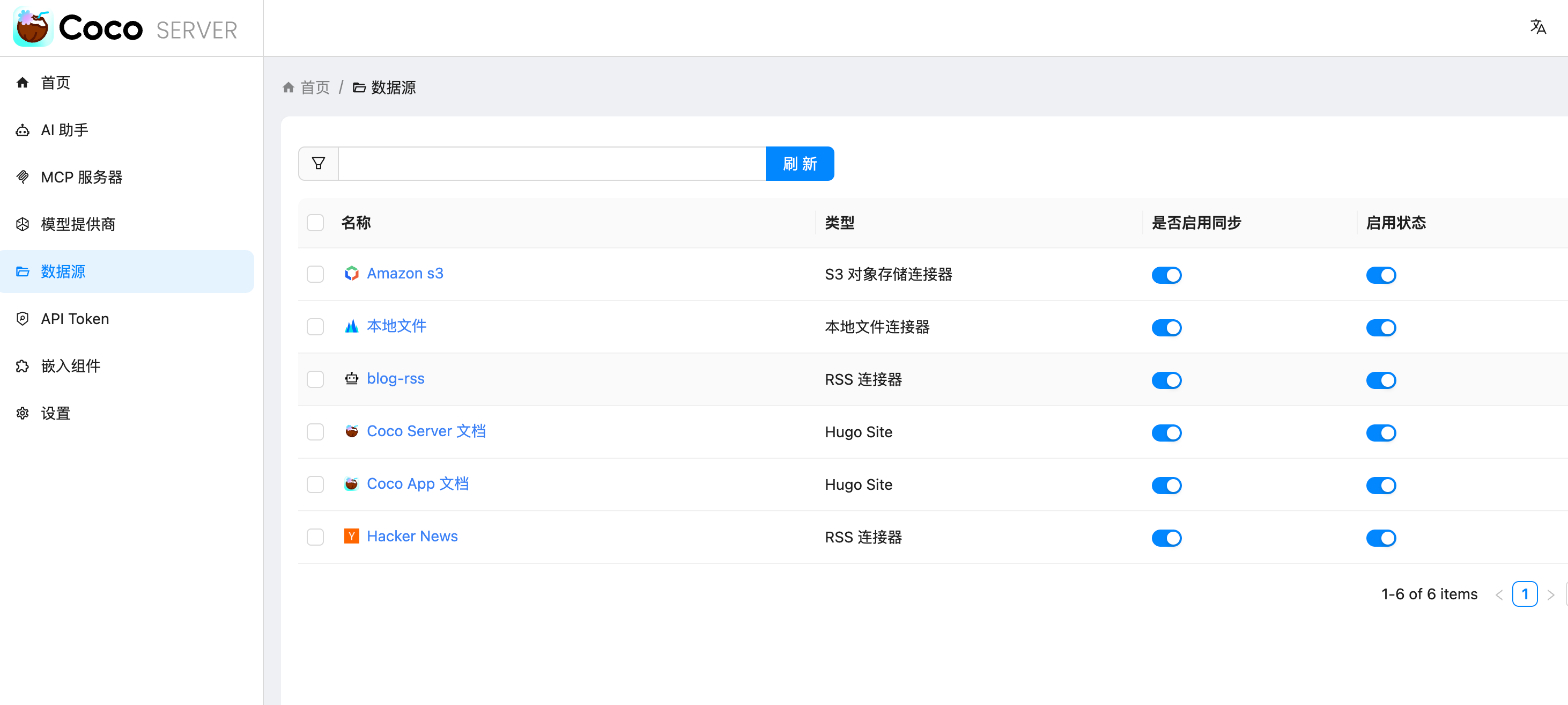 添加完成后可以看到我同时接入了 S3、本地文件和 RSS,我们这里主要开介绍关于 S3 的连接器。 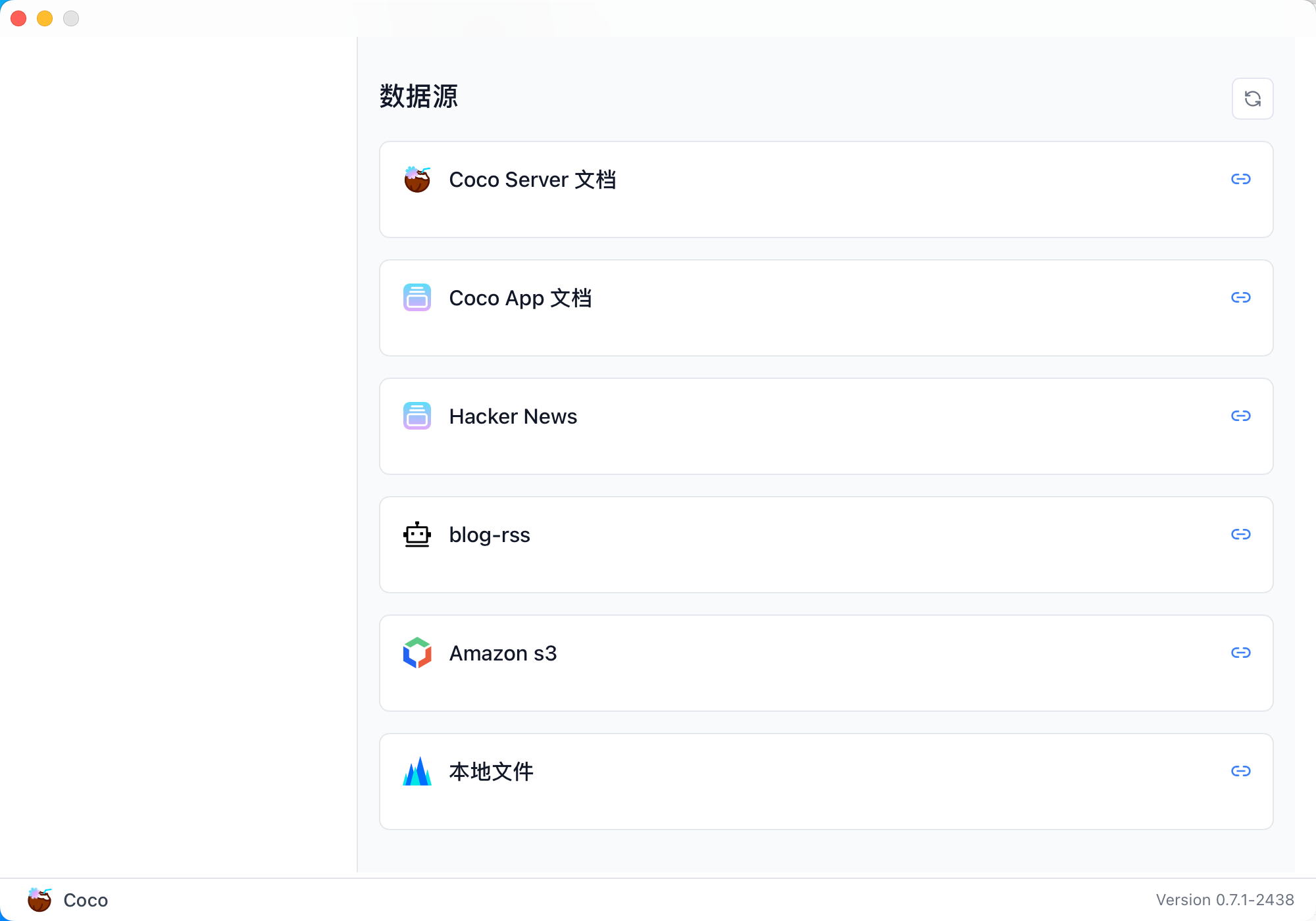 使用 Coco-AI 搜索时,能快速检索到 s3 中的 markdown 文件。 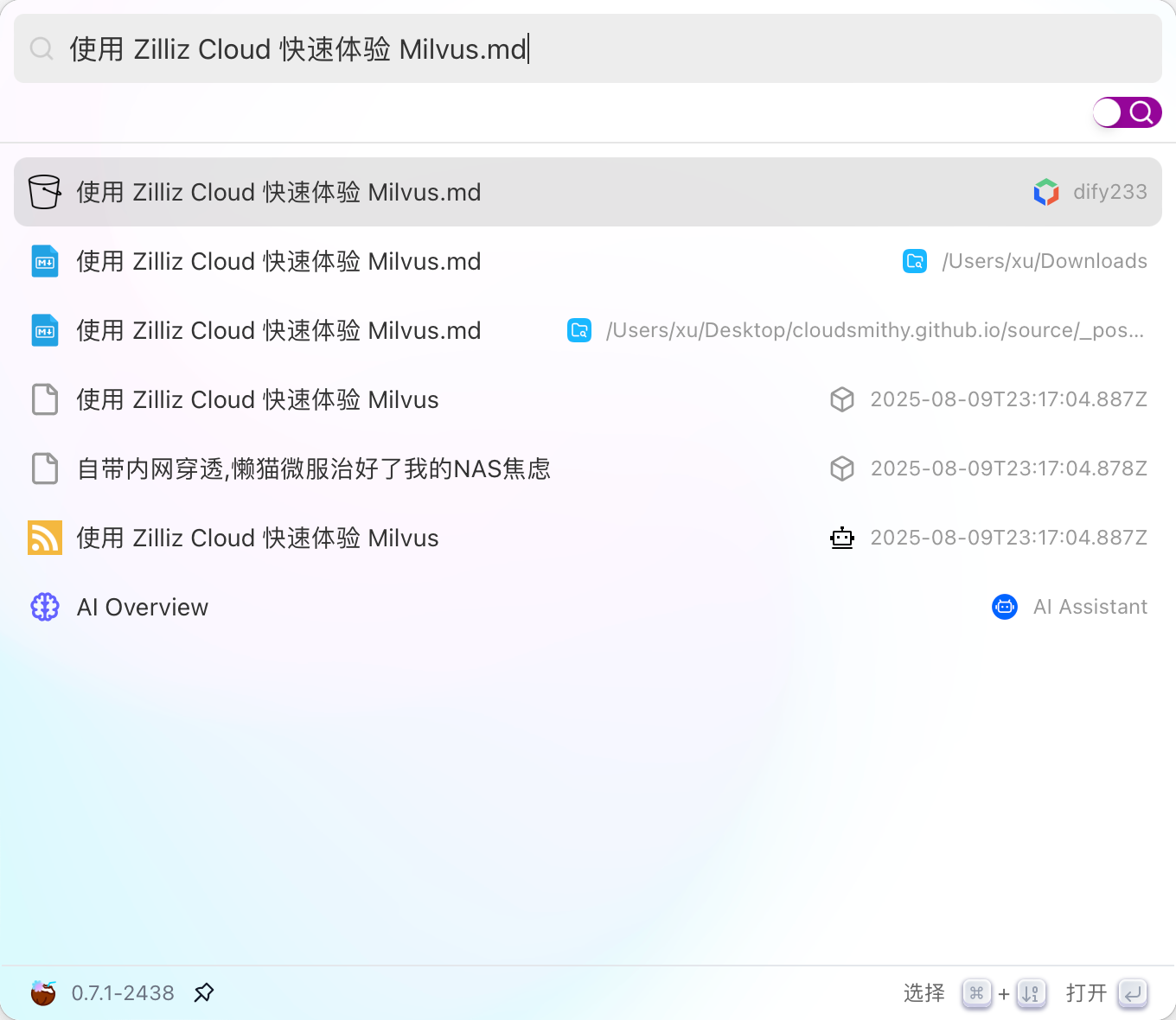 点击搜索结果可直接跳转到对应链接。 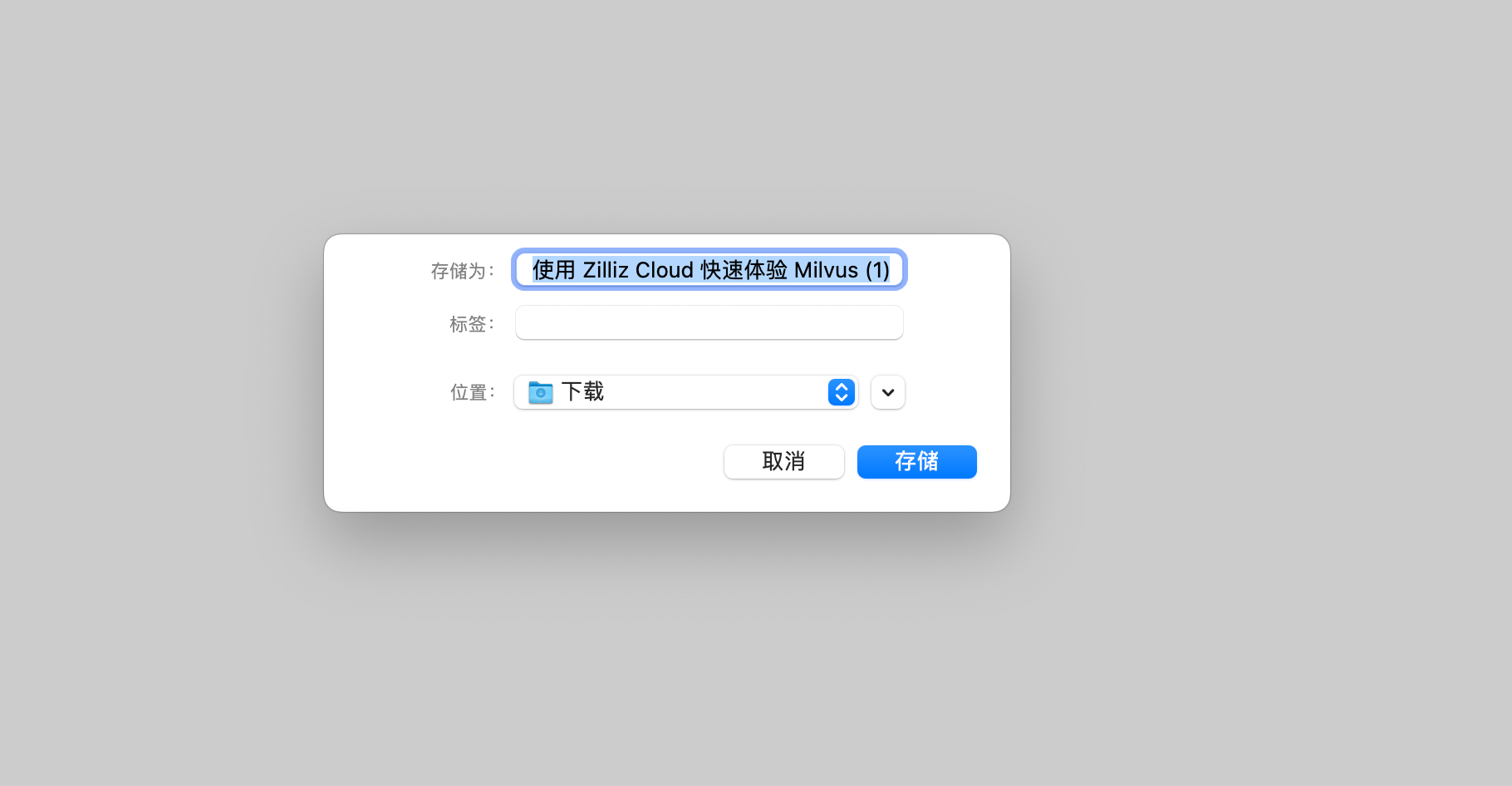 也支持把地址复制出来:https://dify233.s3.ap-northeast-1.amazonaws.com/对象名,其实就是S3的https 链接了。  ### 六、适用场景 - **企业内部知识库**:研发文档、政策文件、培训资料统一存放于 S3 - **个人云端资料管理**:博客、项目资料随时调用 - **跨团队协作**:多地访问,实时共享 通过 **Coco-AI S3 连接器**,只需几步,即可让 ** Amazon S3** 成为高效智能检索系统的云端引擎。 无论是个人开发者,还是大型企业团队,都能快速构建**跨云端、本地、第三方数据源的统一知识平台**。
Coco-AI 服务端文件系统检索
随着企业和个人数据量的激增,如何高效管理与搜索文件资料,已成为提升工作效率的关键。 **Coco-AI** 新增的 **本地文件连接器**,可以直接接入服务端文件系统,实现秒级搜索、即时访问,让服务器上的文件像本地文档一样触手可及。 本文将介绍如何通过 **Docker 快速部署 Coco Server**,并配置本地文件连接器,实现服务端文件的智能检索。 ### 一、快速部署 Coco Server Coco Server 是连接器功能的核心组件,部署完成后即可接入本地文件、RSS 等多种数据源。 生产环境建议使用持久化存储,避免数据丢失。 在应用商店中下载 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai --- ### 二、配置 AI 模型 创建用户后,我选择 **Ollama** 作为模型提供商: - **地址**:`http://localhost:11434` - **模型**:`deepseek-r1:7b`  在「模型提供商」界面可以看到默认启用的 **Coco AI**,它会直接调用已配置的 Ollama,也支持任何兼容 OpenAI API 协议的 LLM。   --- ### 三、数据源概览 Coco-AI 默认内置了 **官方文档** 和 **Hacker News** 数据源,并在近期新增:  - **本地文件连接器**(本文重点) - RSS 连接器 - S3 连接器  --- ### 四、配置本地文件连接器 本地连接器的配置非常简单,只需: 1. 选择文件路径 2. 设置需要索引的文件后缀 3. 等待系统从 **localFS** 中智能提取内容 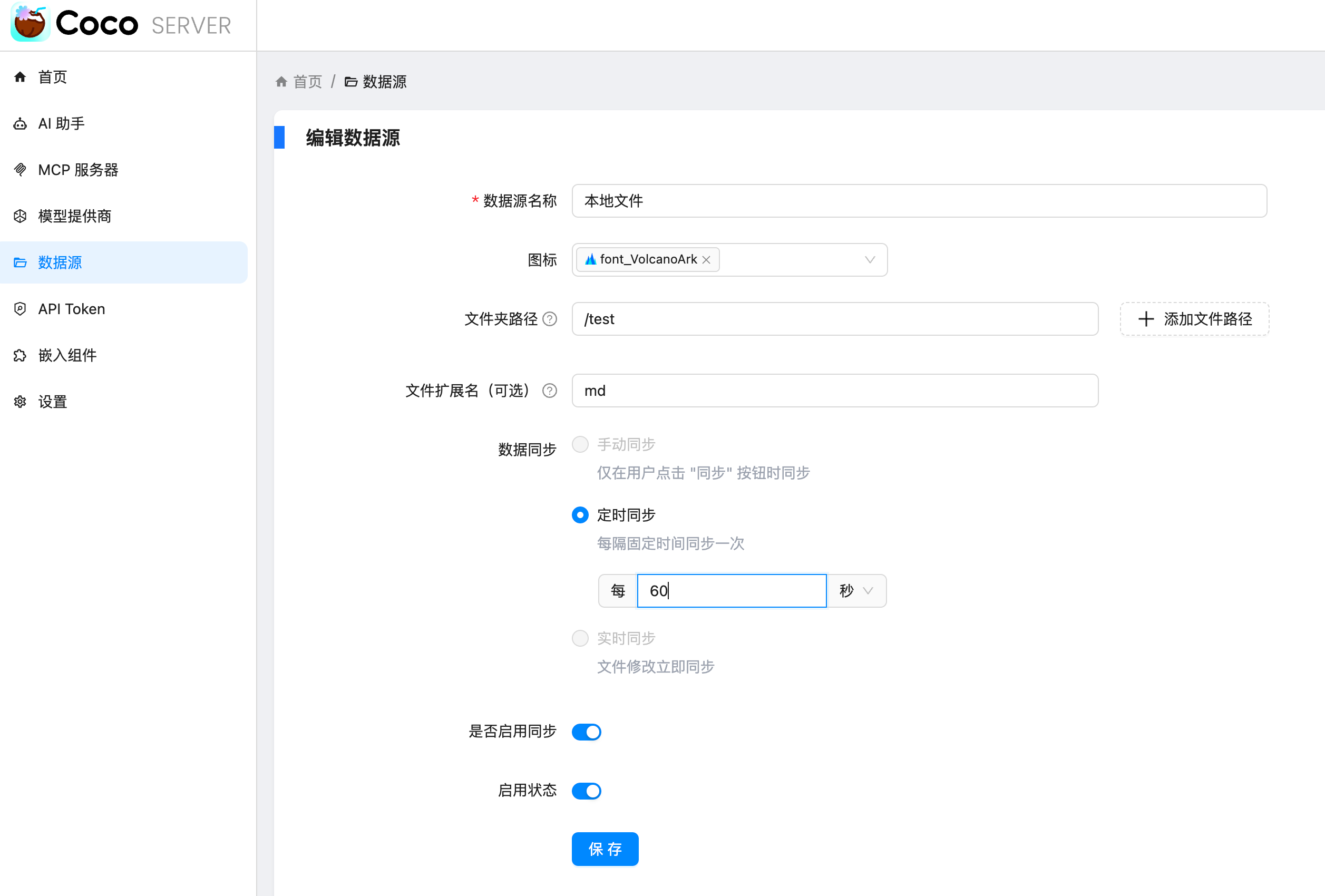 ### 使用 Docker 时的注意事项 如果通过 Docker 部署 Coco Server,需要将本地目录映射到容器内,因为连接器读取的是**容器内部路径**,而非主机路径。 当然,也可以像我这样直接在 **Orbstack** 等容器平台上传文件,省去目录映射的步骤。 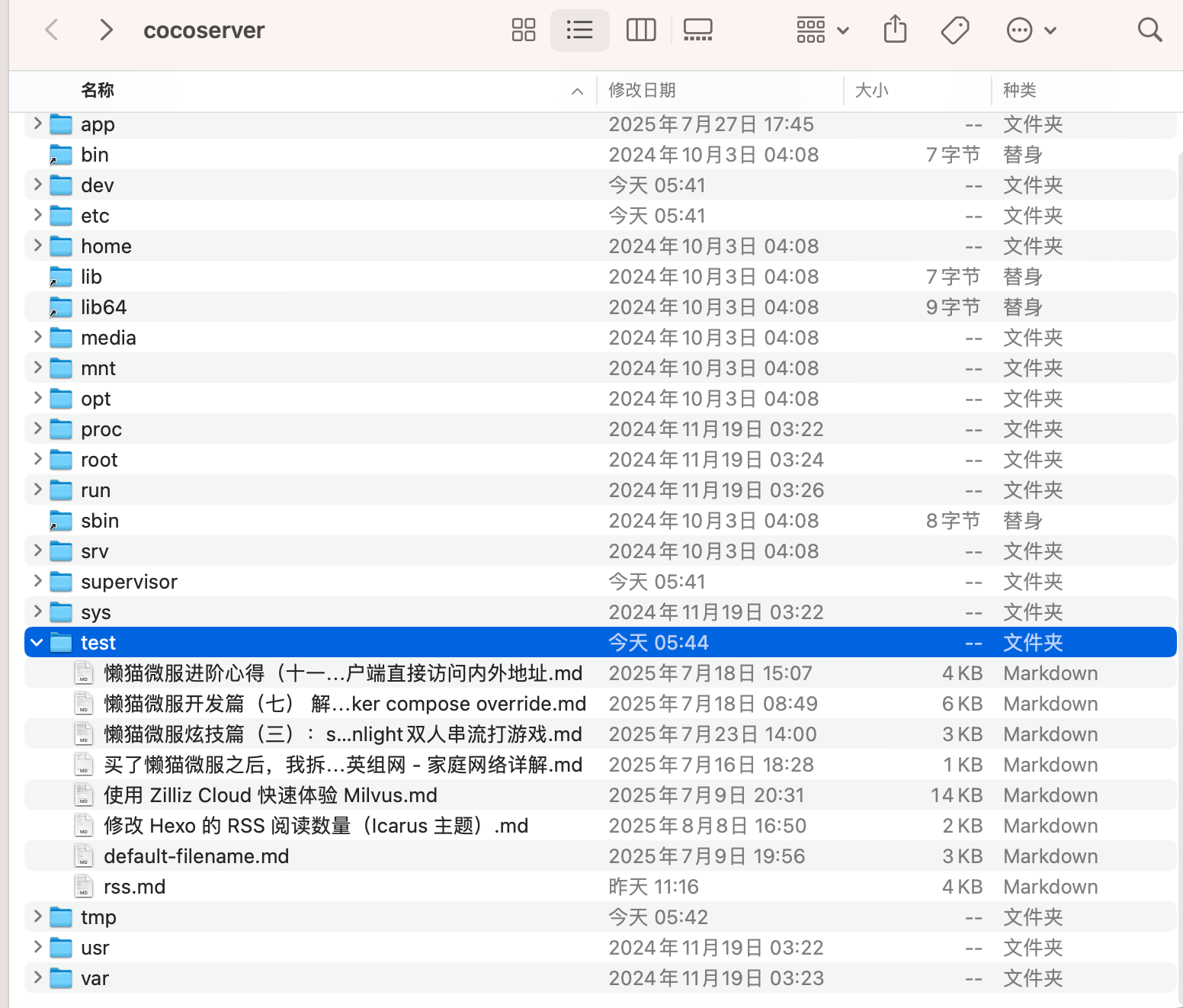 添加完成后,可以在连接器列表中看到新建的服务端本地文件连接器:  ### 五、在 Coco App 中查看与检索 登录 **Coco App** 后,可以看到刚刚添加的 **本地文件** 数据源,并直接进行搜索。  这是刚才添加的服务端文件的搜索结果: 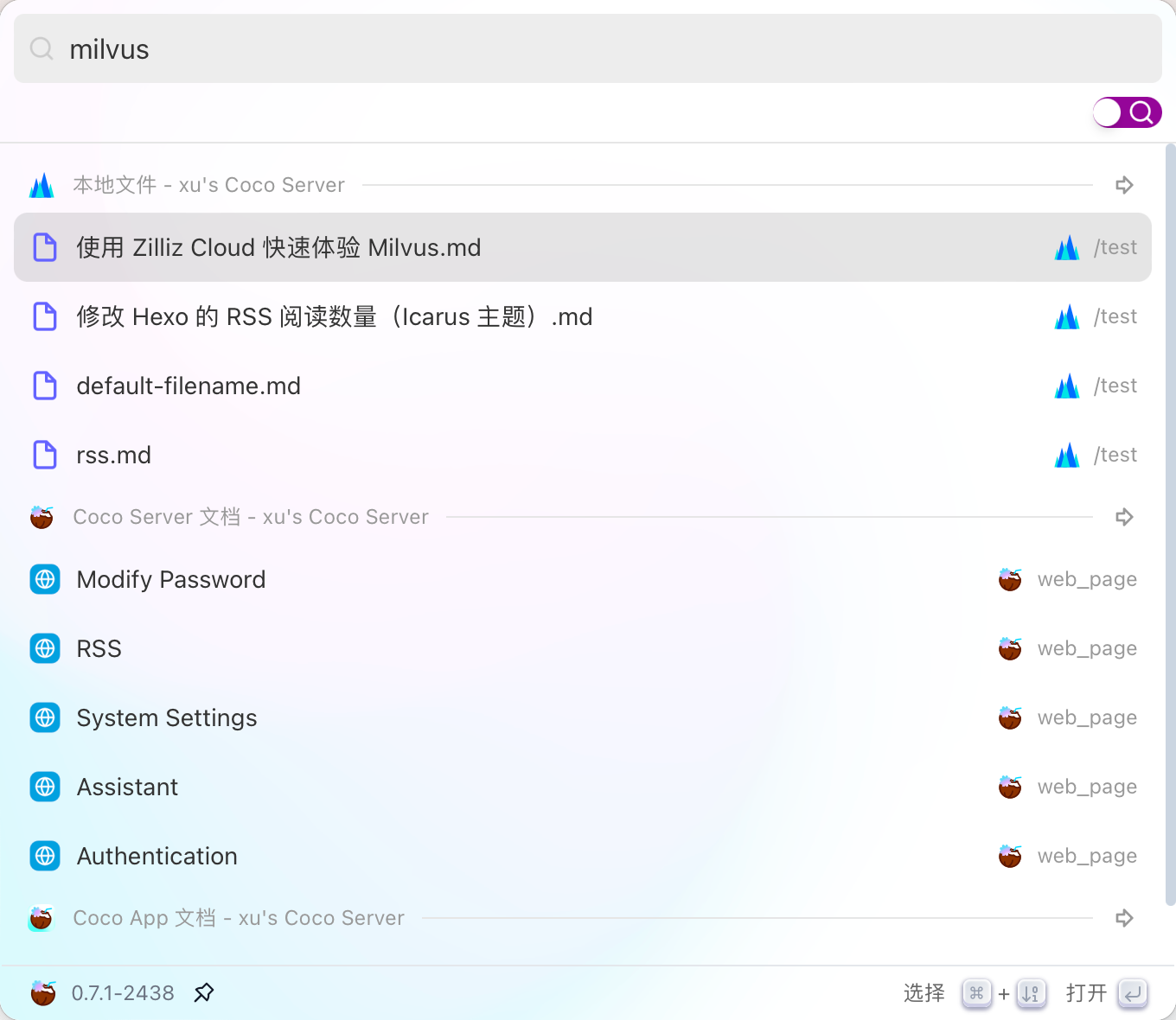 此外,Coco-AI 还支持客户端本地文件搜索,但本文重点展示的是**服务端文件检索**功能:  ### 结尾 通过本地文件连接器,Coco-AI 不仅能帮助你把服务端的文档、日志、配置文件快速接入 AI 检索,还能结合多数据源进行统一搜索,大幅减少人工查找和信息碎片化的时间成本。 未来你还可以将 本地文件检索 与 RSS、API、数据库连接器组合使用,让企业级信息管理更智能、更实时、更高效。 如果你也想让服务器里的海量资料触手可及,不妨部署一个试试——也许你的检索方式,从今天就会不一样。
从零到用:RSS 接入 Coco-AI 实战指南
最近 Coco-AI 上线了几个新功能:**S3 连接器、本地文件连接器、RSS 连接器**。我会逐一介绍,本篇先重点讲 RSS 连接器的接入方法。 ### 一、安装 Coco Server 在应用商店中下载 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai ### 二、模型配置 创建完用户后,我直接设置了 **Ollama** 作为模型提供商: - 地址:`http://localhost:11434` - 模型:`deepseek-r1:7b`  在「模型提供商」界面可以看到默认开启的 **Coco AI**,它会直接调用我配置的 Ollama,也支持其他兼容 OpenAI API 的 LLM。   --- ### 三、数据源概览 Coco-AI 默认植入了官方文档和 Hacker News 数据源,这次新增了三类连接器:  - S3 连接器 - 本地文件连接器 - RSS 连接器(本篇重点)  --- ### 四、添加 RSS 连接器 1. 选择 **RSS 连接器** 2. 输入 RSS 地址(这里我用的是我的博客): ``` https://airag.click/atom.xml ``` 3. 刷新时间设为 **1 分钟**(默认即可) 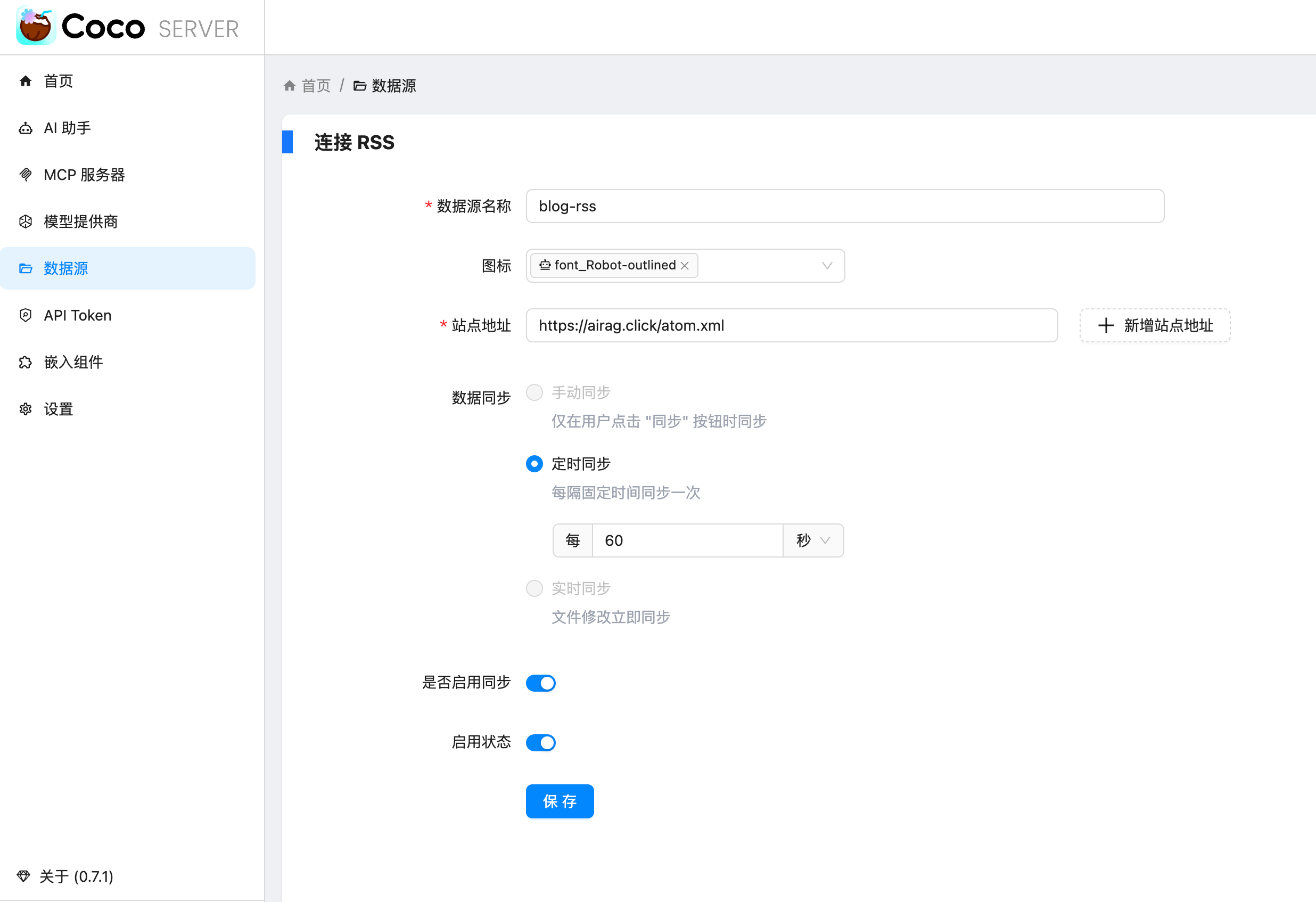 添加完成后可以看到我同时接入了 S3、本地文件和 RSS:  ### 五、小插曲:RSS 条目数量限制 一开始我发现 Coco-AI 只能显示 **最近 20 条**,以为是 Coco Server 的限制,后来群友提醒才发现是 **RSS 服务端设置**的问题。 