
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

Coco-AI × Amazon S3:秒搜你的云端文件
忘机山人
随着企业和个人数据量的激增,如何高效管理与搜索云端资料,成为提升工作效率的关键。
Coco-AI 新增的 S3 对象存储连接器,可以将 Amazon S3 存储桶直接接入智能检索系统,实现秒级搜索、即时访问,让云端文件像本地文档一样触手可及。
本篇将详细介绍如何通过 Docker 快速部署 Coco Server,并配置 S3 连接器,完成与亚马逊云科技的无缝集成。
一、快速部署 Coco Server
Coco Server 是连接器功能的运行核心,部署好它后才能接入 S3。
生产环境建议使用持久化存储方式,避免数据丢失。
在应用商店中下载
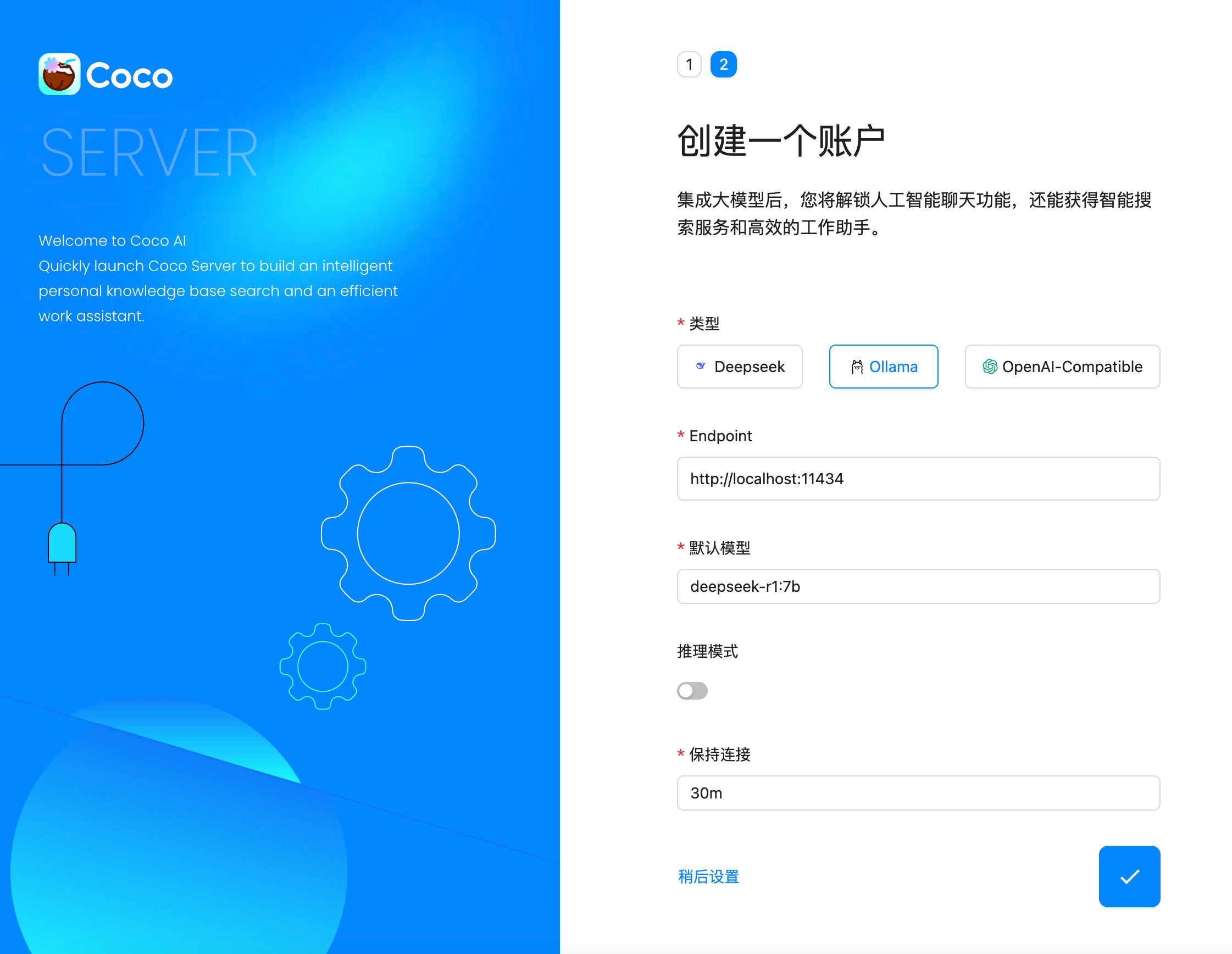
二、配置 AI 模型
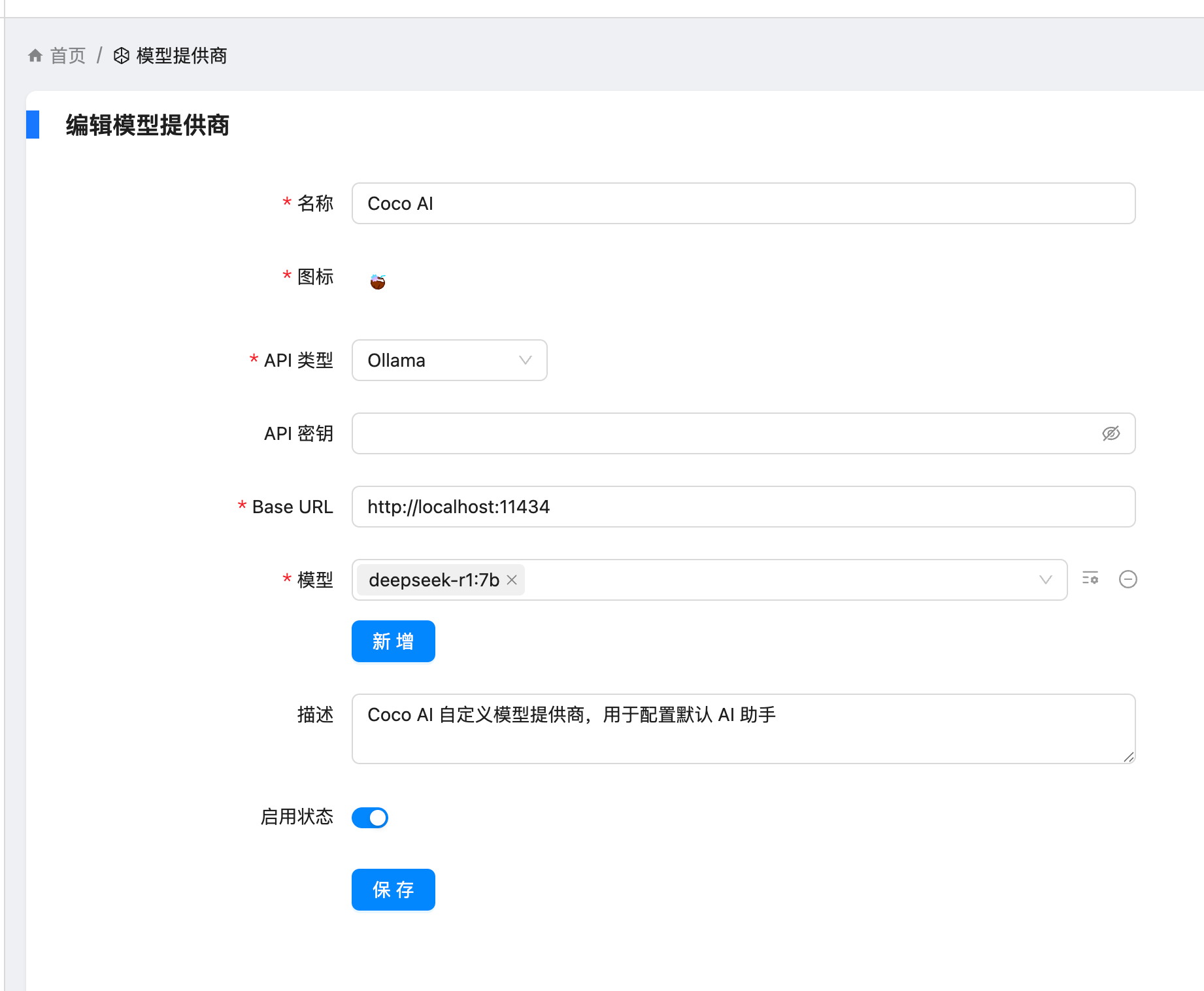
创建用户后,我选择 Ollama 作为模型提供商:
- 地址:
http://localhost:11434 - 模型:
deepseek-r1:7b
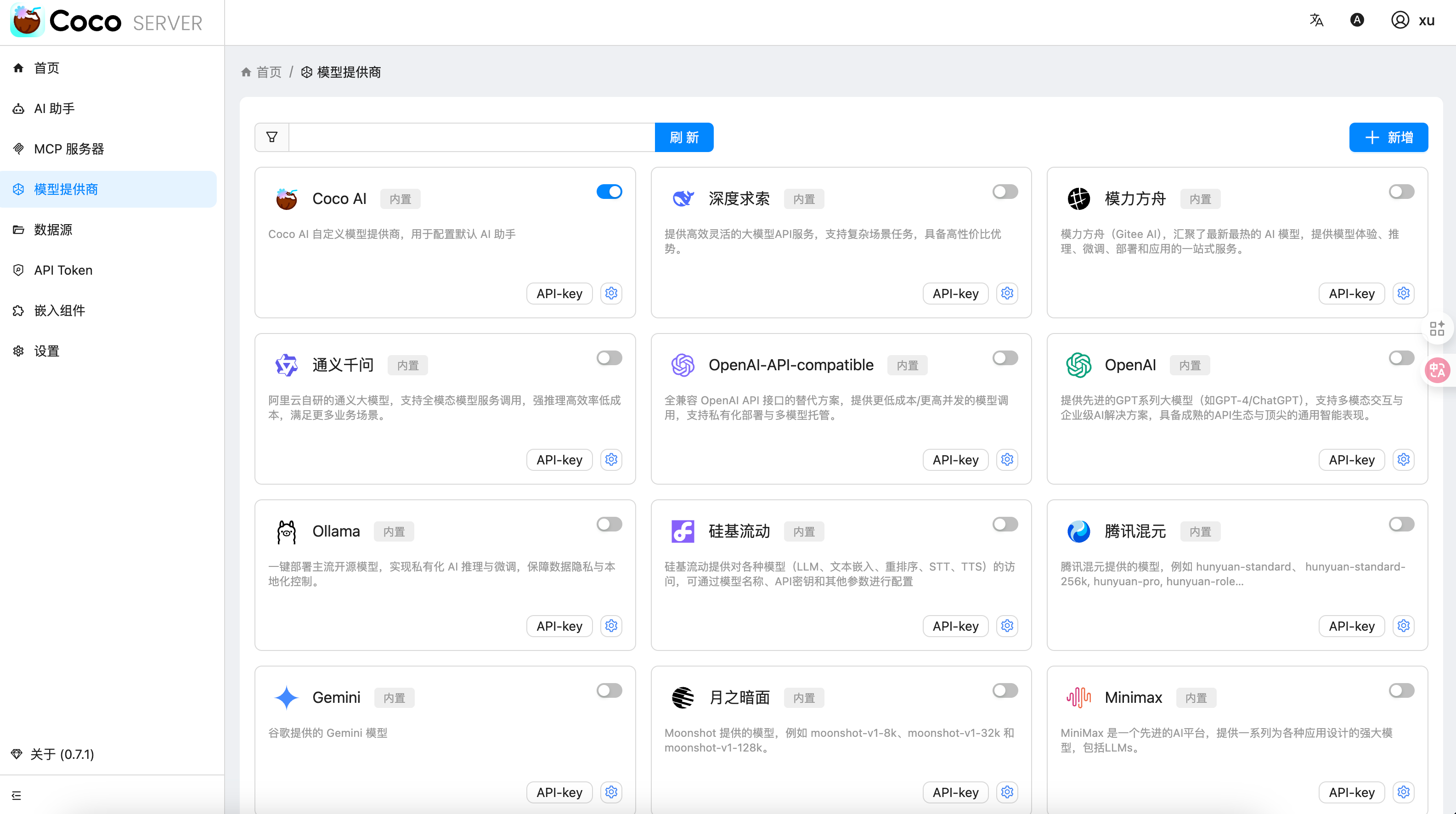
在「模型提供商」界面可以看到默认开启的 Coco AI,它会直接调用我配置的 Ollama,也支持其他兼容 OpenAI API 的 LLM。
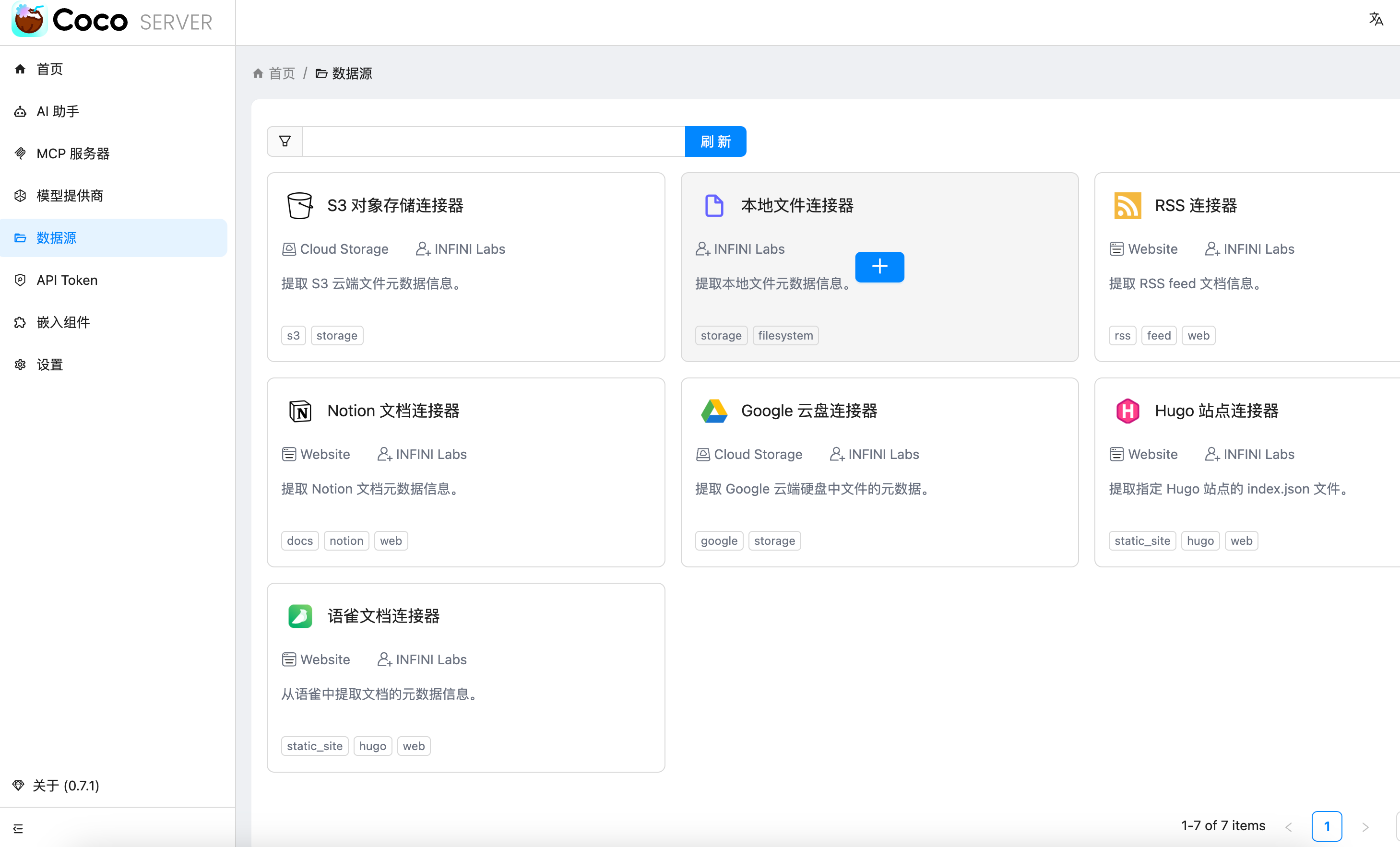