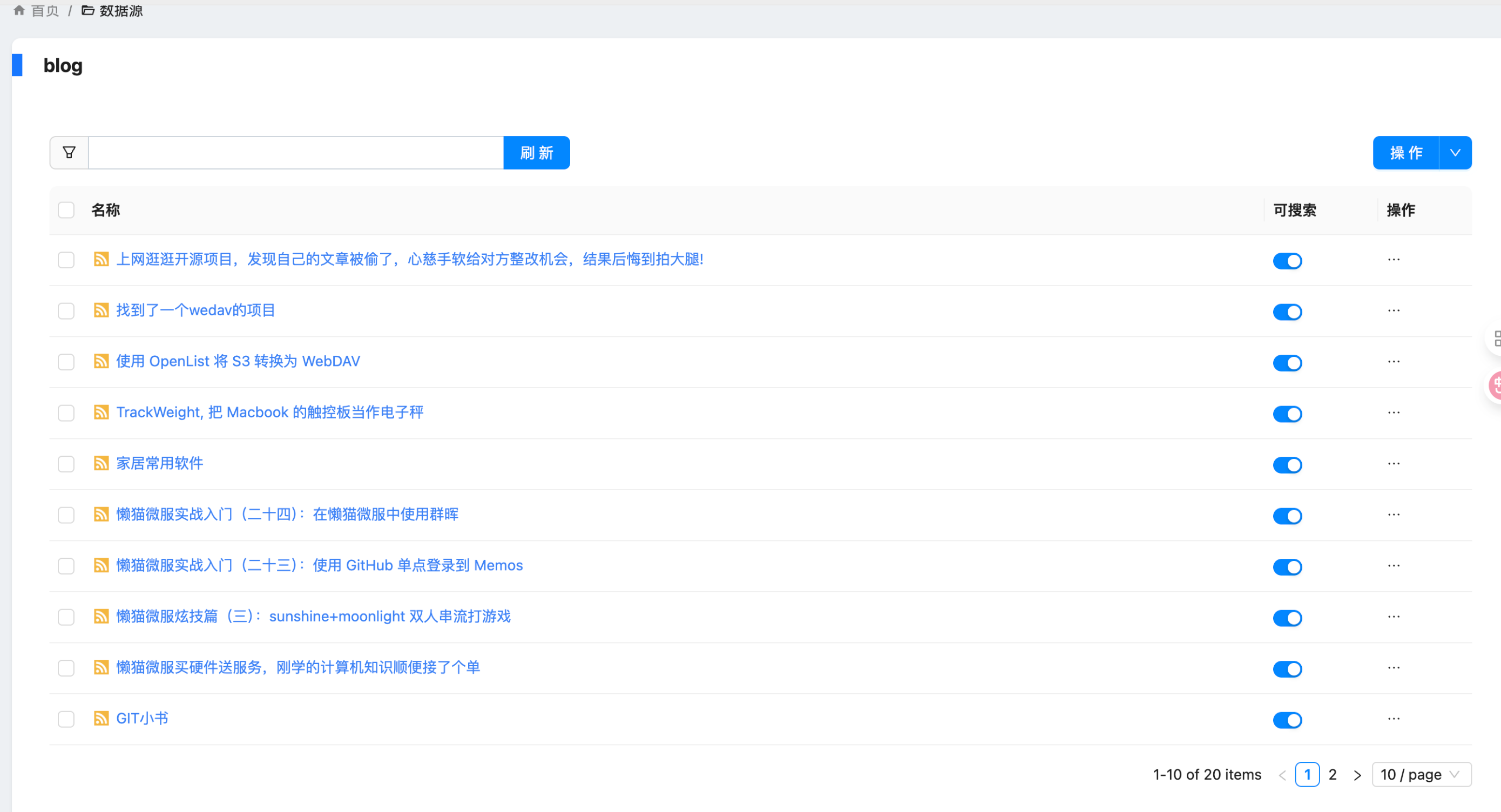 在博客服务端调整配置后,RSS 就能显示 **全部文章** 了。虽然很多 RSS 只显示最近内容,但其实可以通过配置让它输出完整数据。 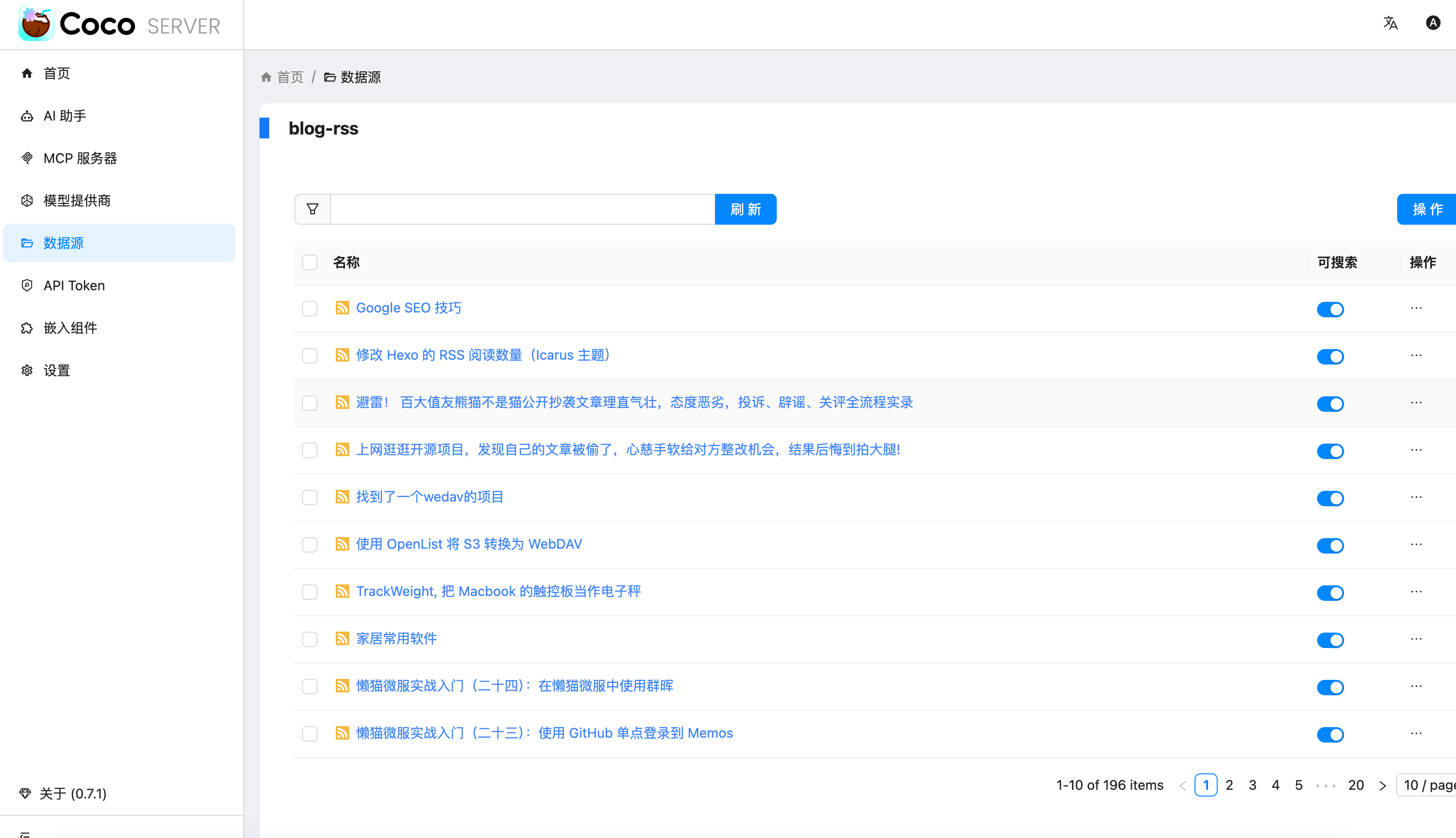 --- ### 六、在 Coco App 中查看数据源 登录 Coco App 后,可以看到刚才添加的 S3、本地文件和 RSS 数据源:  --- ### 七、搜索效果 使用 Coco-AI 搜索时,能快速检索到 RSS 中的内容,效果比博客自带的好很多: 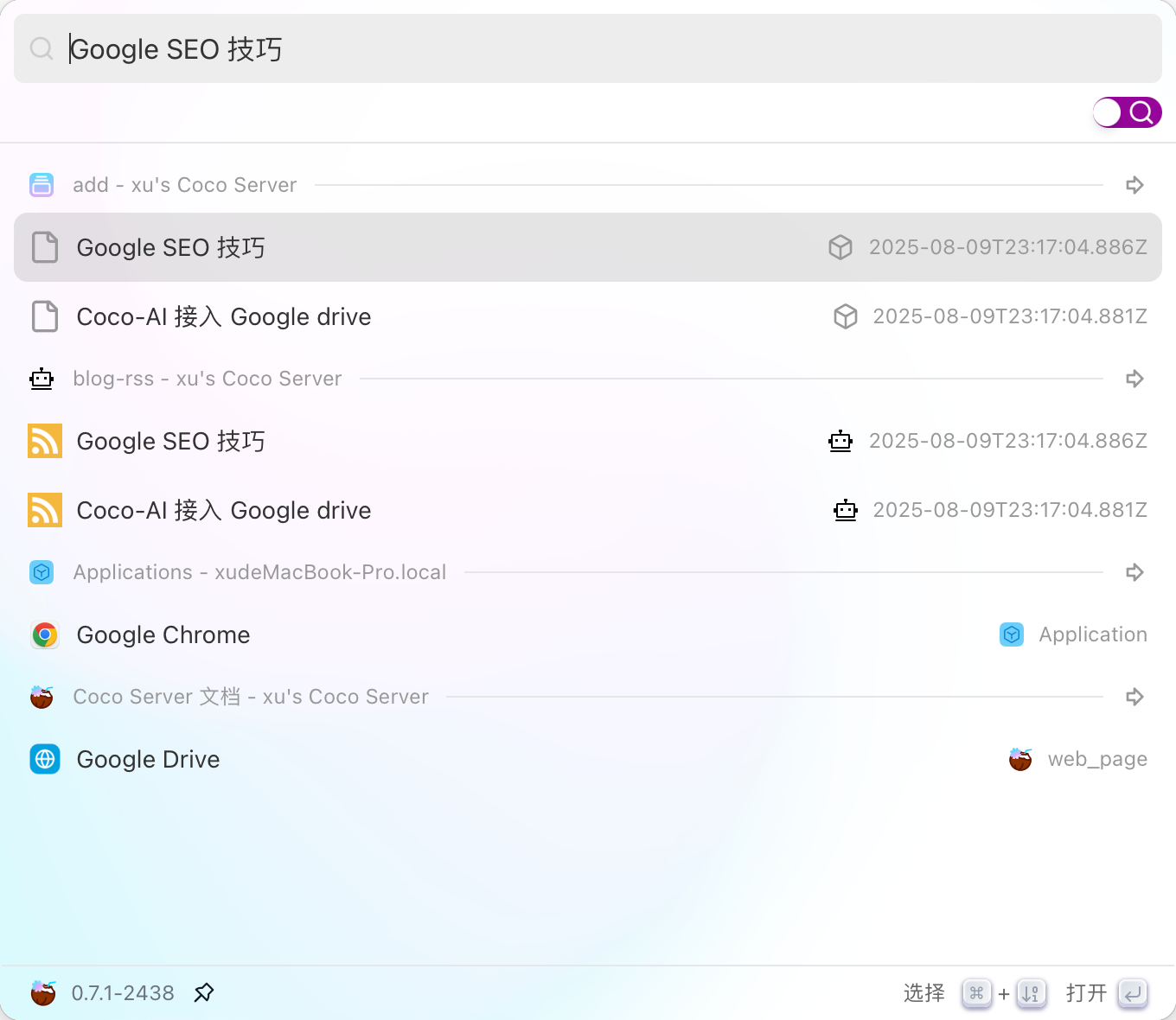 点击搜索结果可直接跳转到博客文章。我用的是 **Hexo 主题**,其他 RSS 源也一样适用。 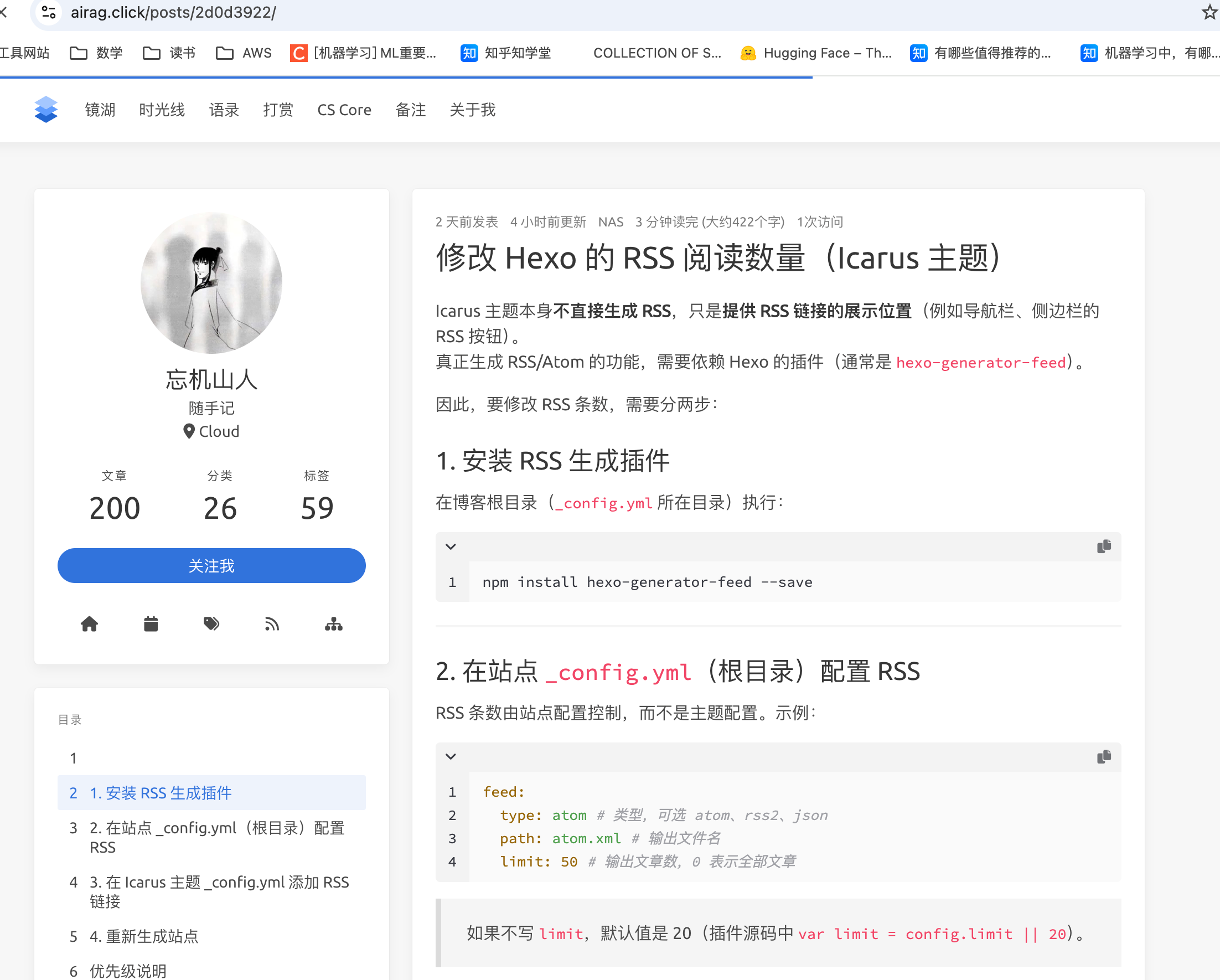 ### 总结 通过 RSS 连接器,Coco-AI 可以实时抓取和索引博客内容,并与本地文件、S3 数据等统一搜索,非常适合做多源聚合知识库。 如果 RSS 输出有限,可以调整博客端的 RSS 配置,让它输出更多历史内容,发挥 Coco-AI 检索的最大价值。
打造智能语料库:通过Coco AI Server 实现 Notion 笔记
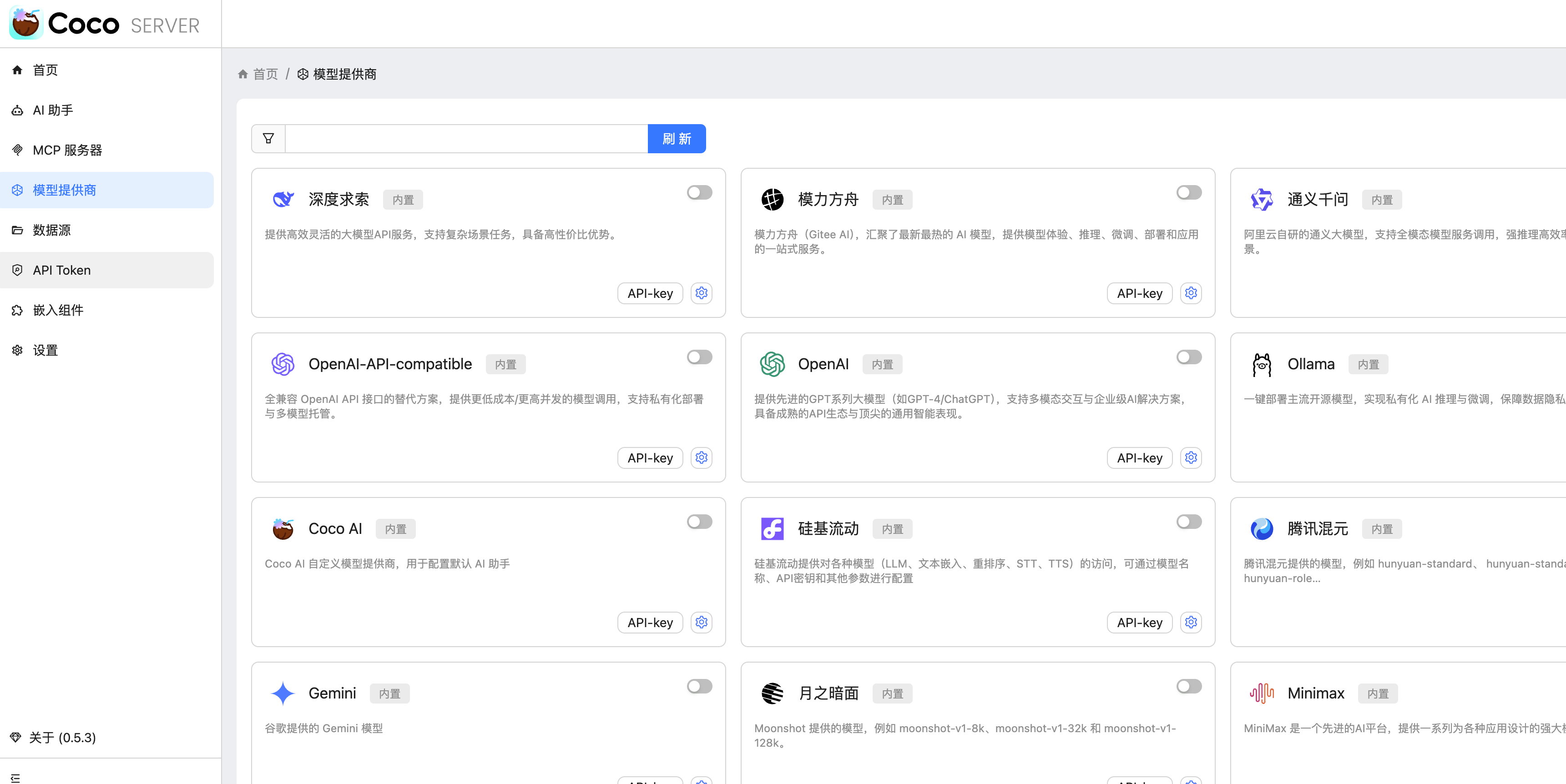
## CoCo Server 部署 RAG,使用 Notion 作为语料库(上) https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai 1. 启动 Easysearch,这里把 Easysearch 作为语料库,把 notion 的素材存在 Easysearch 2. 启动 ollama,使用 LLM 进行推理 3. 启动 Coco Server,端口在 9000 <!-- more -->  Coco App 连接 Sever,输入输入 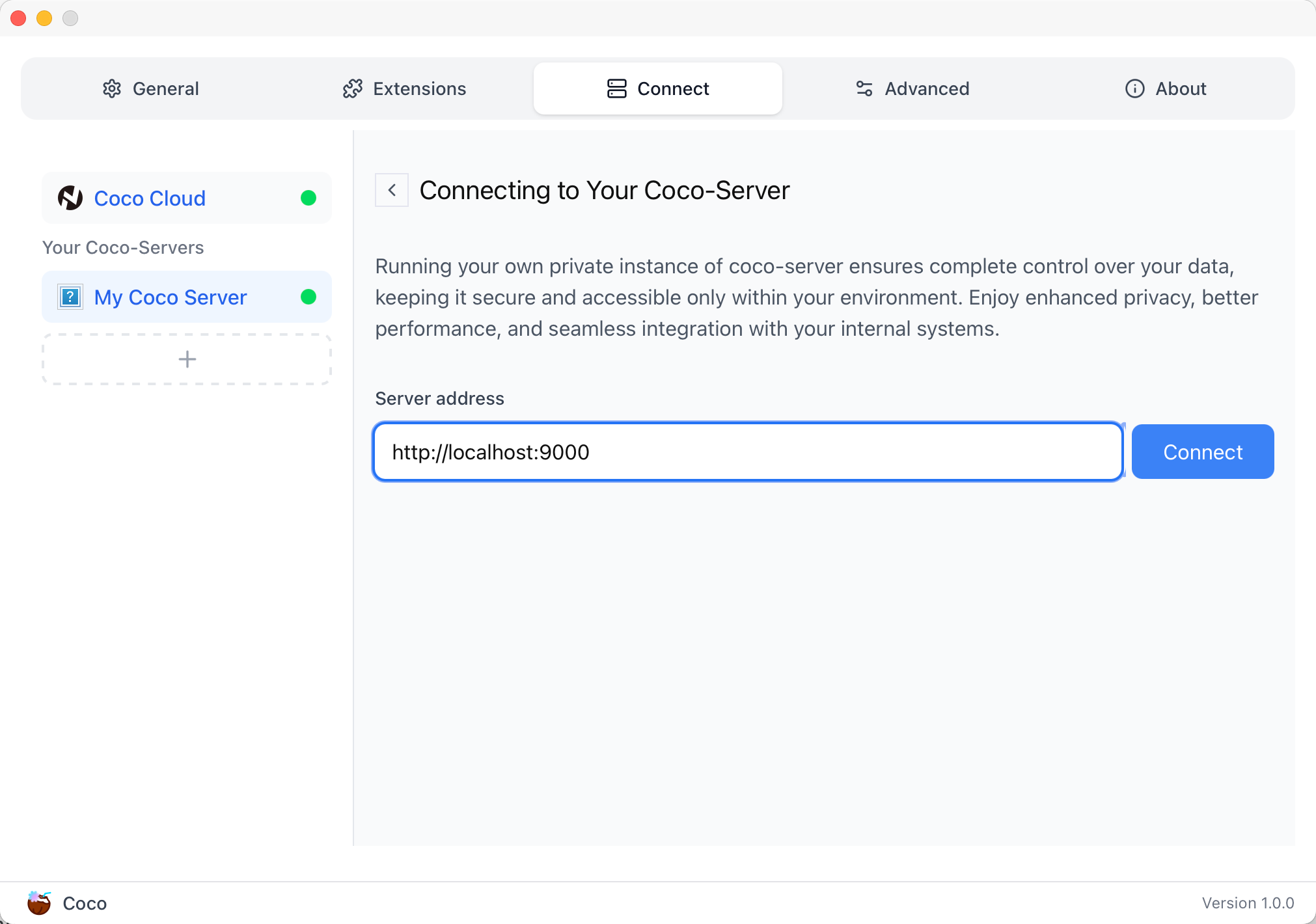 登录自己 server,依旧使用 Github 登录 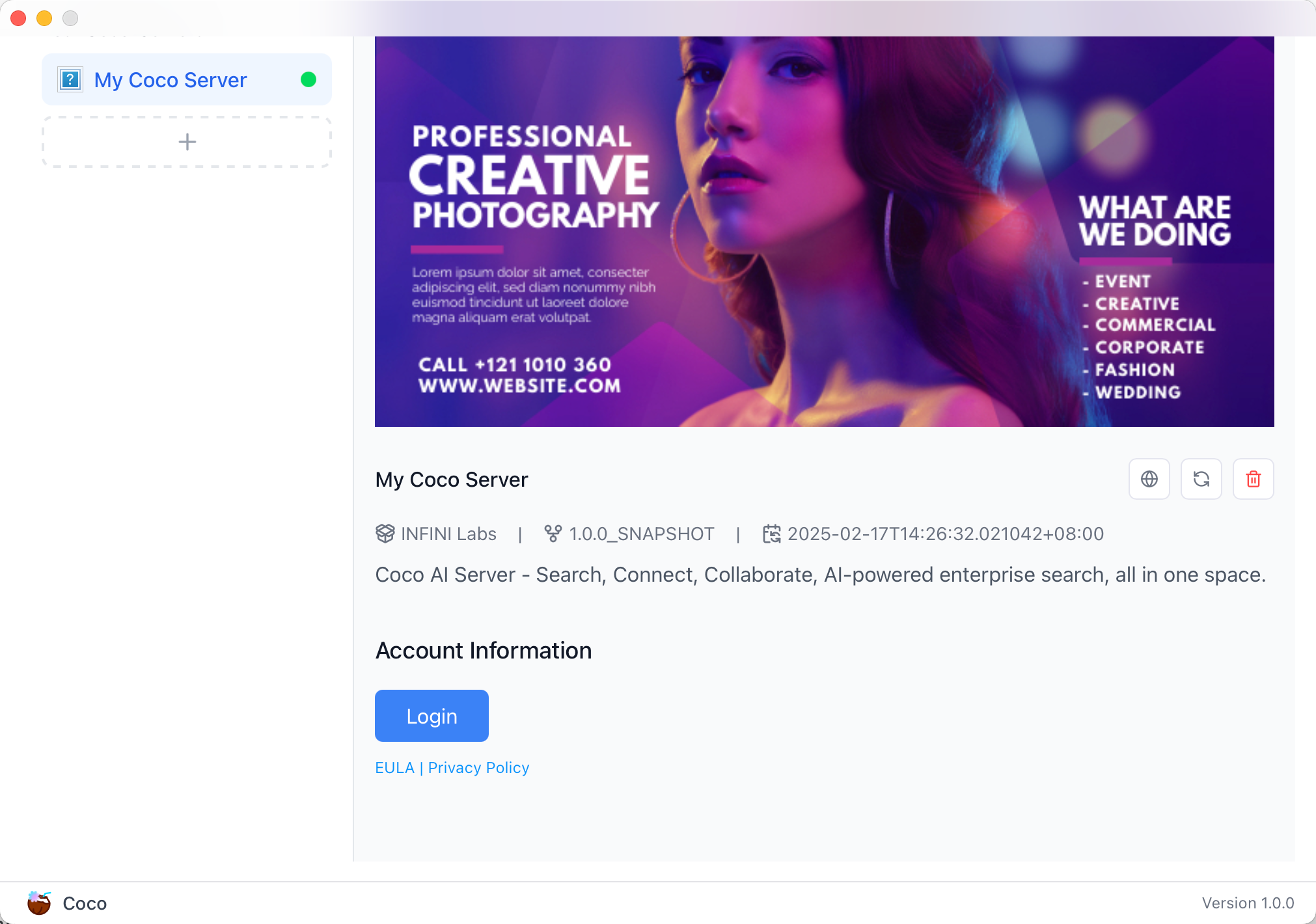 Github 登录之后的重定向,我们目前需要抓取最后的, 后面用这个 token 换取访问 Coco Server AI 的 key: ``` coco://oauth_callback?code=cupibub55o1cfqbveps0q804ai6aj14in3u91xjhvuk8s7ixirjsq2j9mmyyeut91nmgjwz0b494ngpk&request_id=eb94762b-f054-4710-9c6cf20889d3&provider=coco-cloud ``` 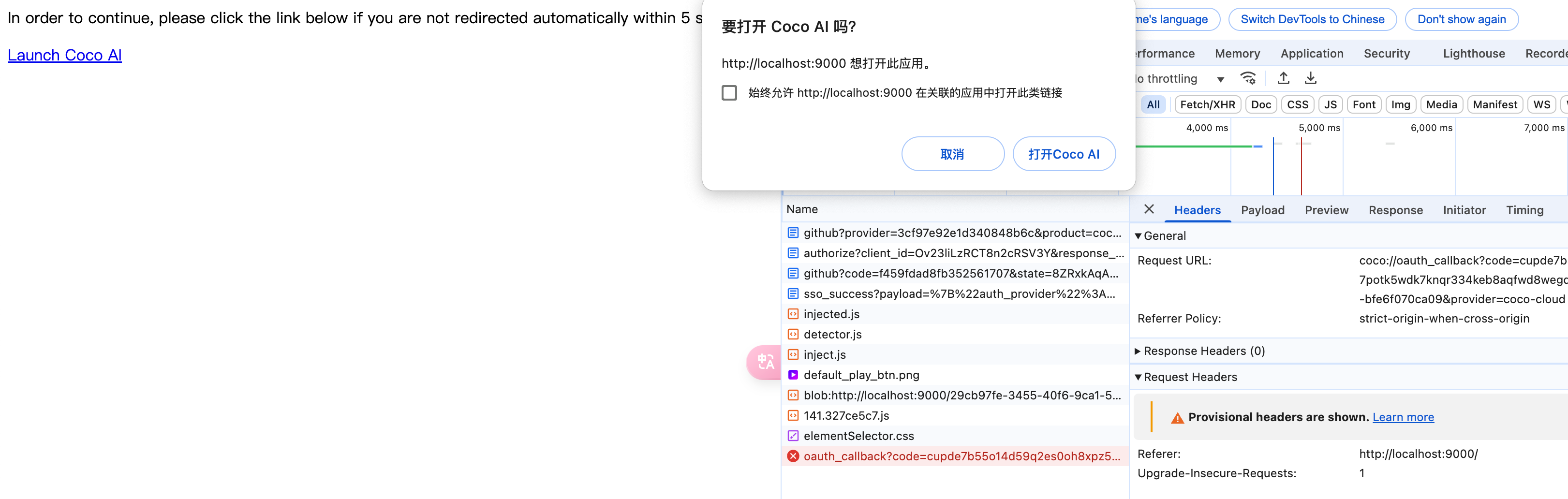 认证步骤如下: 第一步: http://localhost:9000/sso/login/github?provider=coco-cloud&product=coco&request_id=dd9825e1-ebd3-4c84-9e3f-7ccb0421c508 会返回一个 Token,记录下来,这个是只是临时的, 如 XXABC 第二步: curl -H'X-API-TOKEN: XXABC' "http://localhost:9000/auth/request_access_token?request_id=dd9825e1-ebd3-4c84-9e3f-7ccb0421c508" 返回的才是你要的 Token 在 postman 中换 token,得到 access_token 和过期时间: 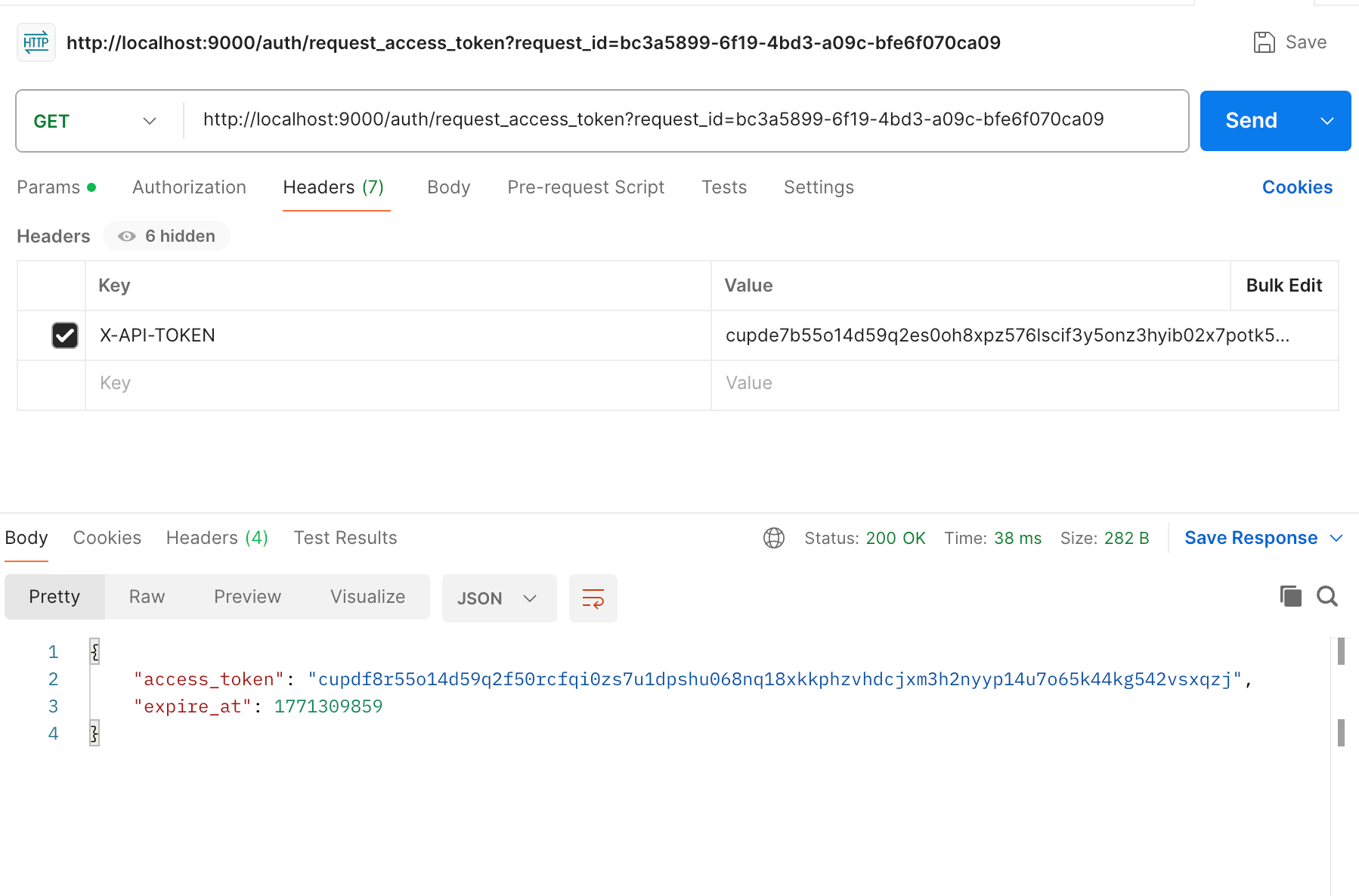 ```python import requests def parse_oauth_callback(url): query_params = {param.split('=')[0]: param.split('=')[1] for param in url.split('?')[1].split('&')} code = query_params.get("code") request_id = query_params.get("request_id") return code, request_id def request_access_token(code, base_url, request_id): url = f"{base_url}/auth/request_access_token?request_id={request_id}" headers = {"X-API-TOKEN": code} response = requests.get(url, headers=headers) return response.json() # 示例输入 oauth_callback_url = """ coco://oauth_callback?code=cupibub55o1cfqbveps0q804ai6aj151wu4in3u91xjhvuk8s7ixirjsq2j9mmyyeut91nmgjwz0b494ngpk&request_id=eb94762b-f054-4710-9c6a-0cf2088729d3&provider=coco-cloud """ base_url = "http://localhost:9000" # 解析 code 和 request_id code, request_id = parse_oauth_callback(oauth_callback_url) # 发送请求 token_response = request_access_token(code, base_url, request_id) print(token_response) ``` 