三、数据源概览
Coco-AI 默认内置官方文档和 Hacker News 数据源,近期新增三类连接器:
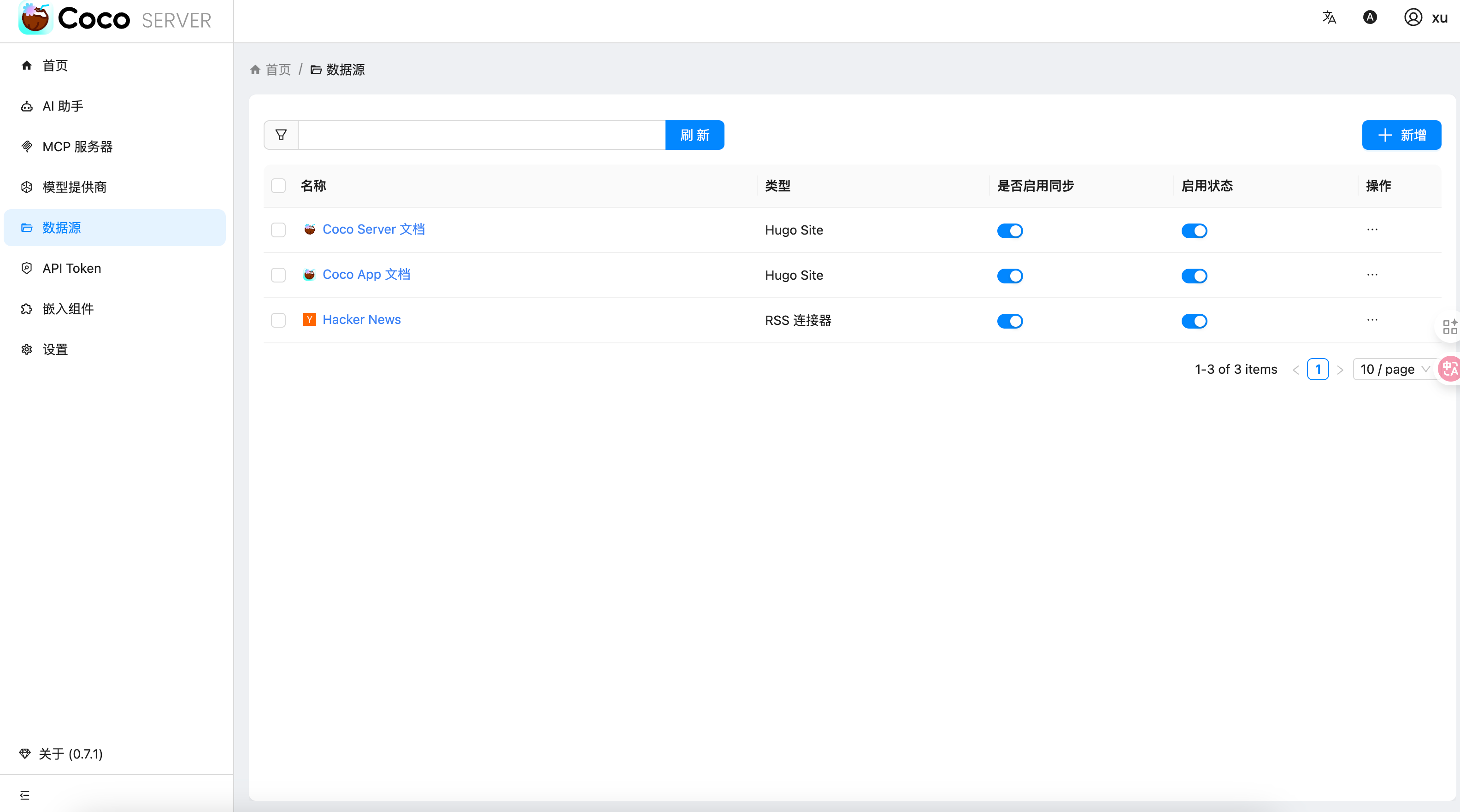
- S3 连接器(本篇重点)
- 本地文件连接器
- RSS 连接器
四、接入 Amazon S3
-
选择 S3 对象存储连接器