可以用 access_key 查看用户信息: 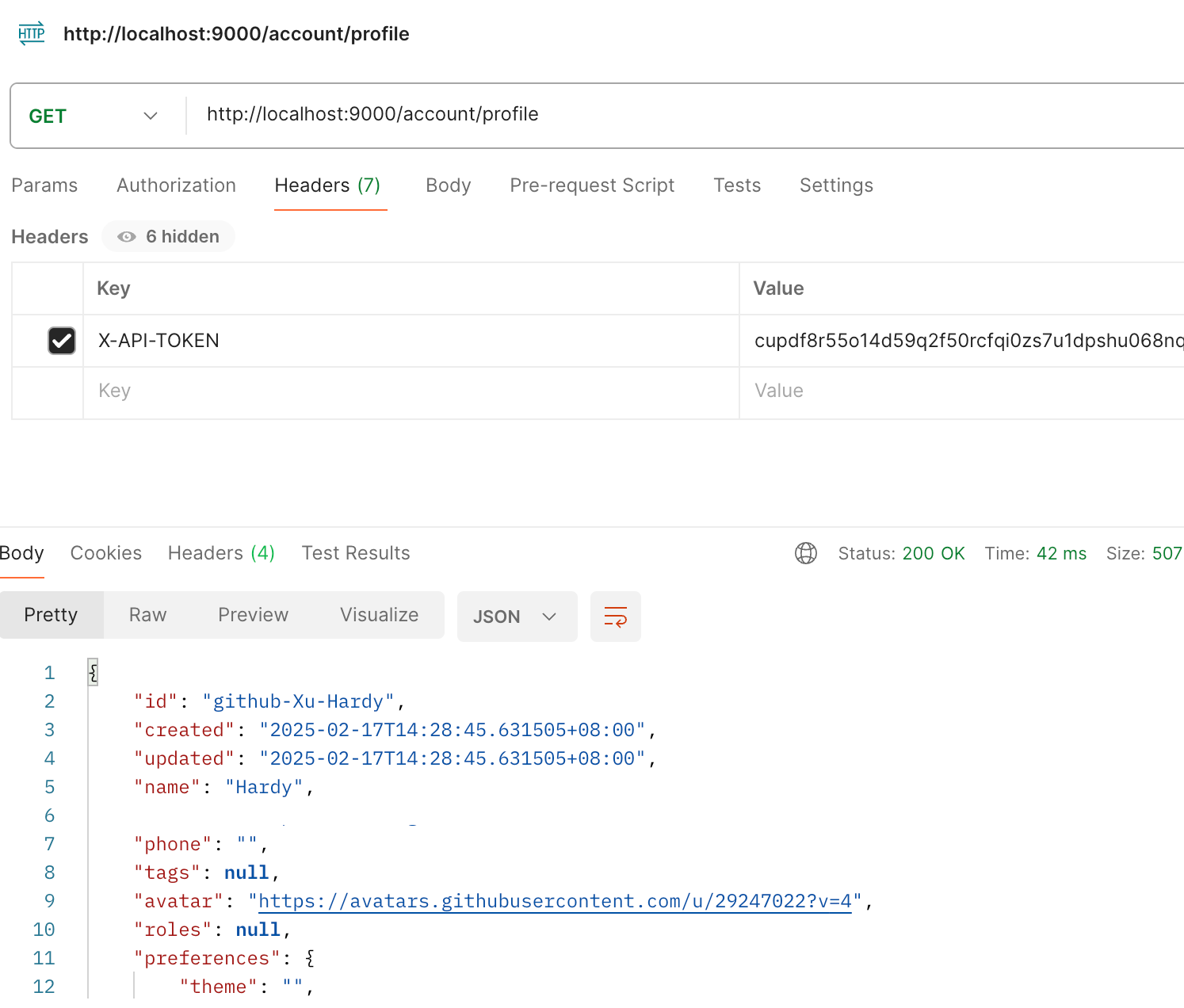 ```python import requests url = "http://localhost:9000/account/profile" payload = {} headers = { 'X-API-TOKEN': 'cupichb55o1cfqbveq90zwomyxs791ul3esbxxt480c8dzgvdtjtvmcnsld4a5v0wvx9l9ofcf1' } response = requests.request("GET", url, headers=headers, data=payload) print(response.text) ``` 注册 Notion connector: ```python import requests import json def update_connector(base_url, api_token, connector_name, data): url = f"{base_url}/connector/{connector_name}?replace=true" headers = { "X-API-TOKEN": api_token, "Content-Type": "application/json" } response = requests.put(url, headers=headers, data=json.dumps(data)) return response.json() base_url = "http://localhost:9000" api_token = "<token>" notion_data = { "name": "Notion Docs Connector", "description": "Fetch the docs metadata for notion.", "icon": "/assets/connector/notion/icon.png", "category": "website", "tags": ["docs", "notion", "web"], "url": "http://coco.rs/connectors/notion", "assets": { "icons": { "default": "/assets/connector/notion/icon.png", "web_page": "/assets/connector/notion/icon.png", "database": "/assets/connector/notion/database.png", "page": "/assets/connector/notion/page.png" } } } response_notion = update_connector(base_url, api_token, "notion", notion_data) print(response_notion) ``` 修改 Notion 配置文件,激活检索 Notion: 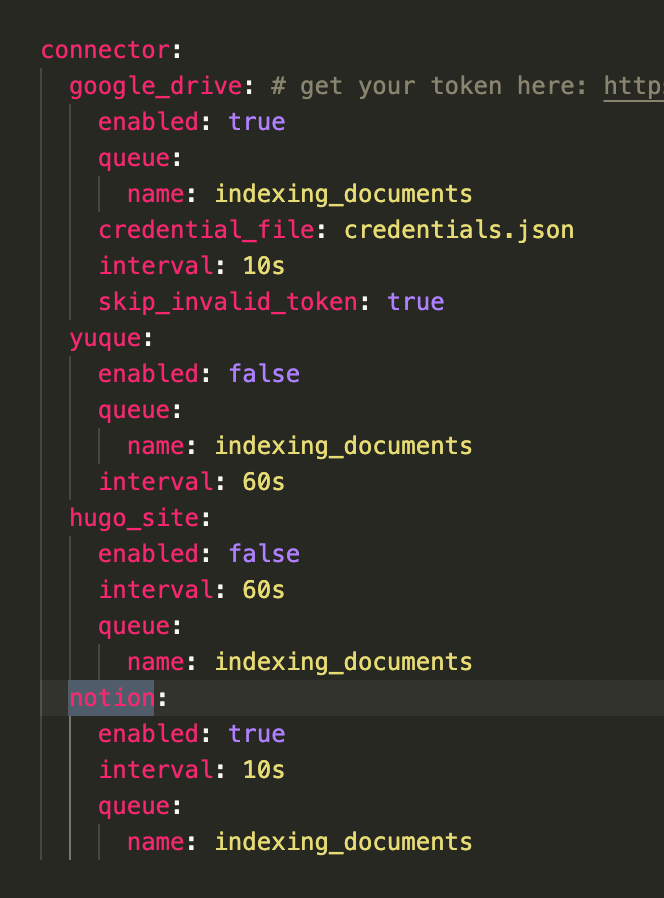 在 Notion 这个网站申请 API key,https://www.notion.so/profile/integrations 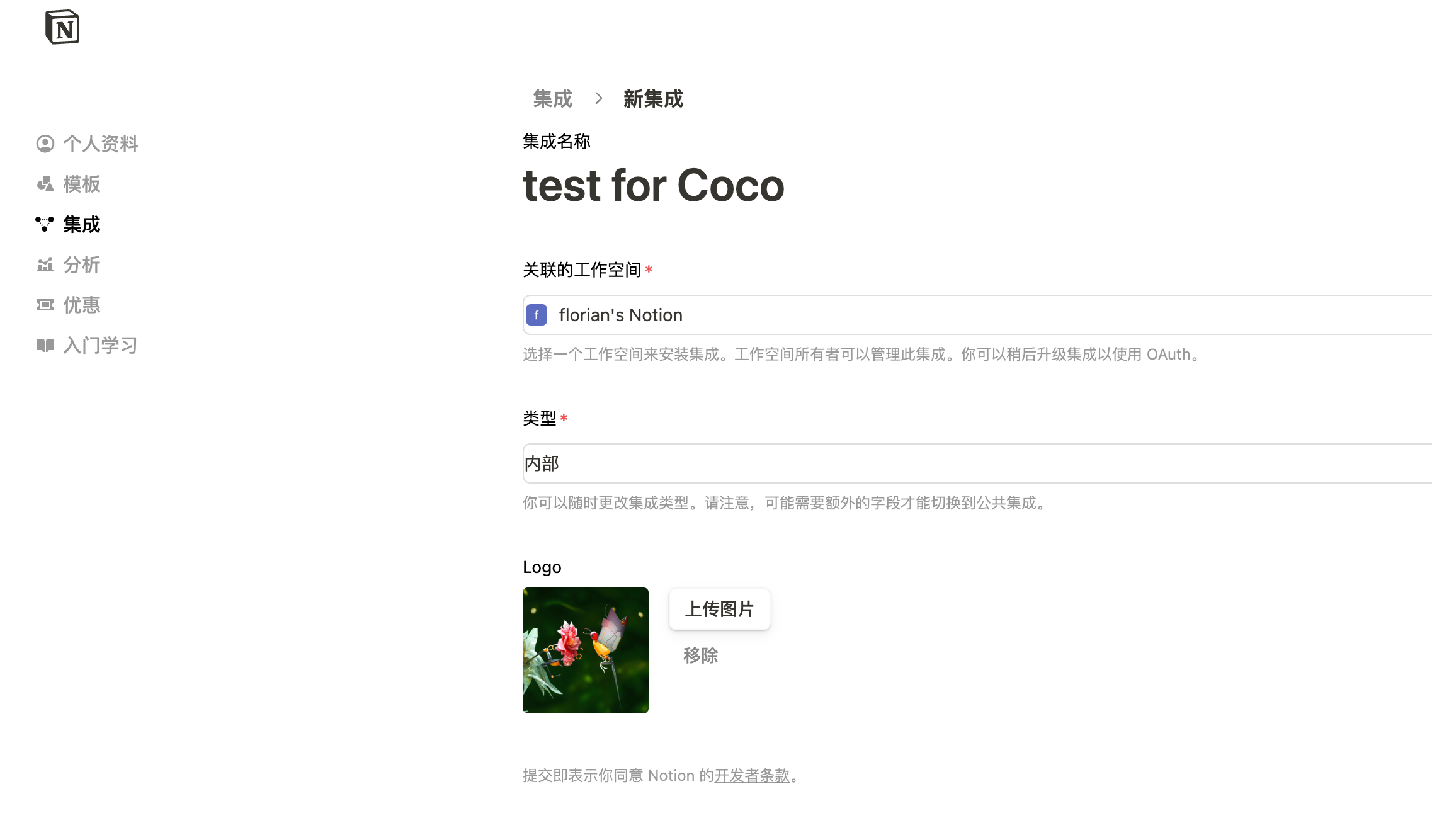 配置完成之后,设置权限和展示 apikey 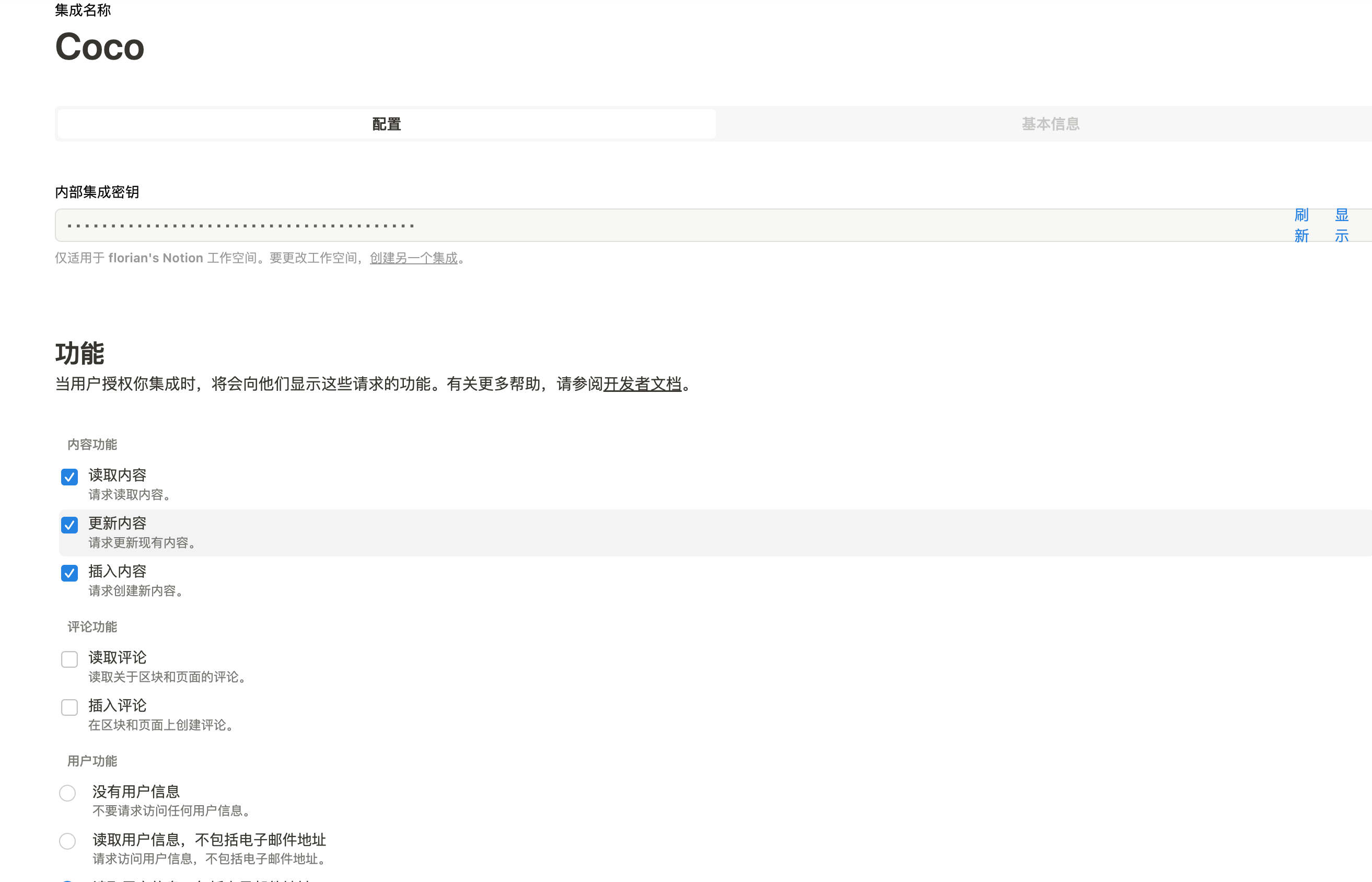 配置 Notion Connector,这里需要用到 Notion 的 API Key: ```python import requests import json def create_datasource(base_url, api_token, data): url = f"{base_url}/datasource/" headers = { "X-API-TOKEN": api_token, "Content-Type": "application/json" } response = requests.post(url, headers=headers, data=json.dumps(data)) return response.json() # 示例输入 base_url = "http://localhost:9000" api_token = "<api-key>" datasource_data = { "name": "My Notion", "type": "connector", "connector": { "id": "notion", "config": { "token": "<notion token>" } } } # 发送 POST 请求 response = create_datasource(base_url, api_token, datasource_data) print(response) ``` 需要在 Notion 中设置集成,这样 Coco Server 才会搜索到: 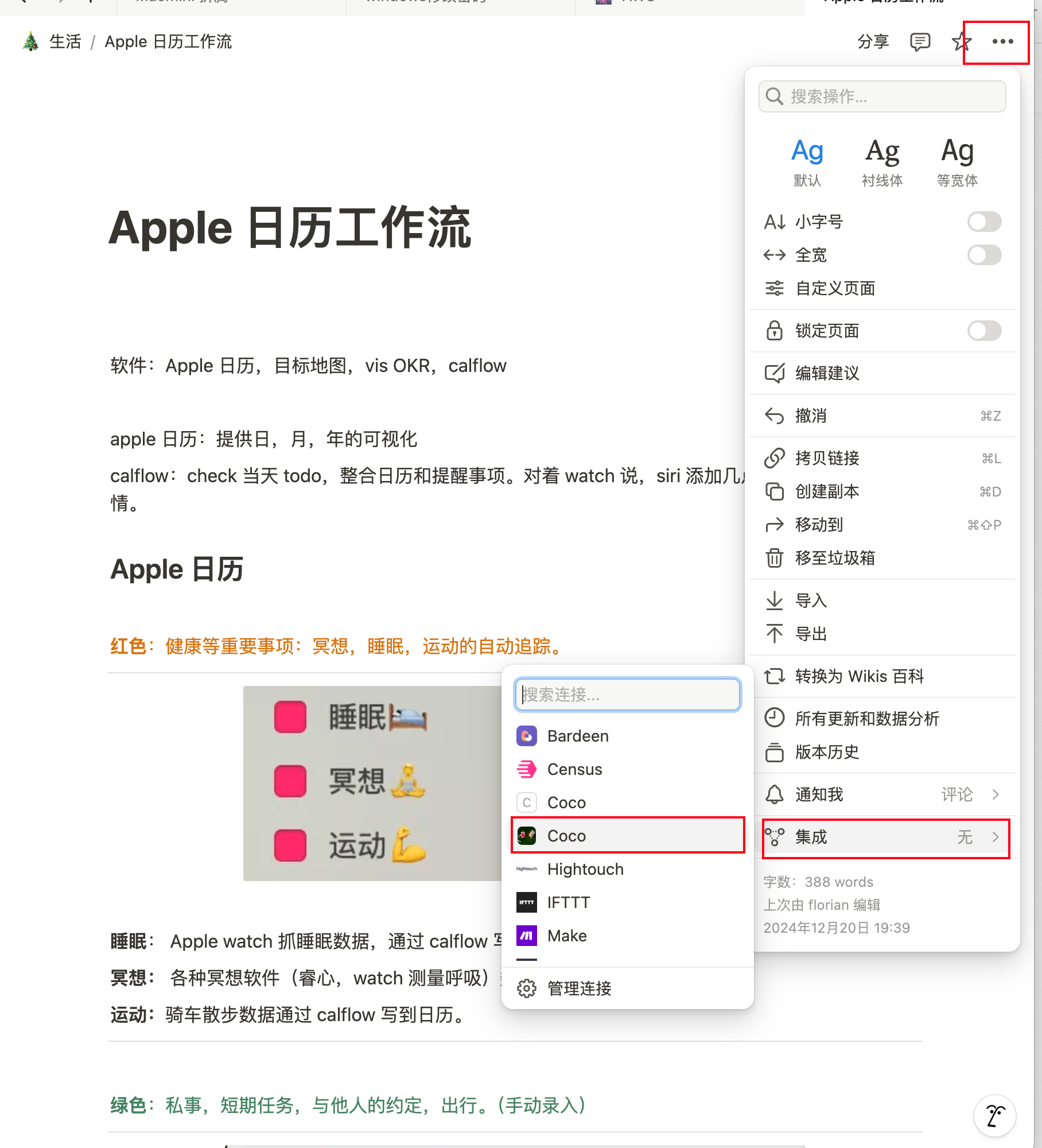 Coco server 日志中可以检索到 notion 了: 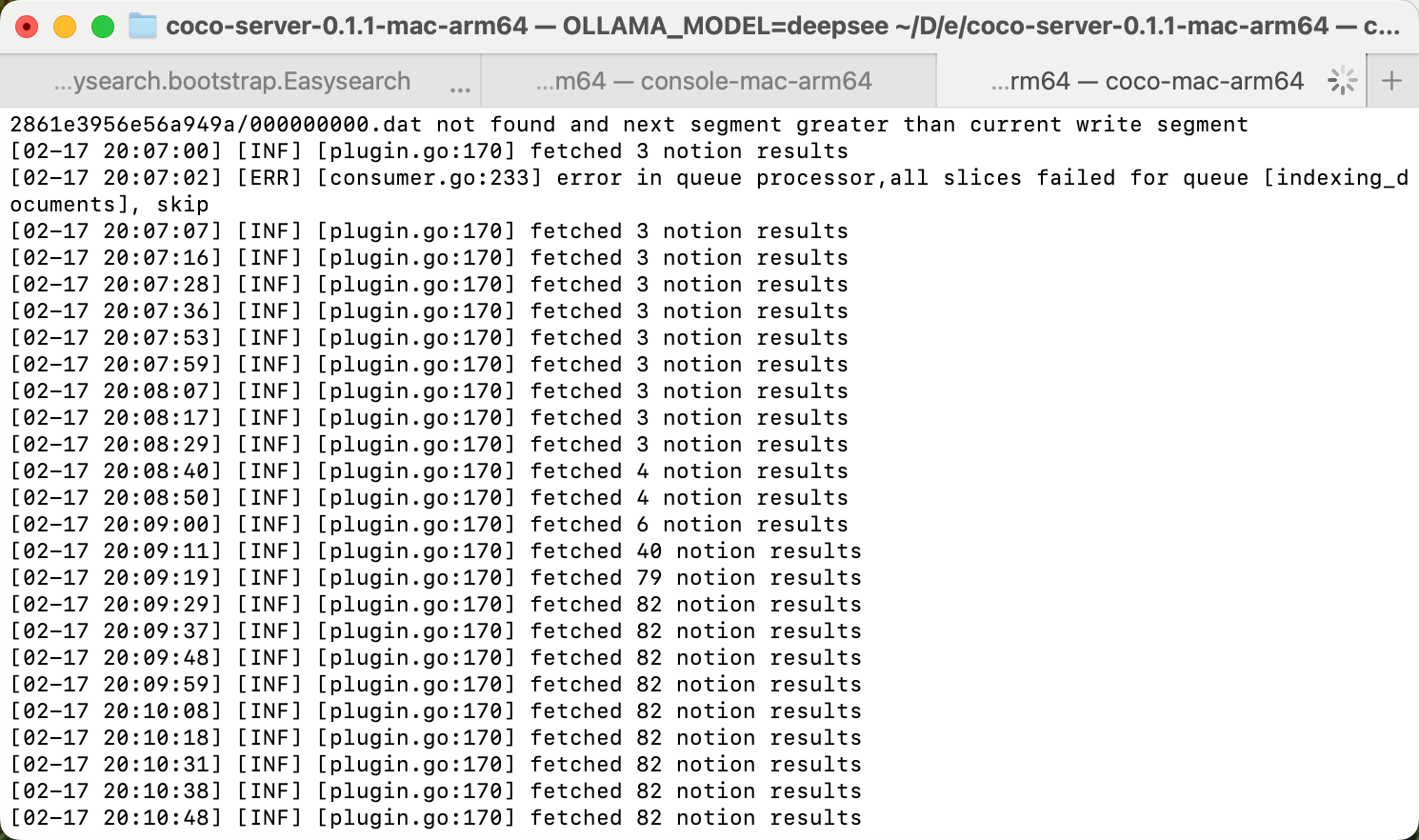 终于可以在搜索栏检索到了。 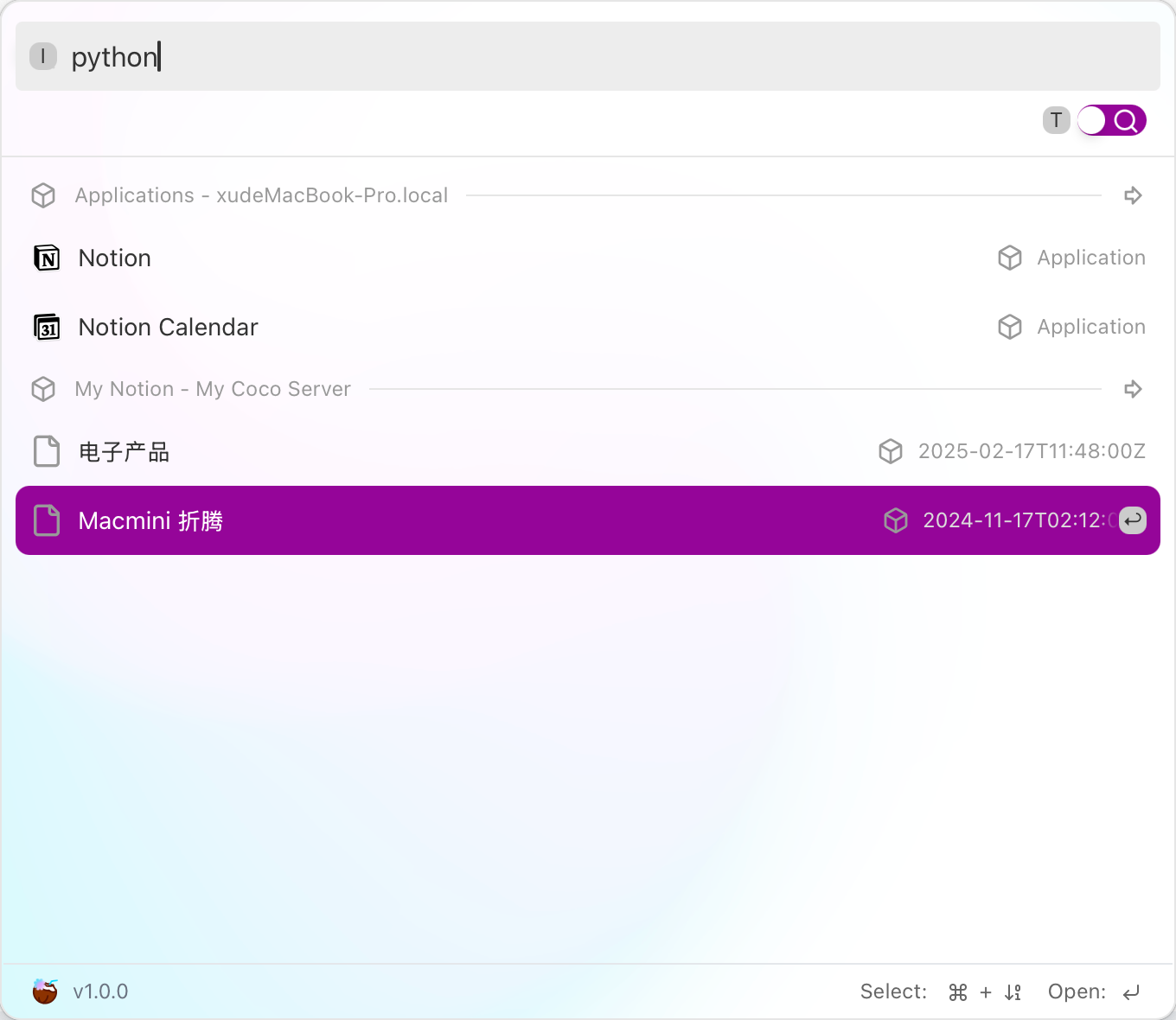

不建 Hugo、不用 Hexo,纯 Markdown 文件也能接入 Coco-AI!
之前我们介绍过如何通过 Coco-AI 检索 Hugo 和 Hexo 的文件结构。这种方式虽然适合博客类内容,但对于一些**零碎的笔记**或者并非建站类的 Markdown 文件,显然不够灵活。 为了解决这个问题,我写了一个适配器(connector),并发布了对应的 Docker 镜像,来实现**任意 Markdown 文件目录的元数据整理与 API 暴露**: https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai <!-- more --> 👉 镜像地址:[https://hub.docker.com/r/cloudsmithy/flask-markdown-connector](https://hub.docker.com/r/cloudsmithy/flask-markdown-connector) ## 核心原理 该 connector 的主要逻辑是: 1. **递归扫描目录及子目录下的 Markdown 文件**; 2. **识别或补充元数据**(即 YAML Front Matter); 3. **通过 RESTful API 暴露这些 Markdown 的结构信息和元数据内容**。 如下图所示,我们会在每个 Markdown 文件开头添加或提取出 YAML 元数据:  ## 一键部署 使用以下命令即可快速拉起服务: ```bash docker run -d --name markdown-connector \ -p 1313:5000 \ -v "$(pwd):/app/markdown" \ --restart always \ cloudsmithy/flask-markdown-connector ``` ### 参数说明: - `-d`:后台运行容器; - `--name markdown-connector`:指定容器名称; - `-p 1313:5000`:将宿主机的 1313 端口映射到容器的 5000 端口; - `-v "$(pwd):/app/markdown"`:将当前目录挂载进容器; - `--restart always`:配置容器异常退出后自动重启; - `cloudsmithy/flask-markdown-connector`:镜像名称。 ## API 一览 通过浏览器访问 `http://localhost:1313/apidocs` 即可打开内置 Swagger 文档。方便上层系统(如 Coco-AI)访问 Markdown 文件的元数据与内容。接口结构简洁直观,支持获取索引、刷新缓存、读取内容等功能。 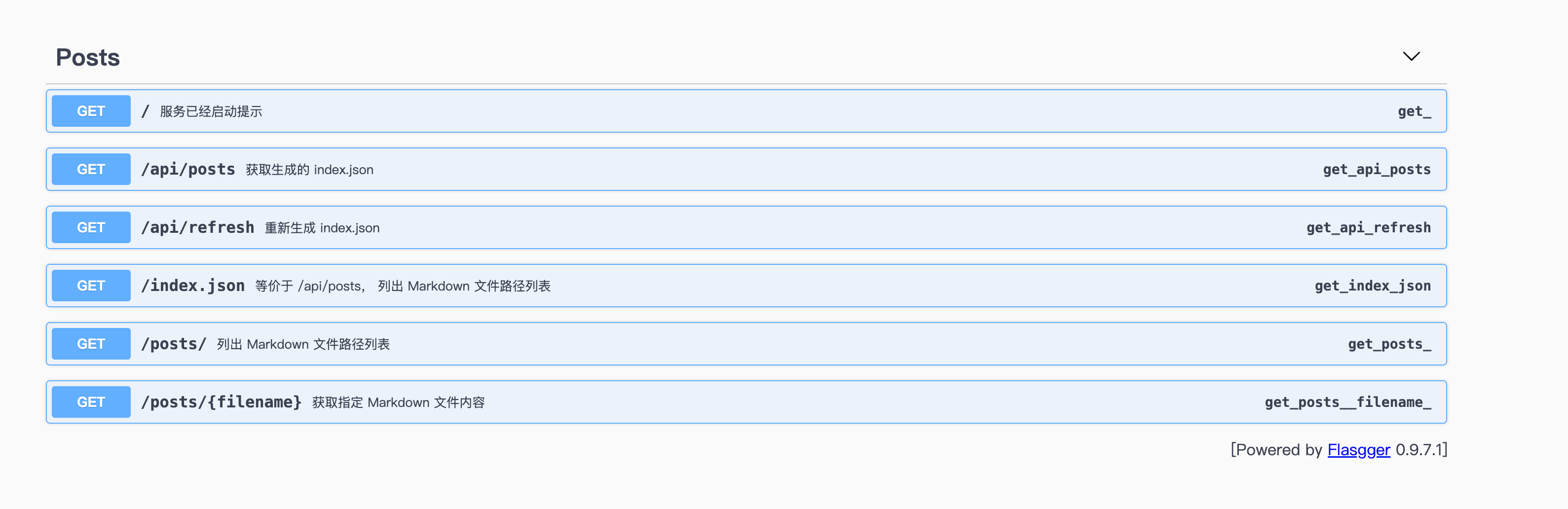 ### 🔹 `GET /` **功能**:返回服务启动提示信息 **说明**:用于检查服务是否正常运行 **示例响应**: ```json { "message": "Markdown Connector is running." } ``` ### 🔹 `GET /api/posts` **功能**:获取生成的 `index.json`(缓存版) **说明**:返回 Markdown 文件的路径与元数据列表,从缓存中读取,响应速度快 **用途**:Coco Server 可用作索引加载入口 **示例响应**: ```json [ { "title": "Docker 学习笔记", "path": "dev/docker.md", "tags": ["docker", "学习"], "created": "2024-11-22" }, ... ] ``` ### 🔹 `GET /index.json` **功能**:实时渲染当前 Markdown 目录结构 **说明**:等价于 `/api/posts`,但是实时读取文件而非使用缓存,适合调试或手动使用 **用途**:确保数据为最新状态时使用 ### 🔹 `GET /api/refresh` **功能**:重新扫描并生成最新的 `index.json` 缓存 **说明**:用于强制刷新目录索引,适用于新增 / 修改了 Markdown 文件后 **响应示例**: ```json { "message": "Index cache refreshed." } ``` ### 🔹 `GET /posts/` **功能**:列出 Markdown 文件路径列表(不含元数据) **说明**:返回所有可访问的 Markdown 文件路径,用于构建下拉菜单、快速跳转 **响应示例**: ```json ["notes/linux.md", "dev/docker.md", "ideas/gpt-agent.md"] ``` ### 🔹 `GET /posts/{filename}` **功能**:获取指定 Markdown 文件的内容 **参数**: - `{filename}`:Markdown 文件路径(相对于挂载目录) **用途**:用于前端点击跳转后展示具体笔记内容 **响应示例**: ```json { "filename": "dev/docker.md", "content": "# Docker 学习笔记\n\n## 容器 vs 镜像 ..." } ``` - 用于 Coco Server,推荐使用 `/api/posts` 作为内容索引源; - 使用 `/api/refresh` 后再拉一次 `/api/posts` 可确保内容最新; - 若前端需要展示具体内容,可调用 `/posts/{filename}`; - 若用在其他 AI 项目中,也可用于构建轻量级 Markdown 知识检索接口。 ## 与 Coco Server 集成 在 Orbstack 中,我们可以清晰地看到本地 Markdown 文件已经映射到容器中: 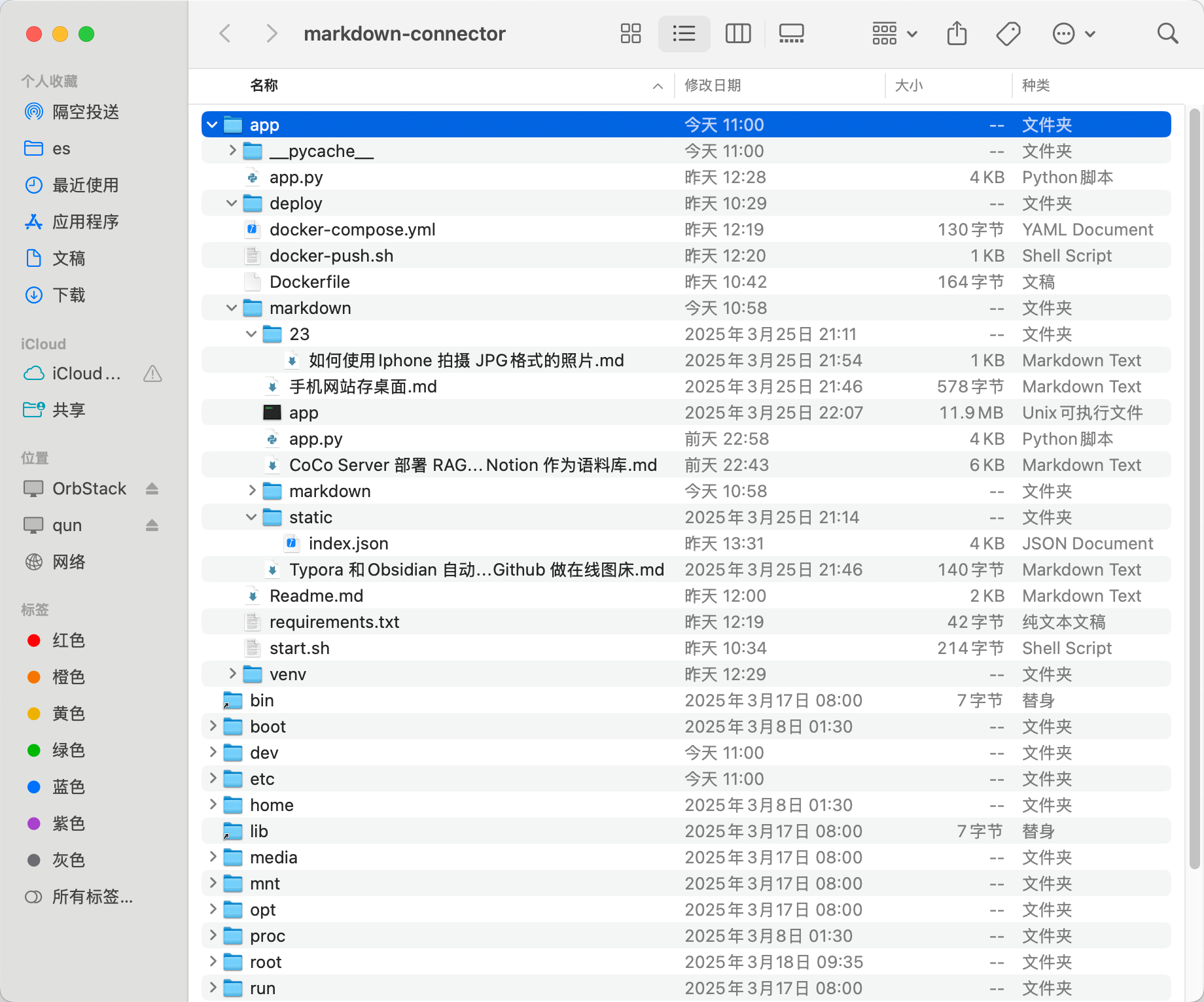 接着我们将 connector 的服务地址填入 Coco Server 配置中: 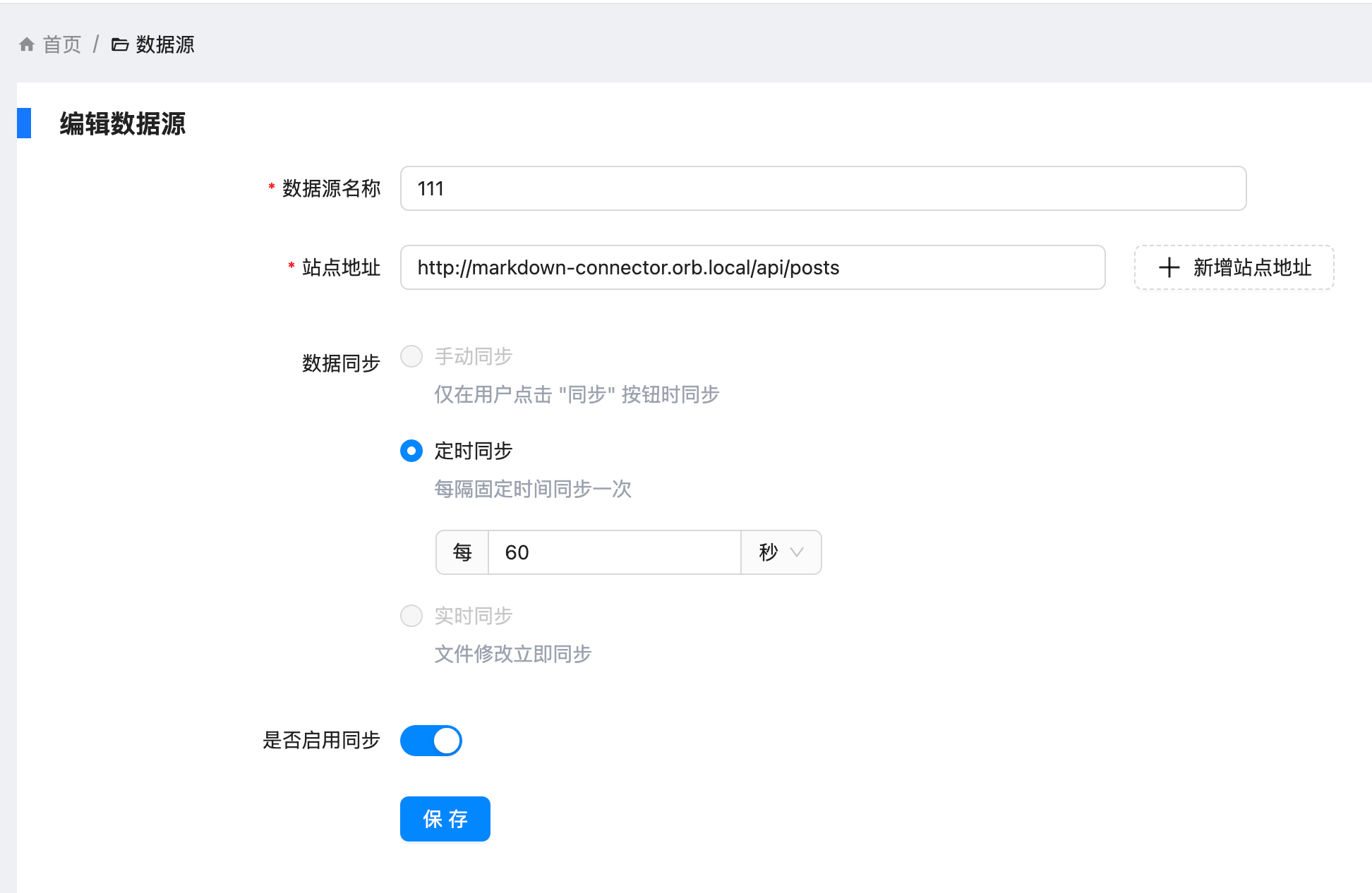 你可以使用 `/api/posts` 或 `/index.json` 接口,它们返回的内容基本一致: - `/api/posts` 是来自缓存的接口; - `/index.json` 是实时渲染本地文件结构。 另外,通过 `/api/refresh` 还可以手动触发缓存刷新: 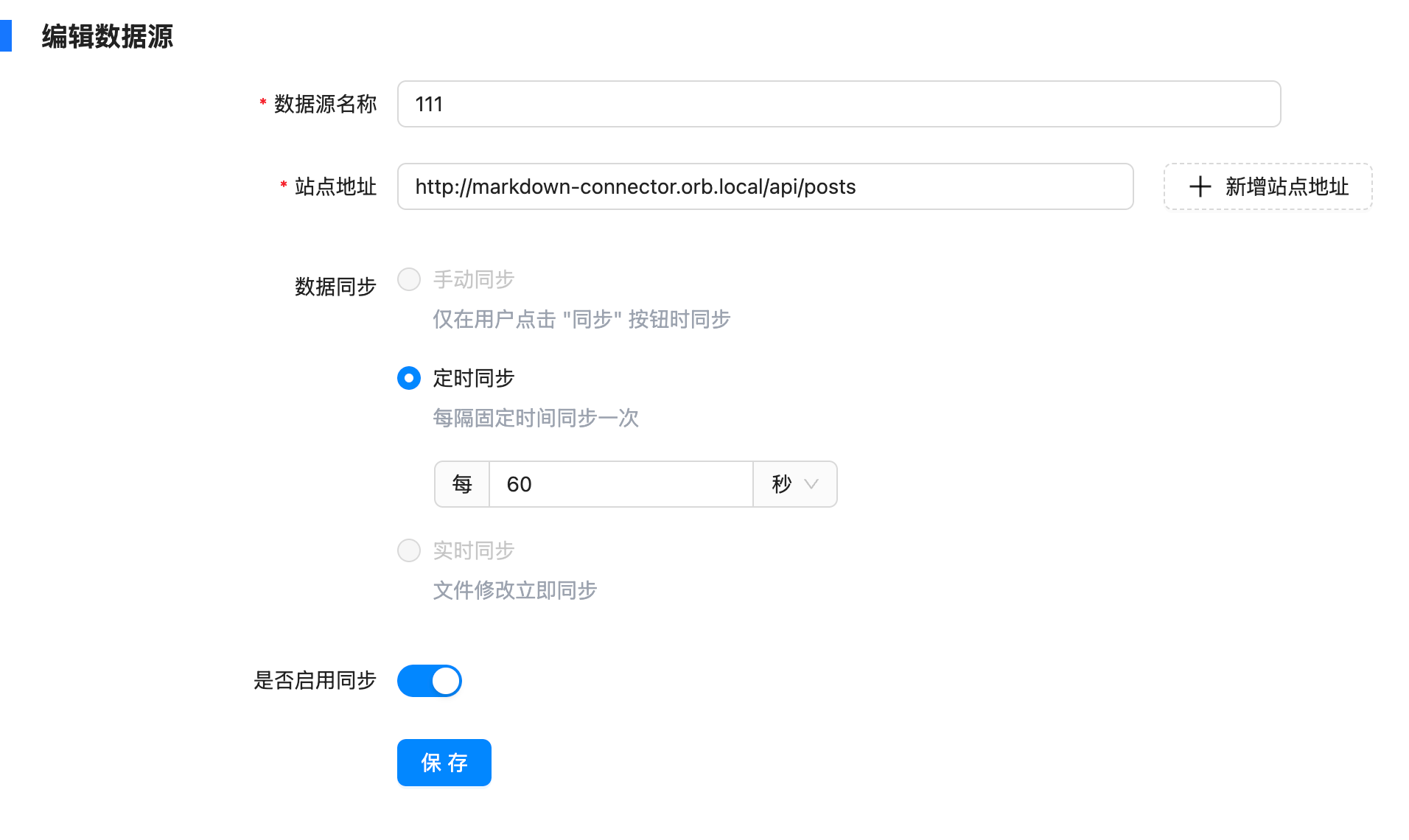 ## 效果演示 成功接入后,Coco Server 就可以读取 Markdown 文件的结构与元数据信息: 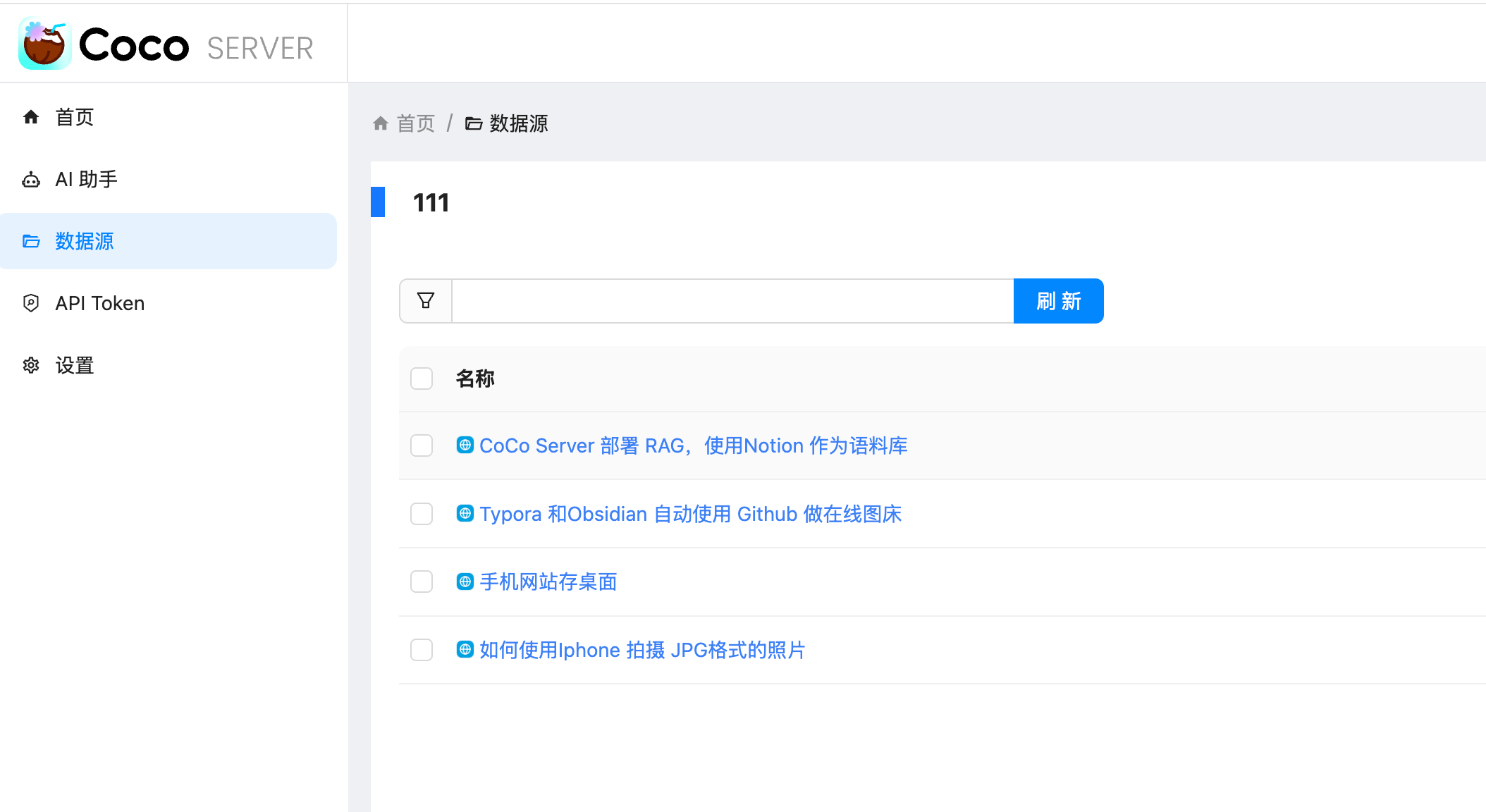 点击条目还可以跳转到对应的网页:  当然,和之前一样,也支持在搜索栏中直接搜索并跳转: 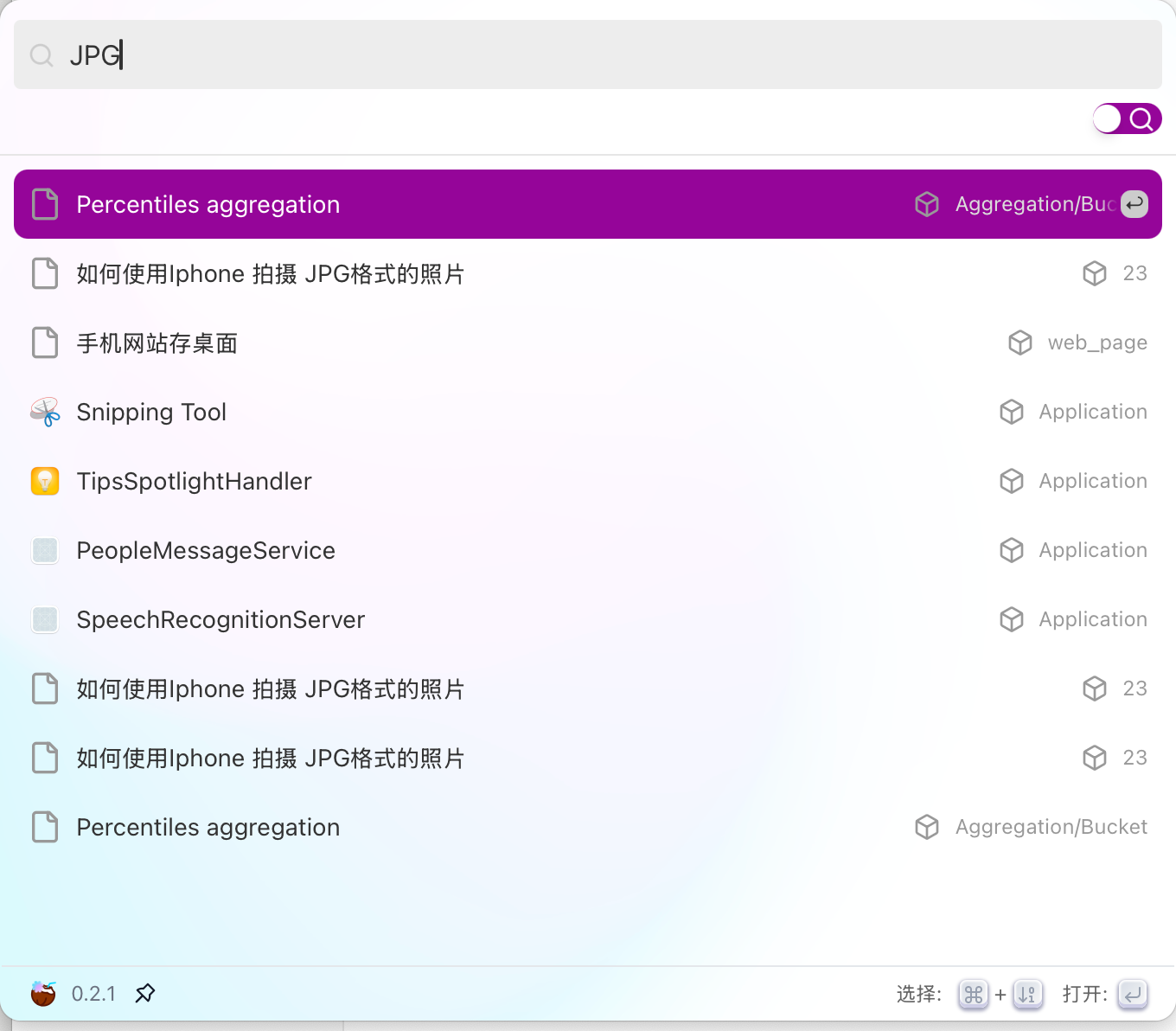 ## 小结 通过这个 Flask 版 Markdown Connector,我们可以将任意 Markdown 文件目录结构化暴露给 Coco-AI,实现: - 笔记内容统一索引 - 结构与元数据清晰可控 - 快速部署,无需 Hugo/Hexo 建站 这对于日常碎片化笔记管理来说,是一个非常轻量又灵活的解决方案。
Coco-AI 接入 Google drive
https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai 在 Coco-AI 最早的版本就提供了接入 Google drive 的视频,今天我终于实现了,而且借着全图形化的优势更加方便了。 参考这个文档新建 google SSO(好像也没啥参考性) https://developers.google.com/workspace/drive/api/quickstart/go?hl=zh-cn <!-- more --> 创建客户端  填入信息, 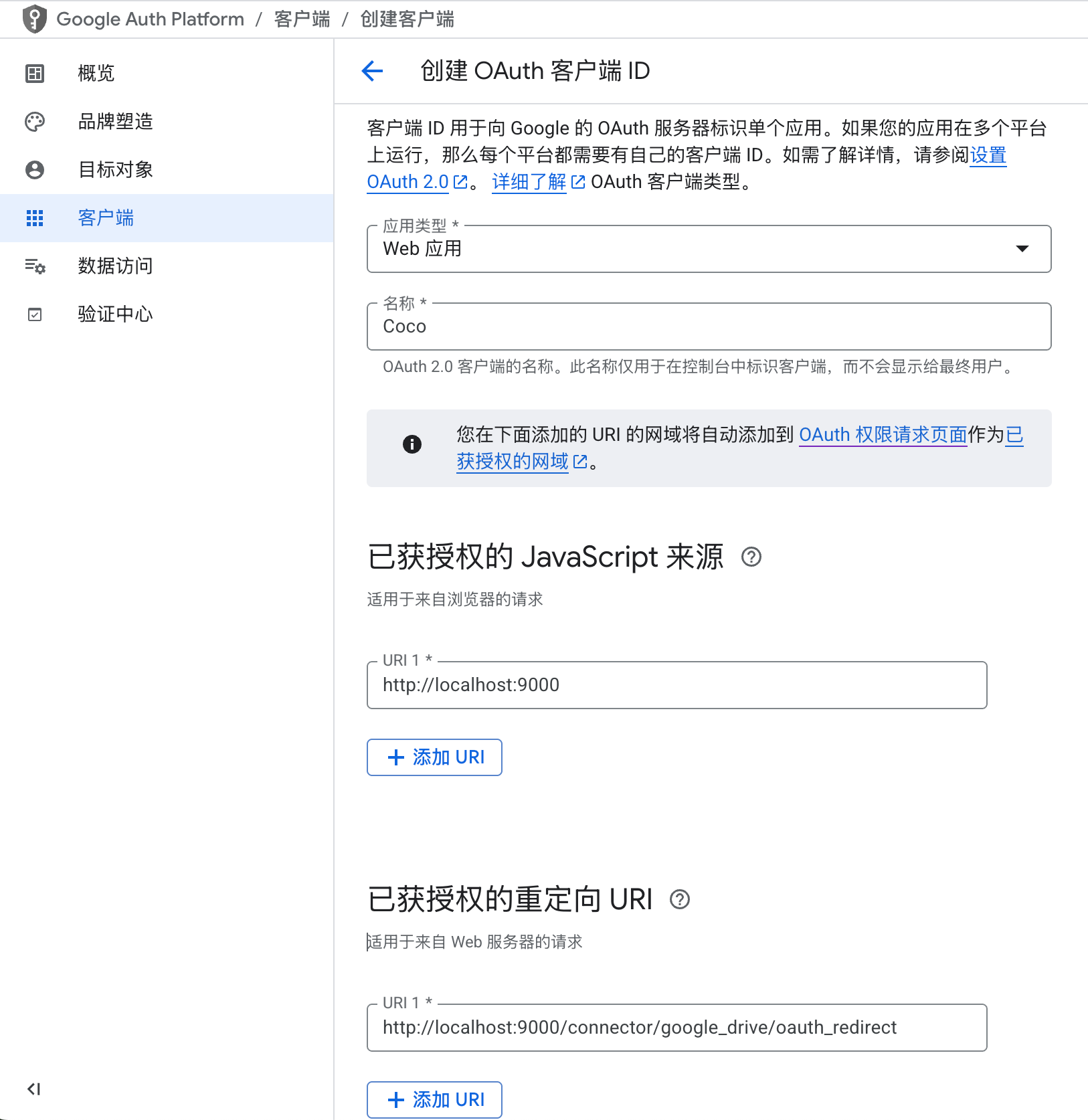 然后在数据访问中添加权限 - 缺少的权限加在这里(如图),https://www.googleapis.com/auth/drive 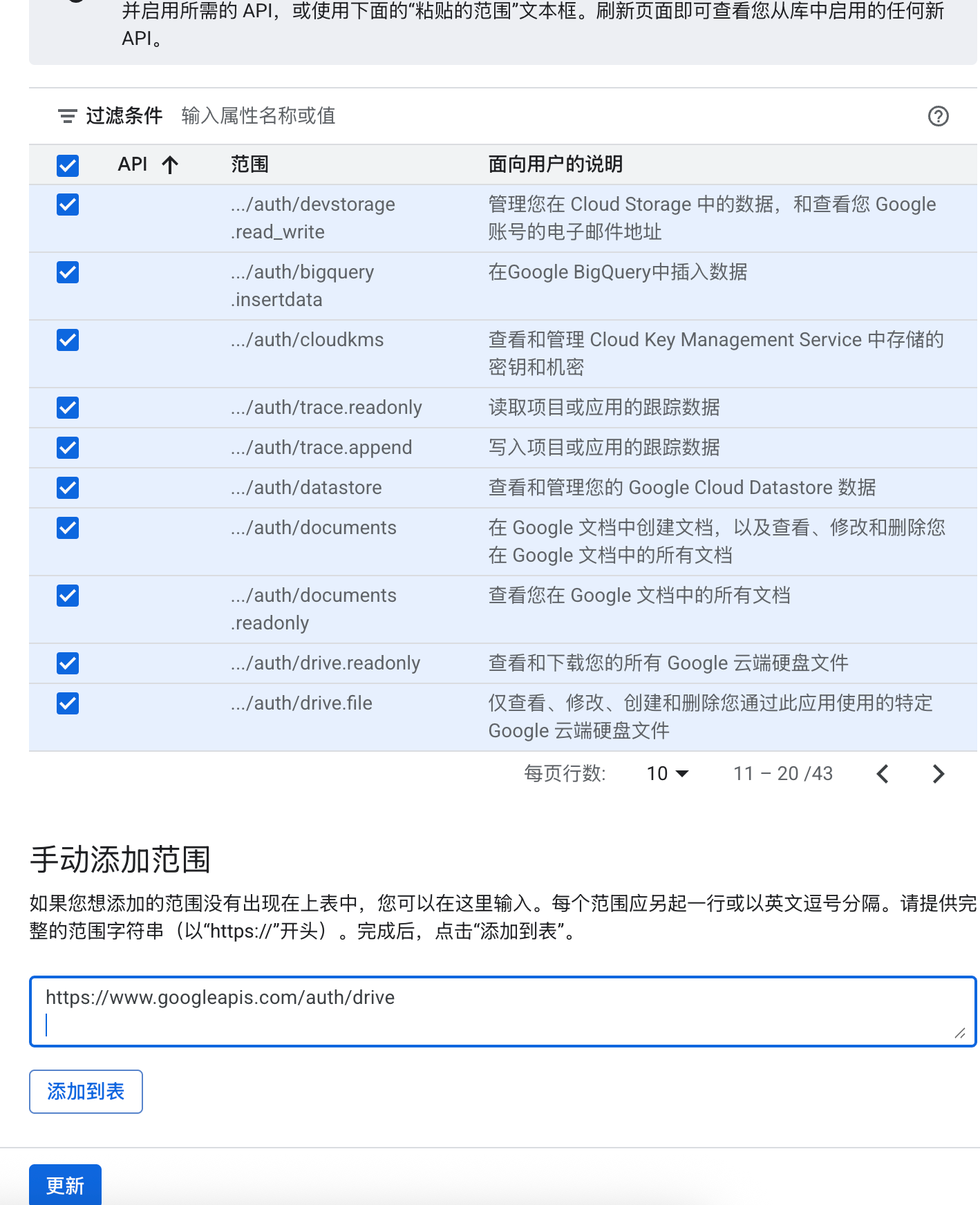 在 coco-sever 更新 google drive 的信息 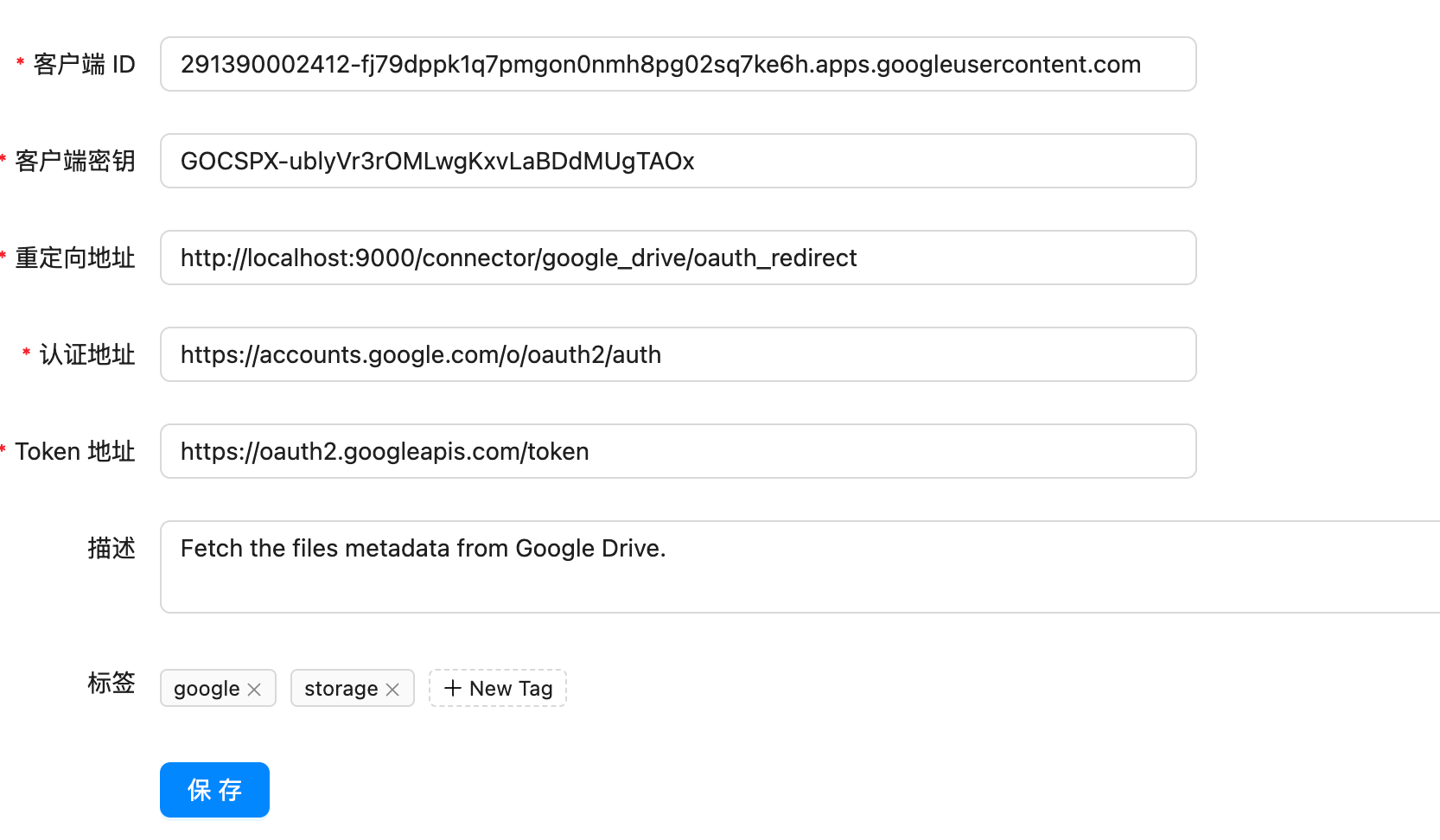 然后在 coco-server 中连接 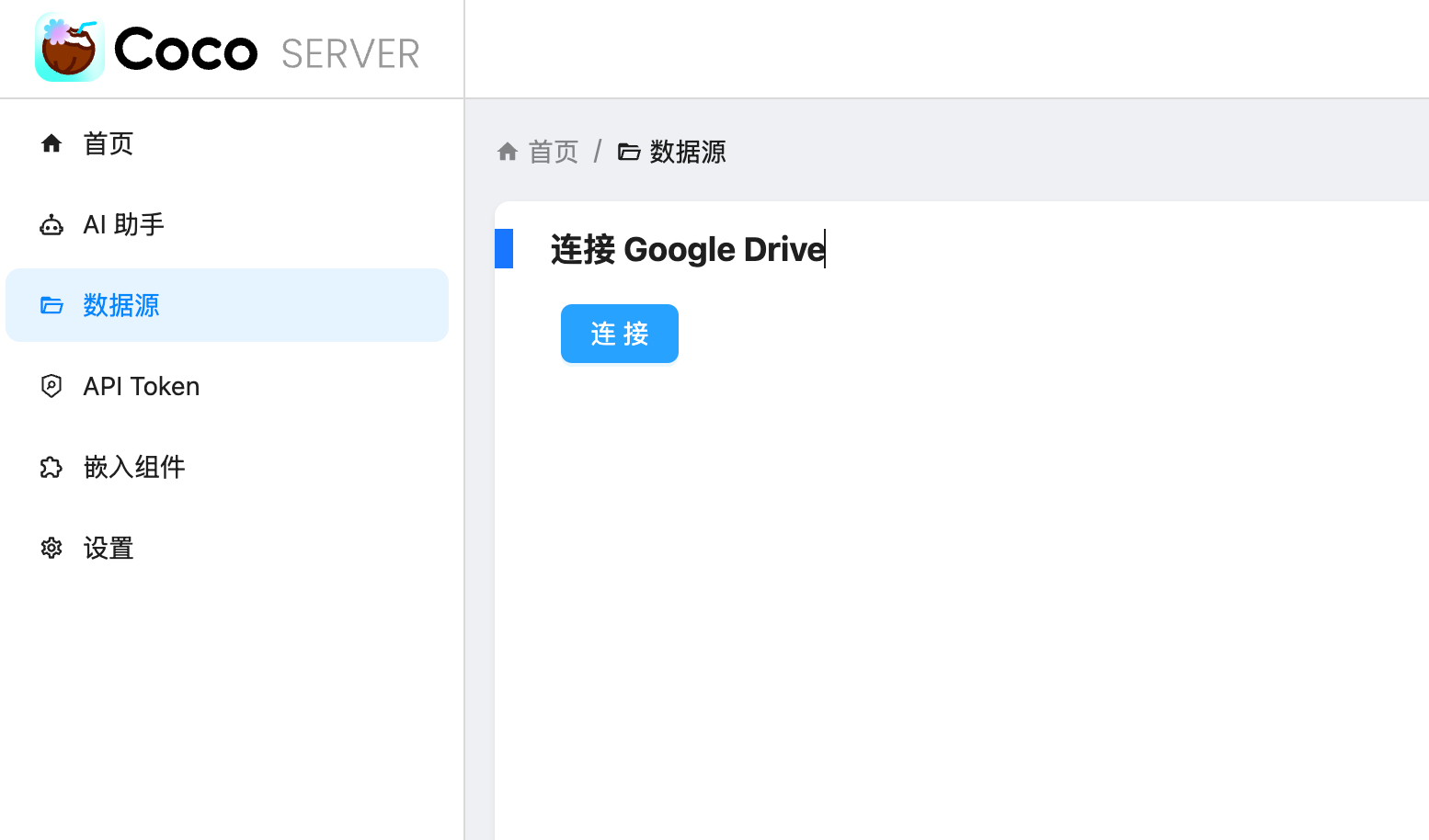 跳转 google sso 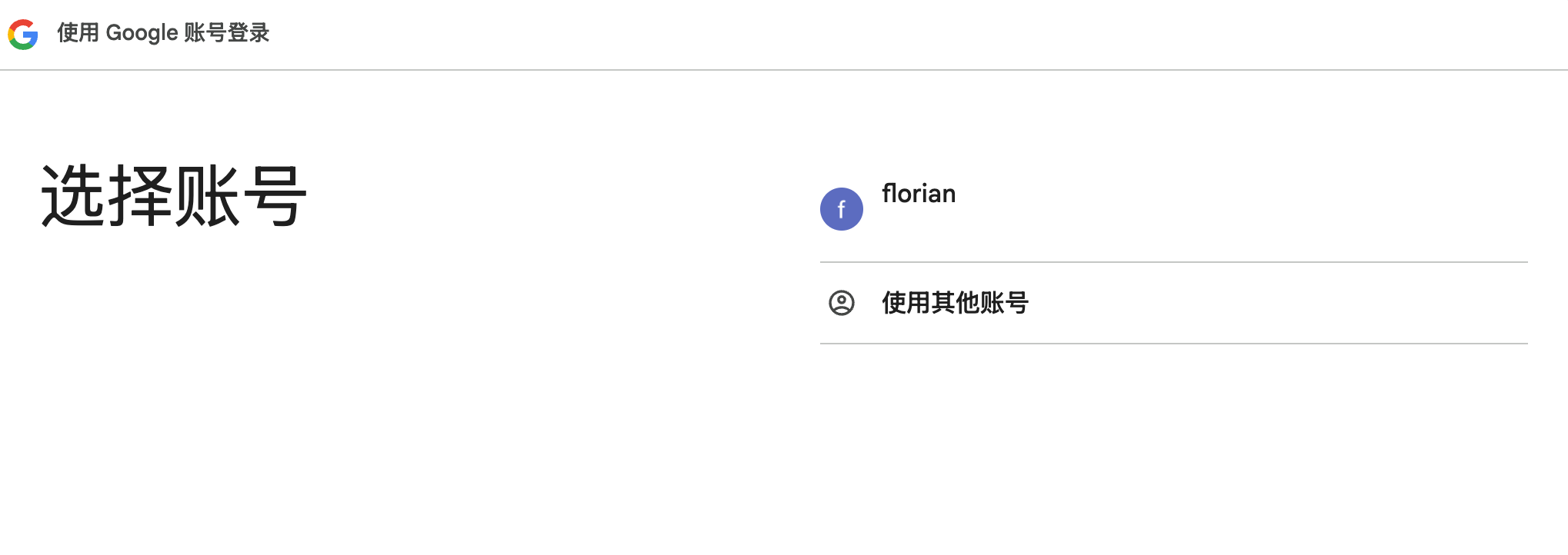 由于是测试账户,所以会有这个弹窗,继续就好  再次进行测试  获取权限 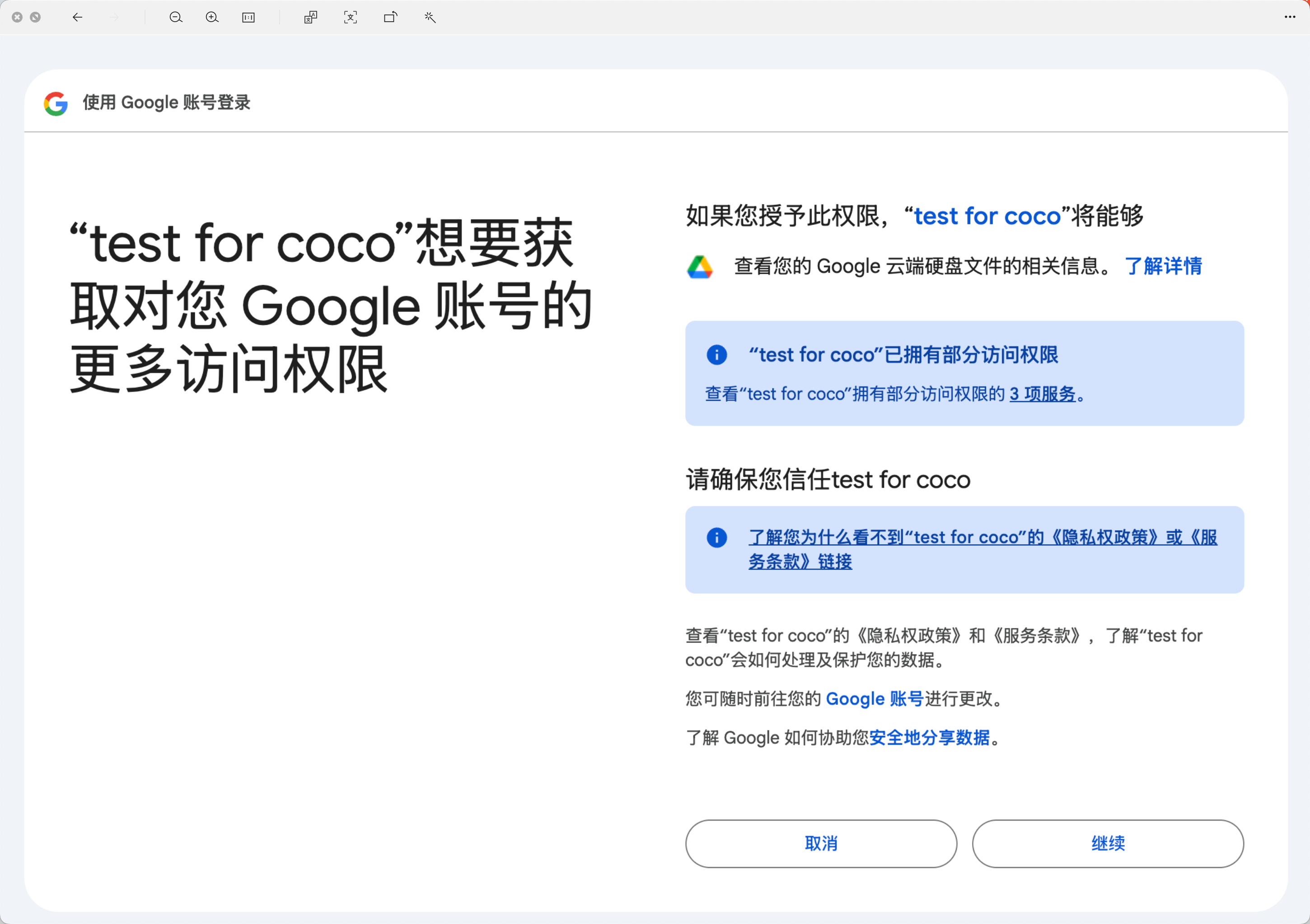 显示登陆成功 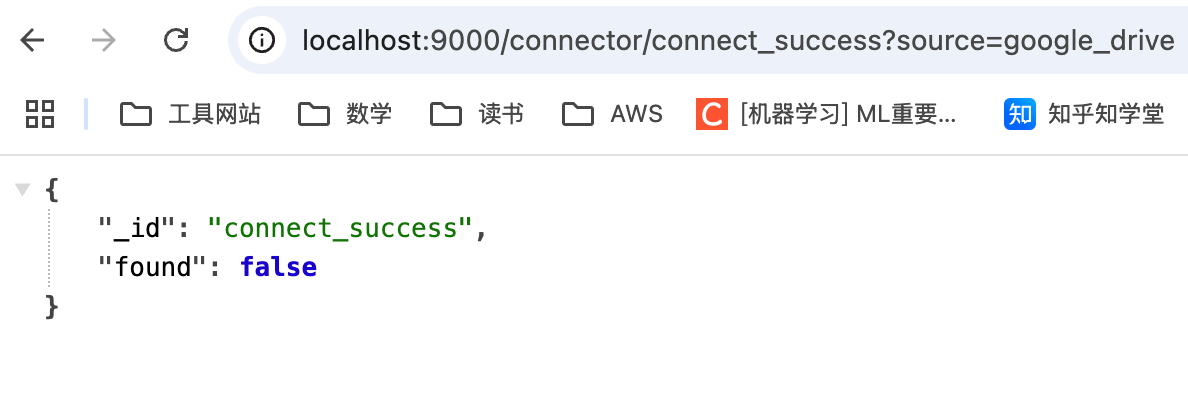 然后可以在数据源中看到对应数据 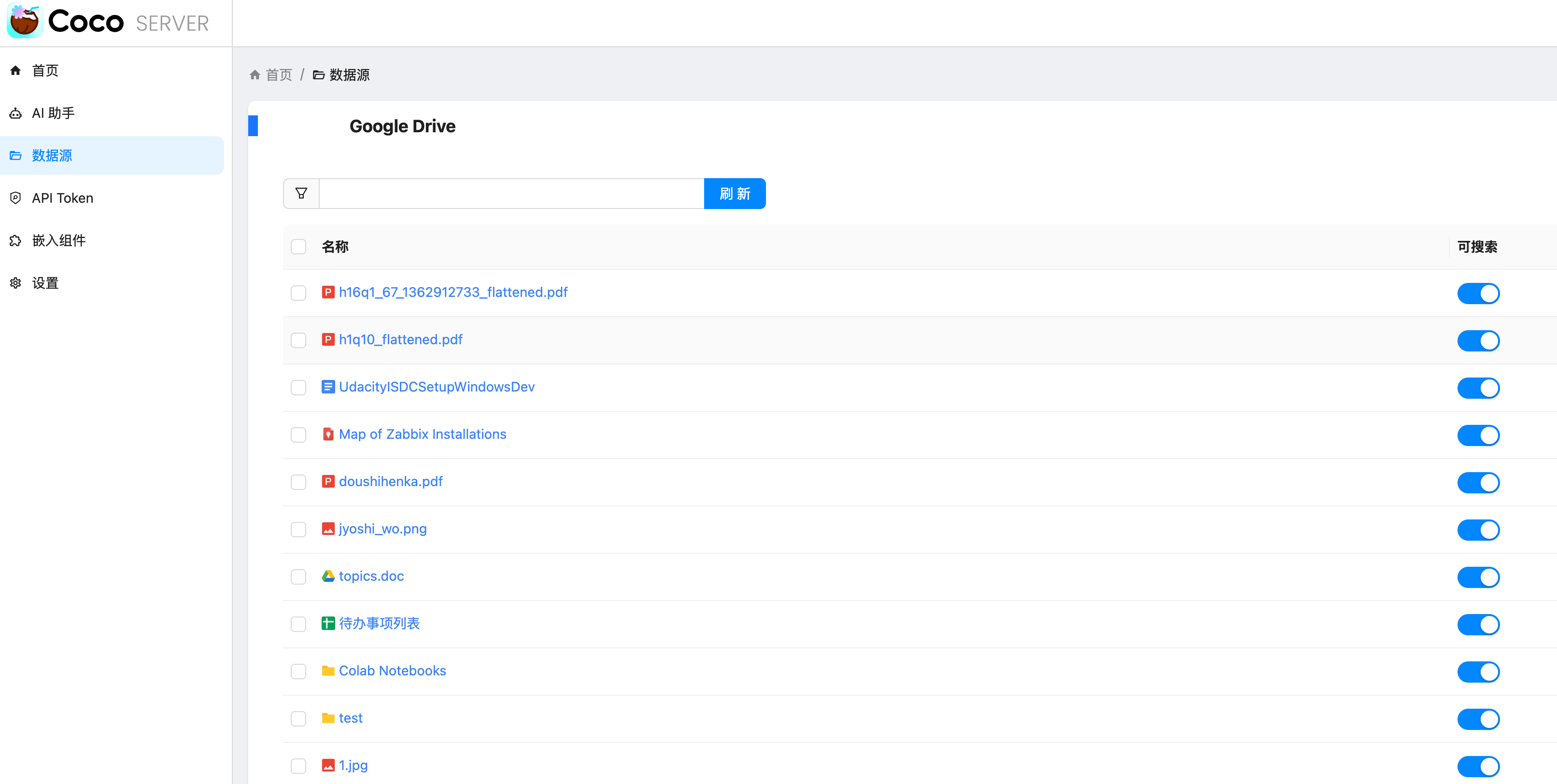
Coco-AI 接入自定义数据源
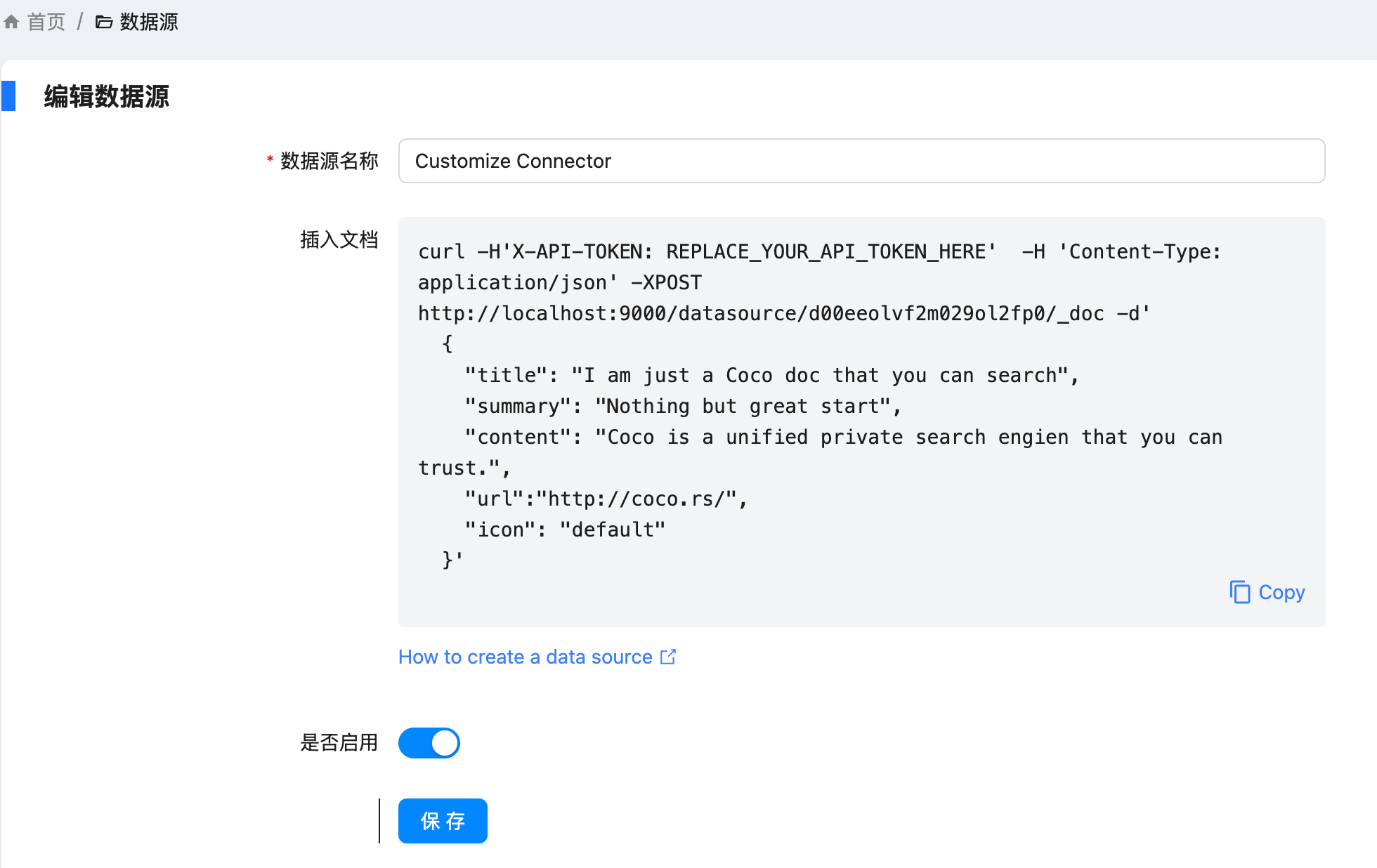
https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai 之前使用 Hugo Connector 接入和 hexo 和任意 Markdown,后来官方也支持了对于任意数据源的支持,主要是开放了这个接口:  具体操作如下: <!-- more --> 设置 - conntor - 新增,让输入名称和描述等信息,新建出来 conntor 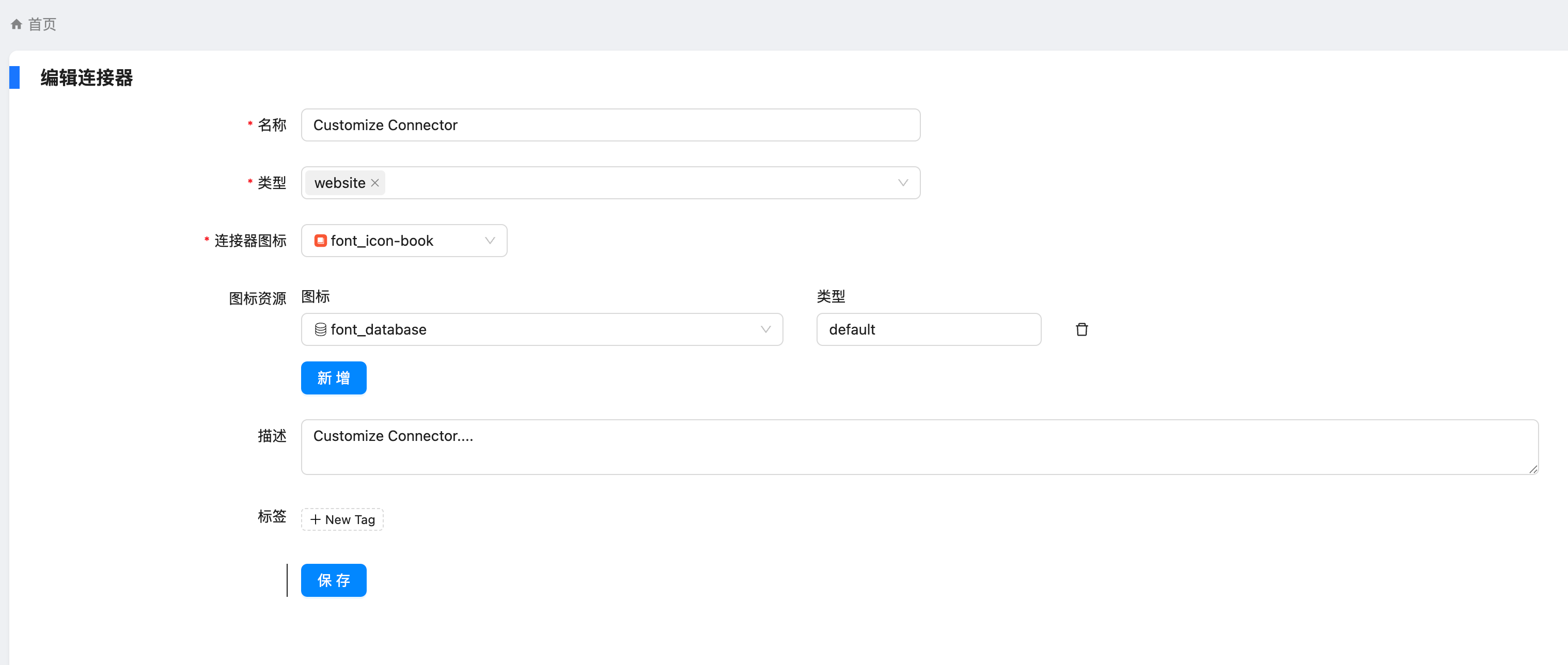 然后我们就能在数据源上的页面上看到刚刚添加的了 Customize Connector 了 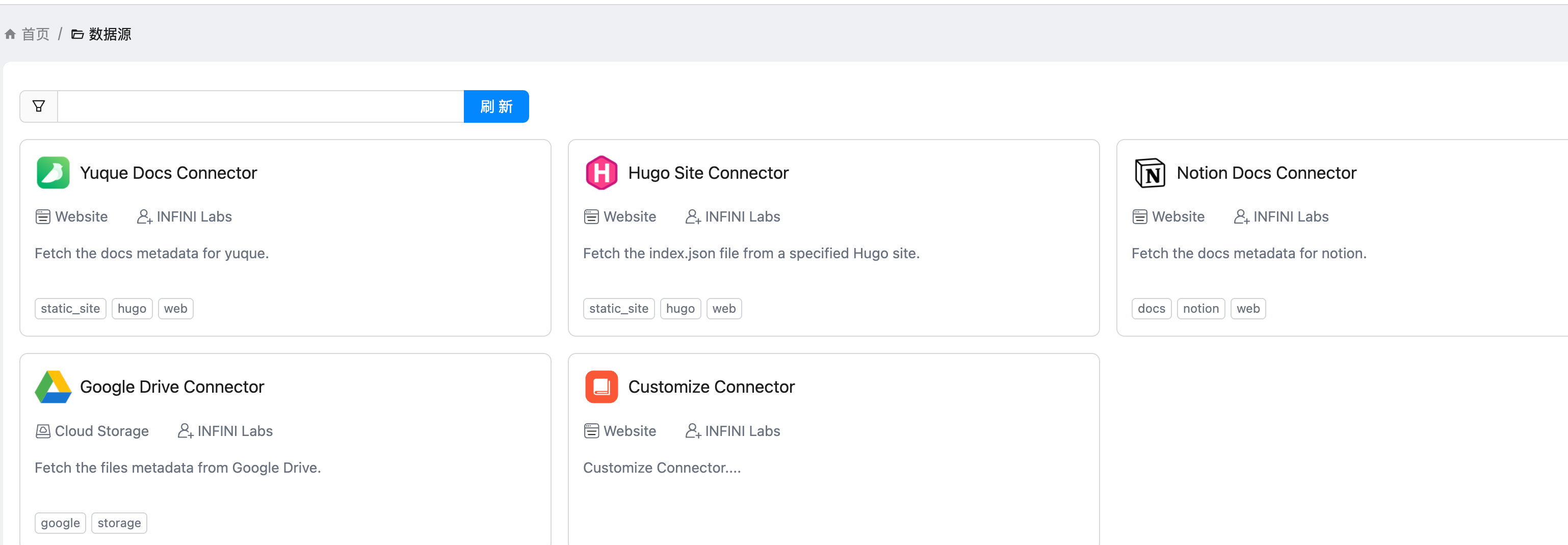 点开提示,给了一个 API  然后我们去创建 token,如图 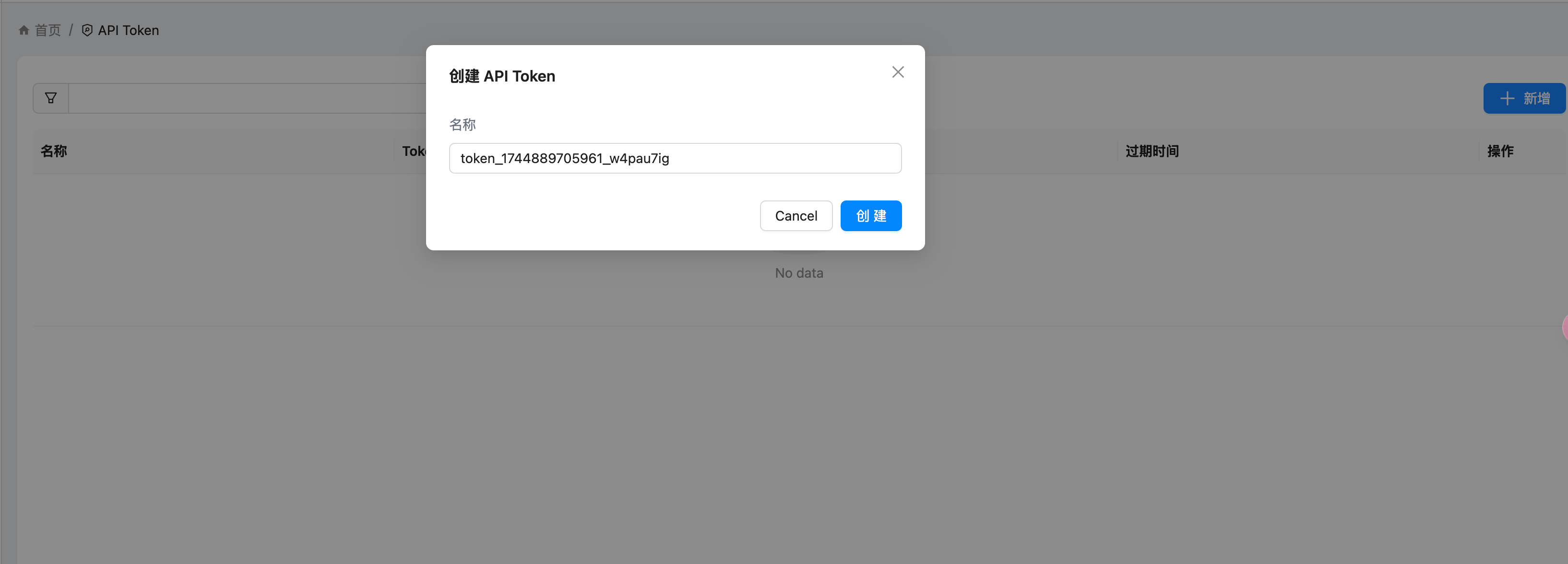 我这边使用 Postman 进行设置 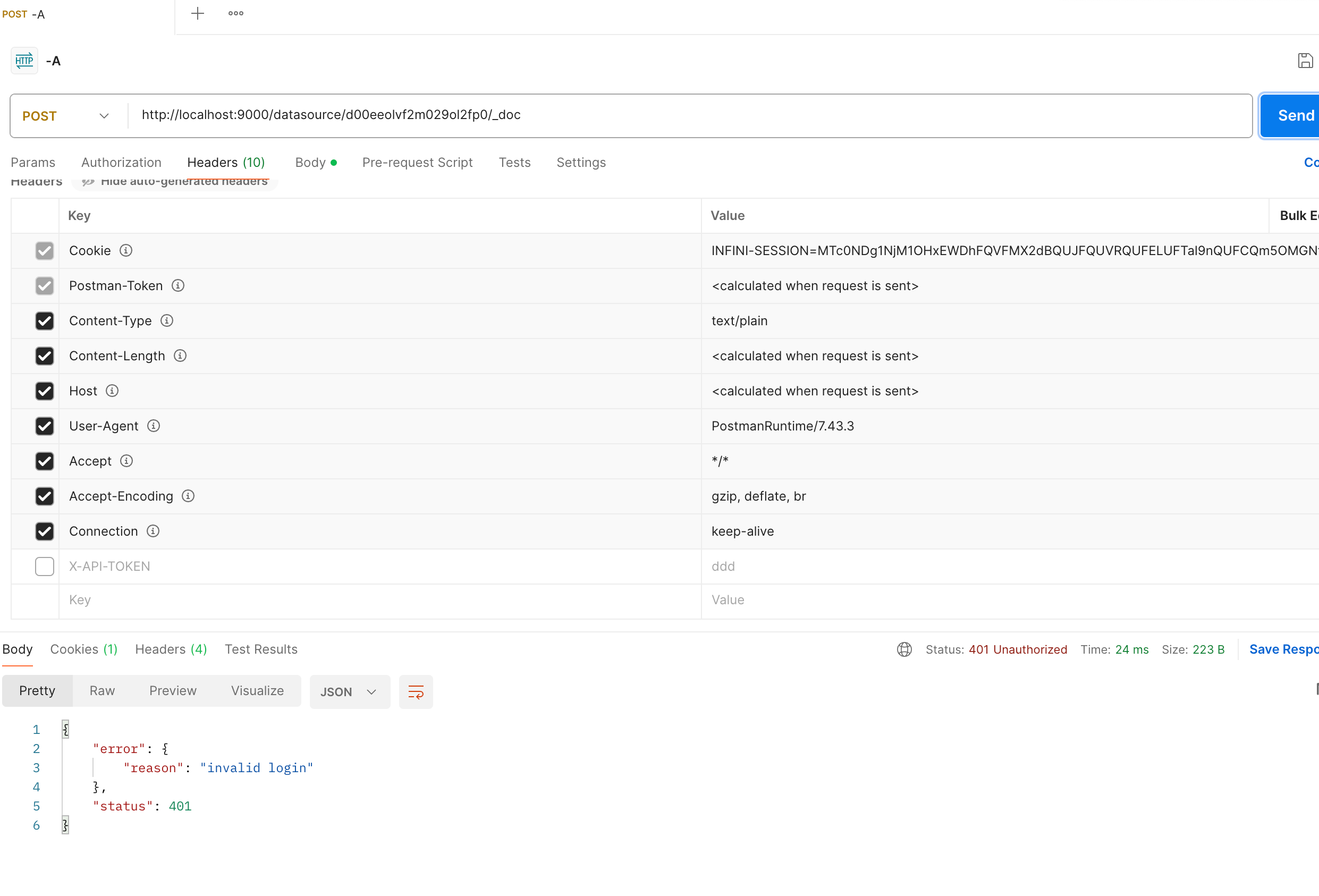 如果你的请求没有带 token,就是这样的。  转成代码的是这样的,当然也可以开发自己的 agent。 ```python import requests import json url = "http://localhost:9000/datasource/d00eeolvf2xxx/_doc" payload = json.dumps({ "title": "I am just a Coco doc that you can search", "summary": "Nothing but great start", "content": "Coco is a unified private search engien that you can trust.", "url": "http://coco.rs/", "icon": "default" }) headers = { 'Content-Type': 'application/json' } response = requests.request("POST", url, headers=headers, data=payload) print(response.text) ```
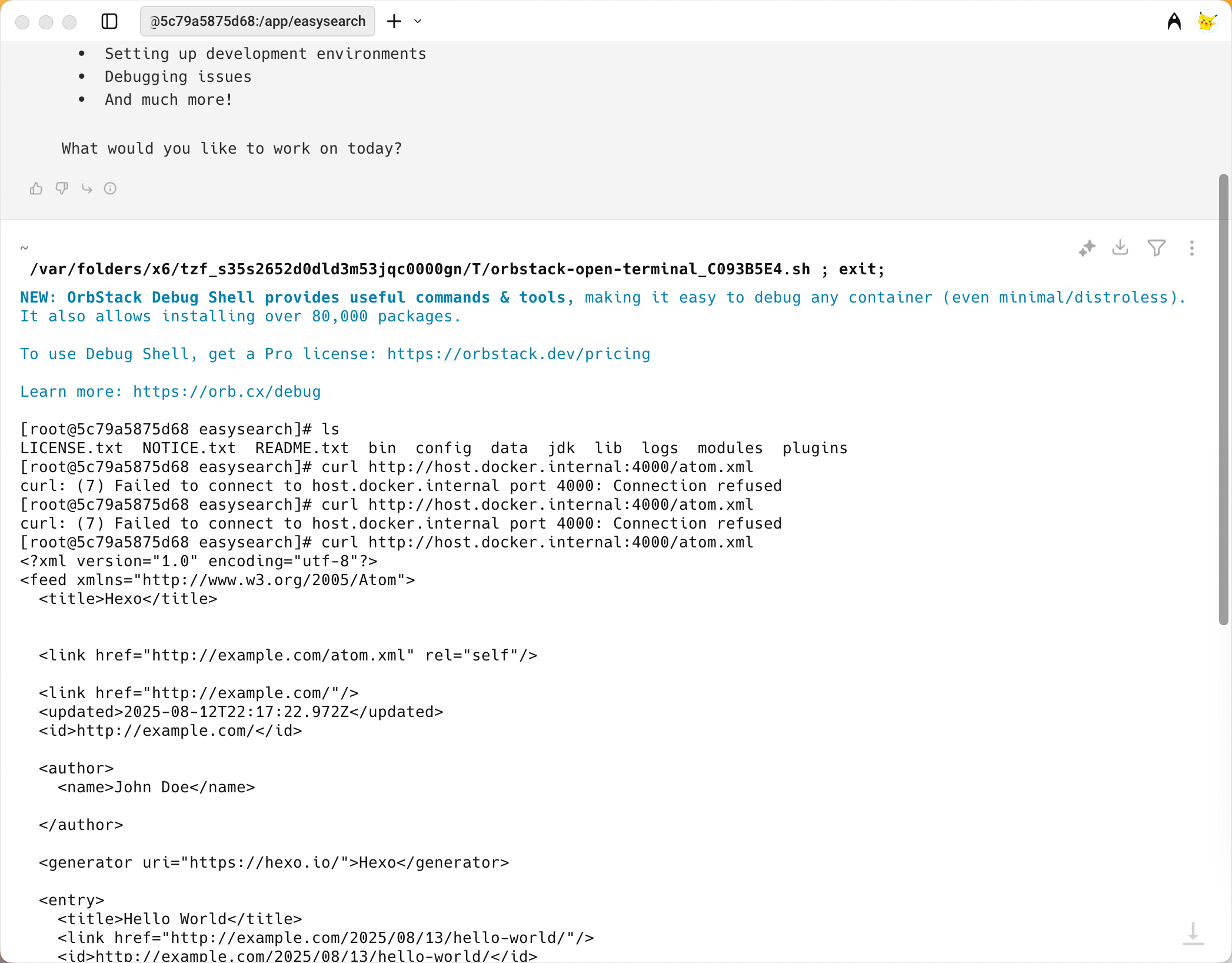
容器运行 Coco AI,如何访问宿主机的 localhost?
使用容器确实方便了很多事情,但在网络访问上可能会引出一些麻烦。 如果你的调试服务只监听在宿主机的 `localhost`,那么在容器里访问时,会找的是**容器自己的 localhost**,所以无法连通。 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai https://appstore.lazycat.cloud/#/shop/detail/xu.infinilabs.console 因为无论是 Coco server 还是 Console 都是服务端发送请求,所以我统一记录下来。 下面介绍几种在不同环境下的解决方案。 ## 1. Mac 的 Orbstack 在 **Orbstack** 环境中,可以使用 `host.docker.internal` 代替宿主机的 `localhost`。 例如访问宿主机的 Hexo 服务(`http://localhost:4000/atom.xml`)时,直接这样写: ```bash http://host.docker.internal:4000/atom.xml ``` <!-- more --> `host.docker.internal` 会被解析到宿主机 IP,相当于容器内部的 “localhost”。  ## 2. Linux 下单容器运行 在 Linux 环境中,`host.docker.internal` 默认可能不可用,可以用以下方法: ### 方法 1:`--add-host` 运行容器时显式添加: ```bash docker run --add-host=host.docker.internal:host-gateway ... ``` 容器里访问: ```bash curl http://host.docker.internal:4000/atom.xml ``` ### 方法 2:`--network host` 在本地调试时让容器和宿主机共用网络命名空间: ```bash docker run --network host ... ``` 这样容器里的 `localhost:4000` 就等于宿主机的 `localhost:4000`。 ⚠️ 缺点:端口可能冲突,不建议在生产环境使用。 --- ## 3. Docker Compose 下多容器访问宿主机 在 **Linux + docker-compose** 场景下,容器访问宿主机的 `localhost` 同样需要绕过。可以使用以下几种方式(推荐优先使用前两种): ### 方案 1:`host.docker.internal` ```yaml version: "3.8" services: myservice: image: your-image extra_hosts: - "host.docker.internal:host-gateway" ``` 容器里访问: ```bash curl http://host.docker.internal:4000/atom.xml ``` ### 方案 2:Docker 网桥网关 IP Linux 默认 `docker0` 网桥的宿主机 IP 通常是 `172.17.0.1`,可用以下命令确认: ```bash ip addr show docker0 ``` 容器里直接访问: ```bash curl http://172.17.0.1:4000/atom.xml ``` ⚠️ 缺点:如果 Docker 网络结构改动,IP 可能变化。 ### 方案 3:`network_mode: host` ```yaml services: myservice: image: your-image network_mode: host ``` 容器内的 `localhost:4000` 直接访问宿主机服务。 ⚠️ 缺点同上,失去网络隔离,端口冲突风险高。 ### 方案 4:绑定 Hexo 到 `0.0.0.0` 并用局域网 IP 容器里访问: ```bash curl http://192.168.x.x:4000/atom.xml ``` 其中 `192.168.x.x` 为宿主机的局域网 IP。 💡 **建议**:如果 Compose 版本 ≥ 3.4,优先使用 **方案 1**。写死 `host.docker.internal` 后,即使宿主机 IP 变化,也能稳定访问。 通过上面的几种方式,无论是在 **Orbstack**、**Linux 单容器** 还是 **Docker Compose** 场景下,都能找到合适的方法让容器访问宿主机的 `localhost` 服务。 日常调试时,推荐优先使用 `host.docker.internal`(配合 `--add-host` 或 Compose 的 `extra_hosts`),既稳定又无需记 IP; 在容器之间互访,则直接使用 **服务名/容器名**,让 Docker 自带的 DNS 帮你解析。 掌握这些技巧,既能让 Coco AI 的调试环境跑得顺畅,也能为后续复杂的容器网络架构打好基础。
Coco-AI 集成语雀作为语料库进行检索
说在前面,这个功能需要在语雀后台申请 Personal Access Token。使用的需要超级会员的(不是邀请新用户给的专业会员),所以需要付费使用。 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai  <!-- more --> 然后在语雀后台,也就是https://www.yuque.com/settings/tokens处可以看见申请token的地方,如果你没有超级会员,这个是没办法用的。 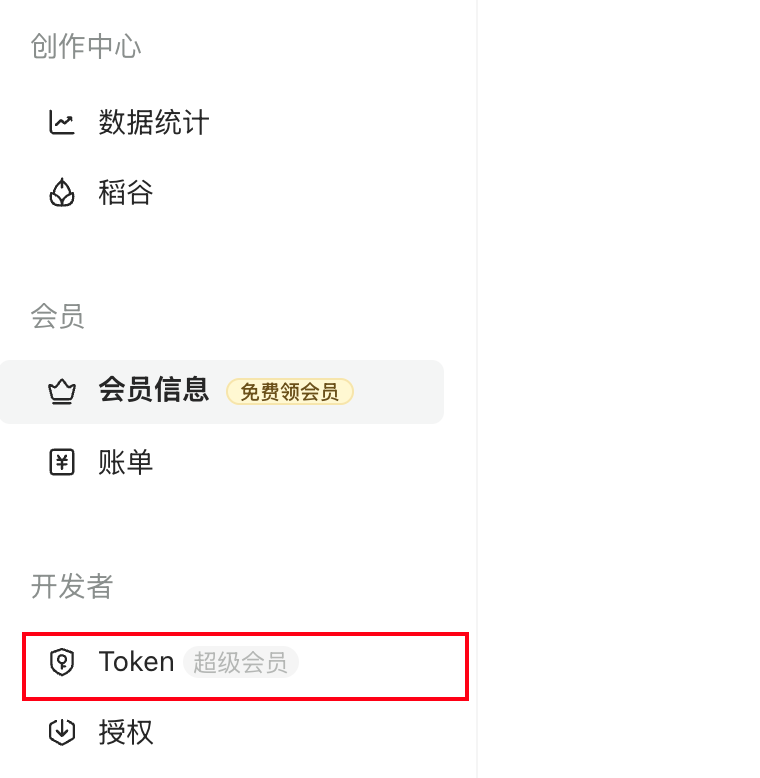 点击新建,创建 token 分发权限,我这边给了所以的权限,语雀和 Notion 不同,这里给了权限就够了,其他地方无需在给权限。(手动@Notion 还要在文档或者文件夹授权) 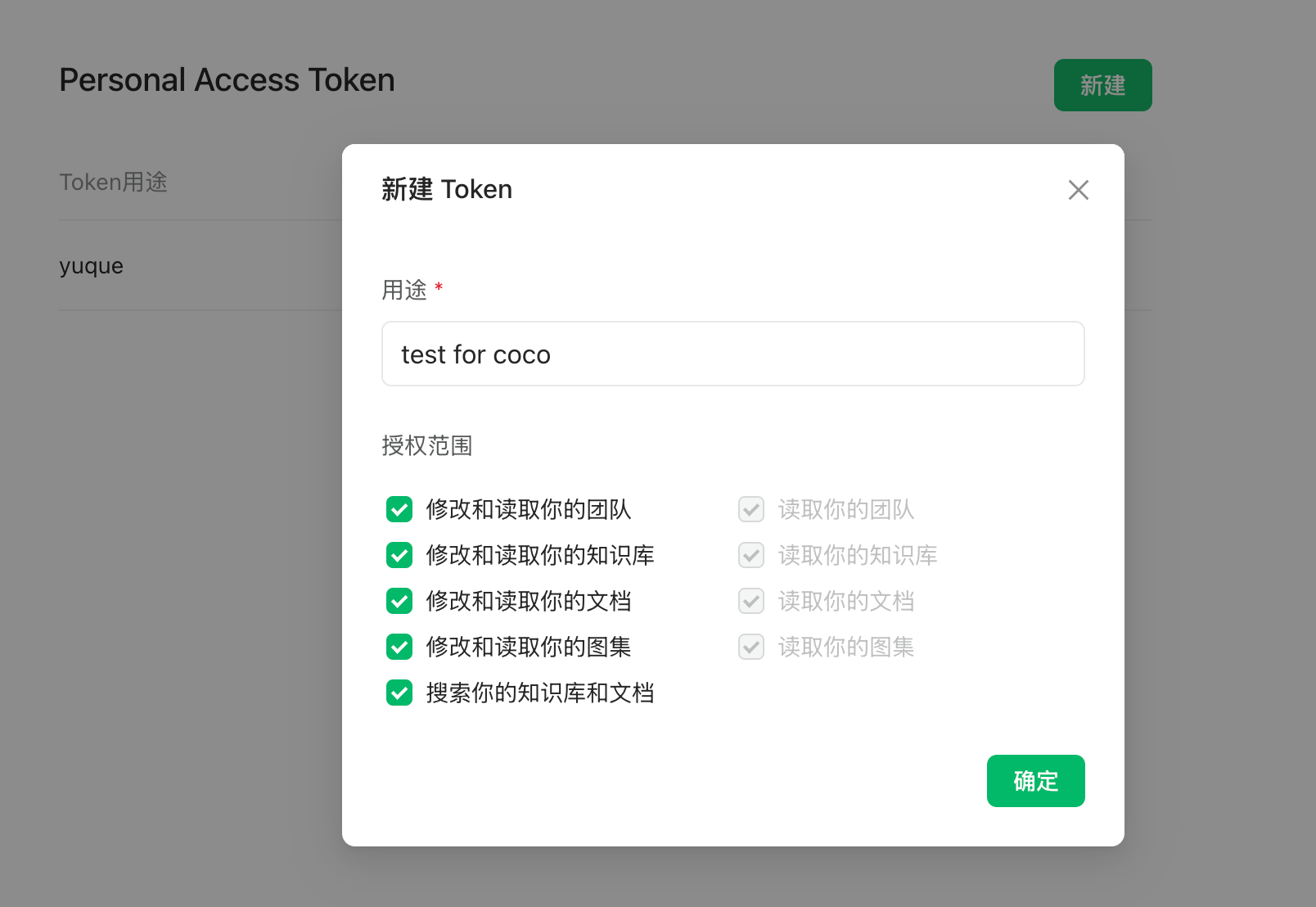 点击查看详情可以看到 token,这里的 token 是可以反复查看的,由此语雀这一侧的设置完毕。 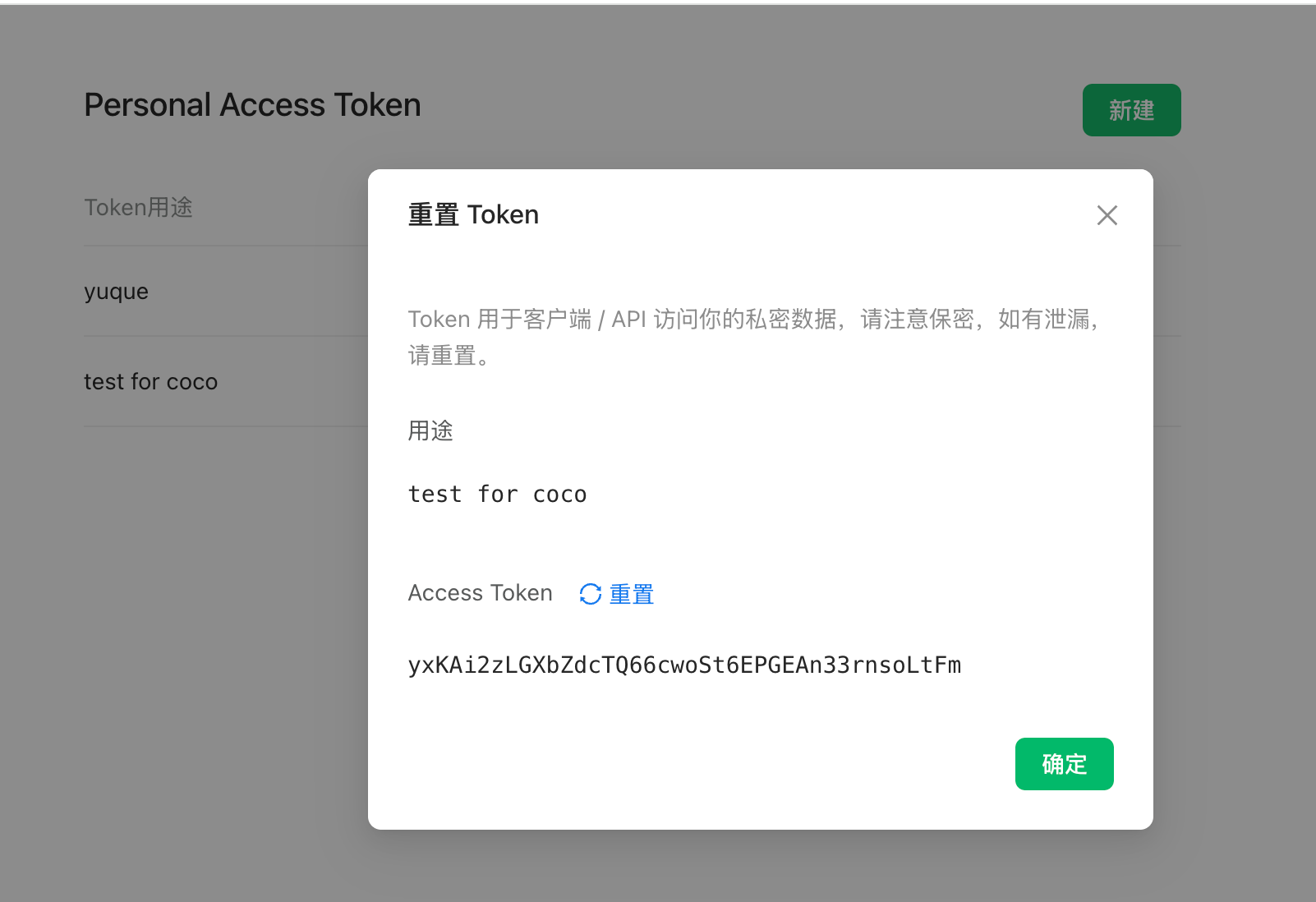 回到 coco-AI,我这边使用的是这个镜像,这里添加了对个人版本语雀的支持。 ```bash infinilabs/coco:0.3.2_NIGHTLY-20250417 ``` 启动命令如下: ``` docker run -d --name cocoserver -p 9000:9000 infinilabs/coco:0.3.2_NIGHTLY-20250417 ``` 然后进入后台初始化模型,我这里使用的本地部署的 deepseek: 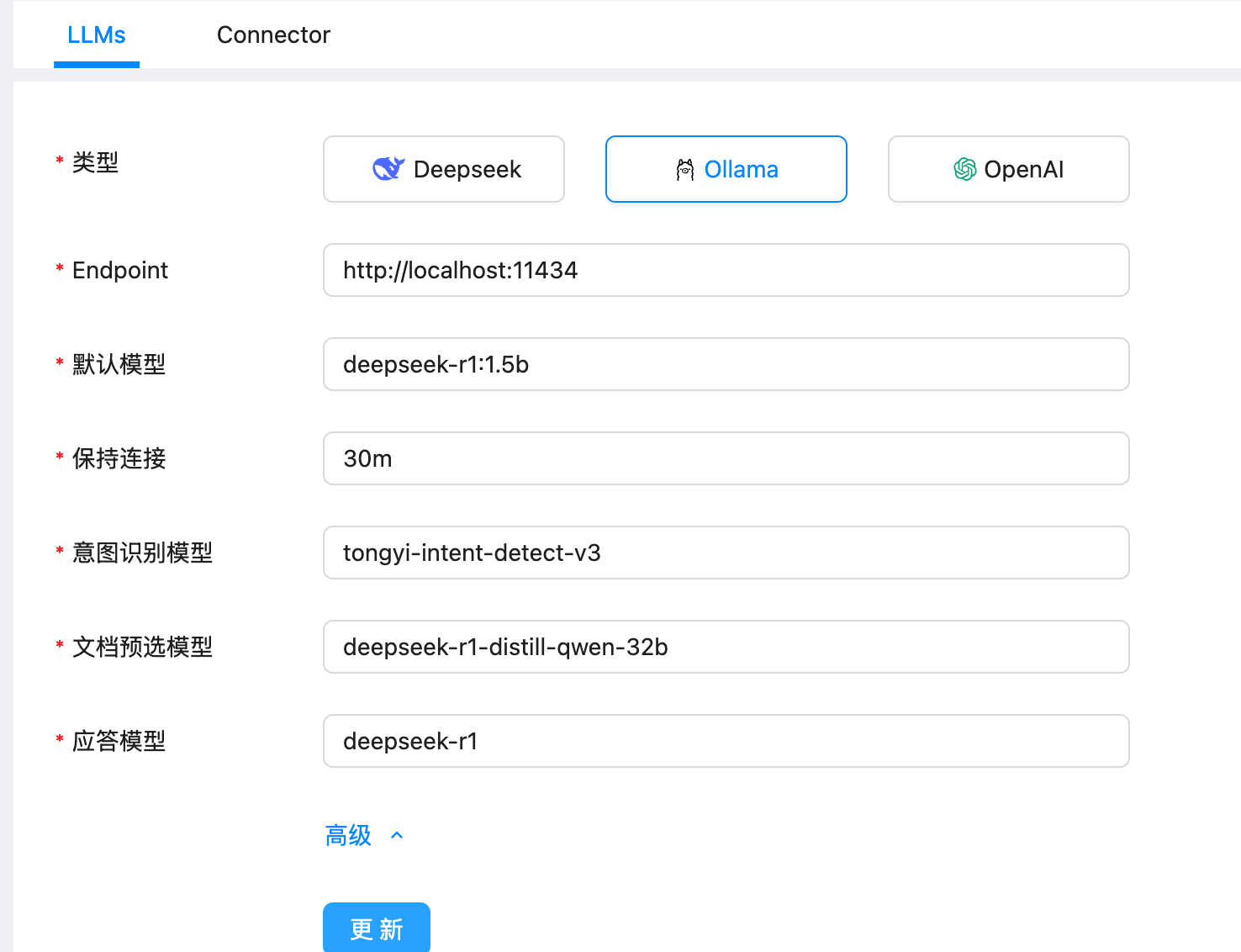 点击数据源,选择 yuque connector 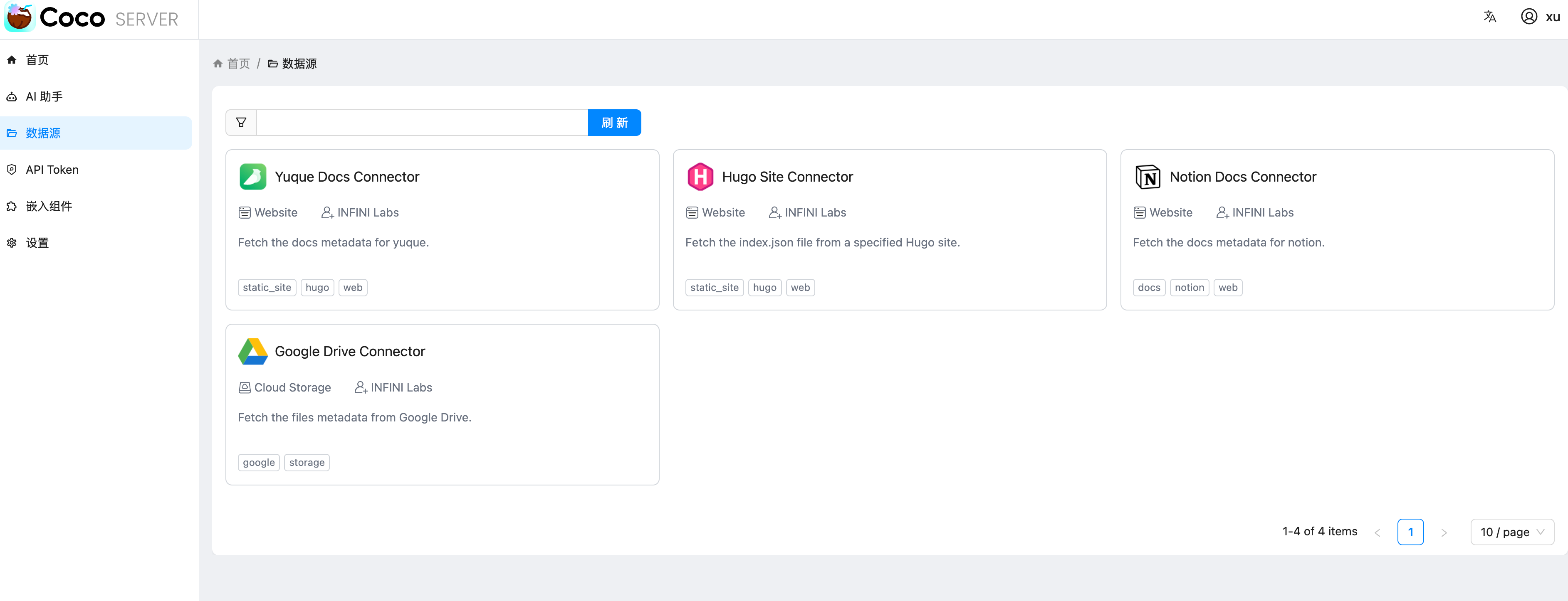 配置的地方很简单,填入数据源名称和 Token 和刷新时间。 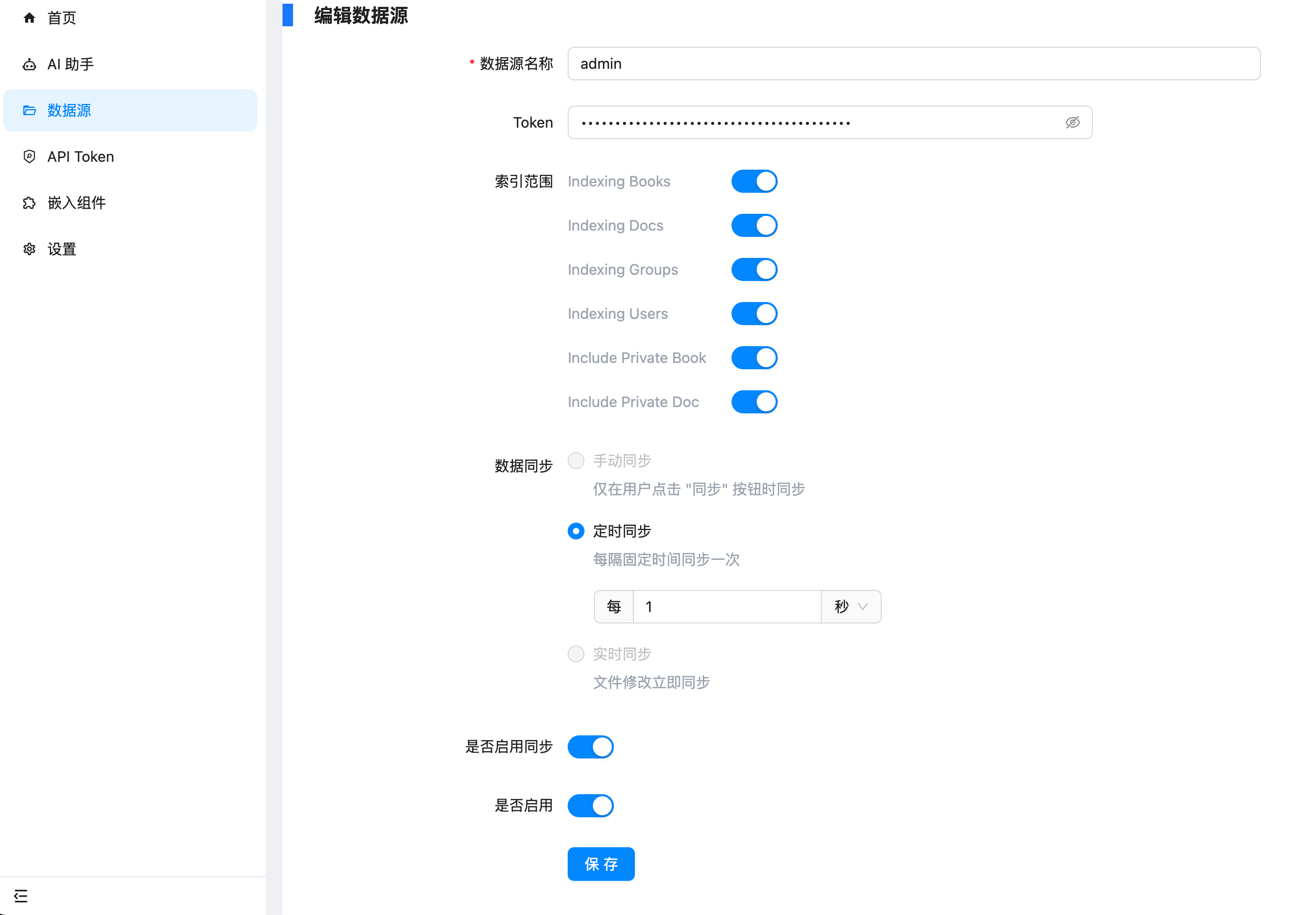 然后我们就可以看到刷新的数据了 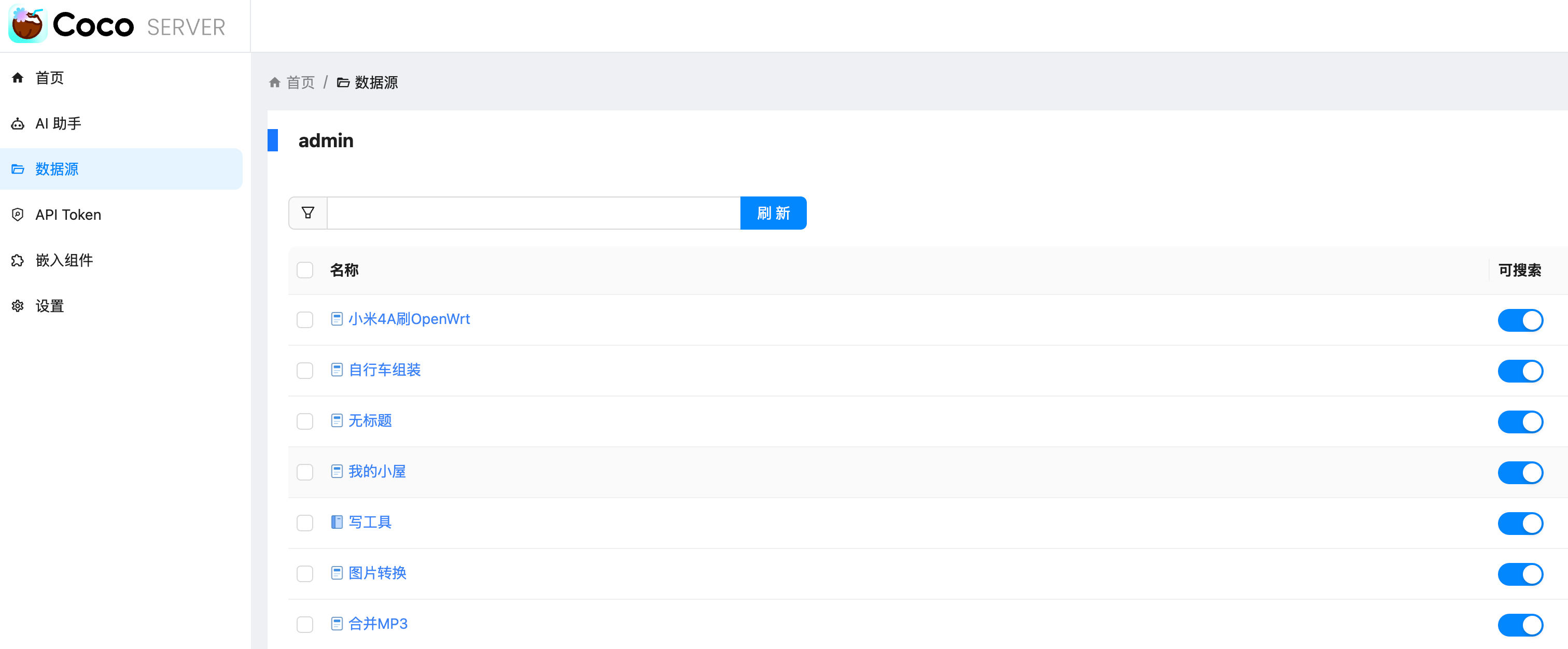
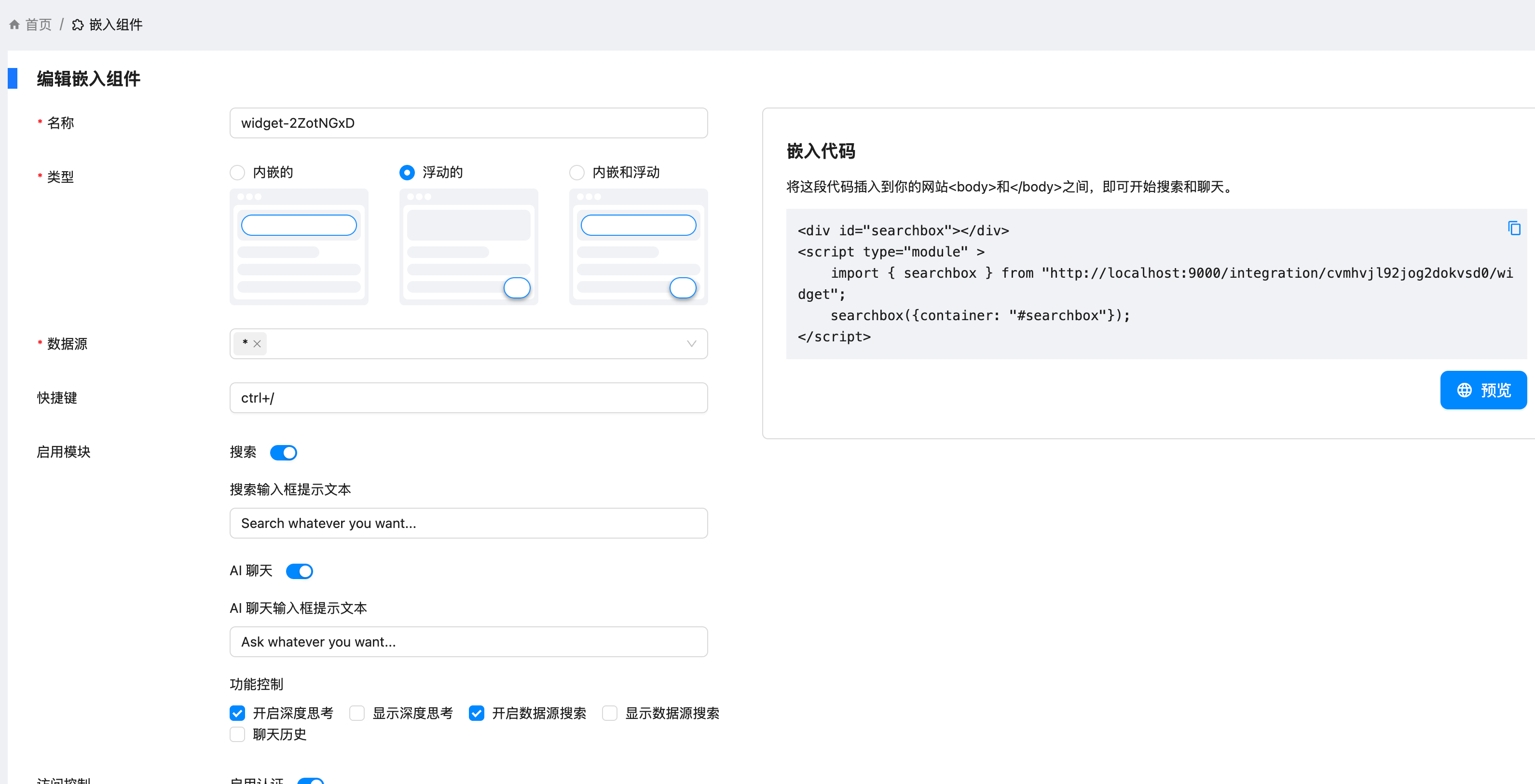
Coco-AI 支持嵌入,让你的网站拥有 AI 搜索力
在之前的文章中,我们让 Hexo,hugo 博客 支持了 coco AI 检索,也就是说我们还得使用客户端来检索,那是不是把搜索放在博客上呢? https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.coco-ai Coco-AI 在 0.3 的版本中  --- 先找一个 html 来看个效果。 ```html <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8" /> <title>搜索组件嵌入示例</title> <style> body { font-family: sans-serif; padding: 2rem; } #searchbox { margin-top: 20px; border: 1px solid #ccc; padding: 16px; border-radius: 8px; } </style> </head> <body> <h1>欢迎使用 Cloudsmithy 搜索组件</h1> <p>下面是通过 ES Module 引入的搜索框:</p> <div id="searchbox"></div> <script type="module"> import { searchbox } from "http://localhost:9000/integration/cvmhvjl92jog2dokvsd0/widget"; searchbox({ container: "#searchbox", }); </script> </body> </html> ``` ## 💡 原始代码: ```html <div id="searchbox"></div> <script type="module"> import { searchbox } from "http://localhost:9000/integration/cvmhvjl92jog2dokvsd0/widget"; searchbox({ container: "#searchbox" }); </script> ``` --- ## 🧩 每部分解析 ### 1. `<div id="searchbox"></div>` 这是一个空的 `div` 元素,作为**挂载容器**。你的 `searchbox` 组件会被渲染进这个 `div`。 - 就像 React 或 Vue 应用会挂载到 `<div id="app">` 一样 - 你在这里指定了 id 为 `searchbox`,用于后面初始化组件时绑定 --- ### 2. `<script type="module">` 这表示:这是一个 **ES Module 格式的 JavaScript 脚本**。 - 现代浏览器支持原生的模块化加载(无需打包器) - 可以使用 `import` 加载其他模块、组件 --- ### 3. `import { searchbox } from "http://localhost:9000/integration/cvmhvjl92jog2dokvsd0/widget";` 从远程地址(本地服务器)中导入 `searchbox` 函数: - 说明这个 URL 返回的是一个 JavaScript 模块,里面导出了 `searchbox` - 类似 Vue、React 中的组件库导入: ```js import { Button } from "element-plus"; ``` --- ### 4. `searchbox({container: "#searchbox"});` 调用 `searchbox` 函数,初始化组件,并挂载到页面中: - 参数是一个对象,指明组件要渲染在哪个 DOM 元素里 - `container: "#searchbox"` 通过 CSS 选择器指定了上面那个 `div` --- ## 🧠 通俗类比 就像你在网页上写: ```html <div id="chat"></div> <script type="module"> import { chatWidget } from "./chat.js"; chatWidget({ container: "#chat" }); </script> ``` 它就是在某个 `div` 中挂载一个聊天插件一样。你这段代码的本质就是嵌入并运行一个远程提供的 JS 组件。 --- ## ✅ 总结一句话: 这段代码的作用是: > **把远程加载的 `searchbox` 组件挂载到网页上的 `<div id="searchbox">` 中,完成动态插入功能。** --- 如果你希望我反向帮你写出那个 `searchbox` 模块怎么写,或者做成本地文件测试,也可以告诉我~ 下面是一个可以在任意网站自动嵌入你给出的 `<div>` 和 `<script>` 的油猴(Tampermonkey)脚本示例: --- ### ✅ 功能说明 - 在页面加载完成后,向 `<body>` 插入一个 `#searchbox` 的 `div` - 加载你的远程模块并初始化 `searchbox` 组件 --- 一开始打算在 hexo 的组件上改,但是在编译阶段有问题,索性使用油猴脚本来实现 ### 🐵 Tampermonkey 脚本示例 ```javascript // ==UserScript== // @name Searchbox Embedder // @namespace http://tampermonkey.net/ // @version 0.1 // @description 在任意网页中注入 searchbox 小部件 // @author You // @match *://*/* // @grant none // @run-at document-end // ==/UserScript== (function () { "use strict"; // 创建 searchbox 容器 const searchboxDiv = document.createElement("div"); searchboxDiv.id = "searchbox"; document.body.appendChild(searchboxDiv); // 动态加载模块脚本(ESM) const script = document.createElement("script"); script.type = "module"; script.textContent = ` import { searchbox } from "http://localhost:9000/integration/cvmhvjl92jog2dokvsd0/widget"; searchbox({ container: "#searchbox" }); `; document.body.appendChild(script); })(); ``` --- ### ⚠️ 注意事项 1. 浏览器必须支持 ES Module。 2. 若该域名不是 HTTPS,确保目标网页也是 HTTP,否则会被浏览器拦截跨协议内容。 3. 若需局部生效,请将 `@match` 改为具体的页面,例如:`https://example.com/*` --- --- ## 🌟 脚本整体作用 这个油猴脚本的作用是:**在任何网页上自动插入一个 `div#searchbox` 容器,并加载你提供的远程模块脚本,渲染搜索框组件**。 --- ## 📜 脚本逐行解析 ```javascript // ==UserScript== // @name Searchbox Embedder ``` - `@name` 是脚本的名字,显示在 Tampermonkey 的控制面板中。 ```javascript // @namespace http://tampermonkey.net/ ``` - 命名空间,可以用来区分多个脚本的作者或用途(不重要)。 ```javascript // @version 0.1 ``` - 脚本版本号。 ```javascript // @description 在任意网页中注入 searchbox 小部件 ``` - 简要说明这个脚本做什么。 ```javascript // @author You ``` - 作者名,可以改成你自己的。 ```javascript // @match *://*/* ``` - 匹配所有网站页面。如果你只想对某个特定网站注入,可将它改为: `// @match https://example.com/*` ```javascript // @grant none ``` - 没有使用 Tampermonkey 的特殊权限(如 GM\_\* 方法),所以可以写 `none`。 ```javascript // @run-at document-end ``` - 脚本在 DOM 加载完成后执行(类似 `DOMContentLoaded`)。 --- ## 💻 主体逻辑解析 ```javascript (function () { 'use strict'; ``` - 启用严格模式,避免某些低级错误。 ```javascript // 创建 searchbox 容器 const searchboxDiv = document.createElement("div"); searchboxDiv.id = "searchbox"; document.body.appendChild(searchboxDiv); ``` - 创建一个 `<div id="searchbox">` 并插入到 `<body>` 中,作为挂载点。 ```javascript // 动态加载模块脚本(ESM) const script = document.createElement("script"); script.type = "module"; ``` - 创建一个新的 `<script type="module">`,用来加载 ES 模块。 ```javascript script.textContent = ` import { searchbox } from "http://localhost:9000/integration/cvmhvjl92jog2dokvsd0/widget"; searchbox({ container: "#searchbox" }); `; ``` - 直接把模块内容写入 script 标签中: - 从你本地地址加载 `searchbox` 组件 - 调用 `searchbox({ container: "#searchbox" })` 初始化它 ```javascript document.body.appendChild(script); })(); ``` - 把这个 `<script type="module">` 插入到 `<body>` 中,触发模块加载和执行。 --- ## ✅ 总结 这个脚本做了三件事: 1. 在网页中插入一个 `div#searchbox` 2. 动态加载你本地的模块组件 3. 初始化这个组件并挂载到 `#searchbox` 上 --- 你如果希望它在某些页面不显示、加个按钮控制显示、支持浮窗、带样式等等,我也可以帮你升级脚本。需要的话告诉我你的想法~
懒猫评分/评论
4.0
2 条评论
应用信息
新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
更新到了0.8的版本。不兼容以前的数据,需要备份
忘机山人
10/7/2025
已经提交0.8版本的更新,不兼容以前的版本,需要备份数据。
smallzhan
9/15/2025
这个版本 0.5.0, 攻略里面讲的 rss 和本地的 connector 都没有,可以升级吗。