填写 Endpoint(例:东京区s3.ap-northeast-1.amazonaws.com)、Bucket 名称、亚马逊云科技凭证(Access Key ID / Secret Access Key),刷新间隔建议保持 1 分钟 默认值。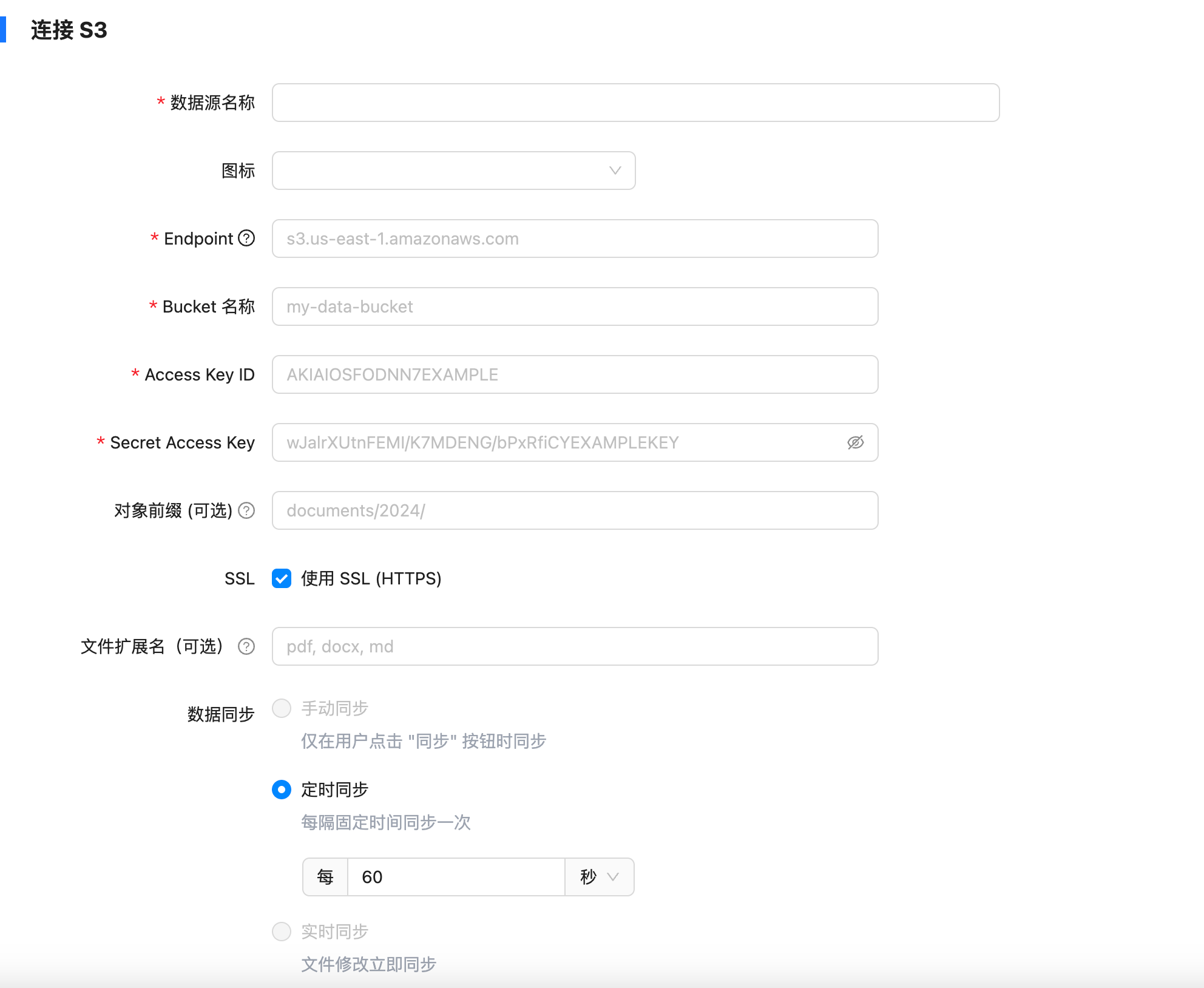
-
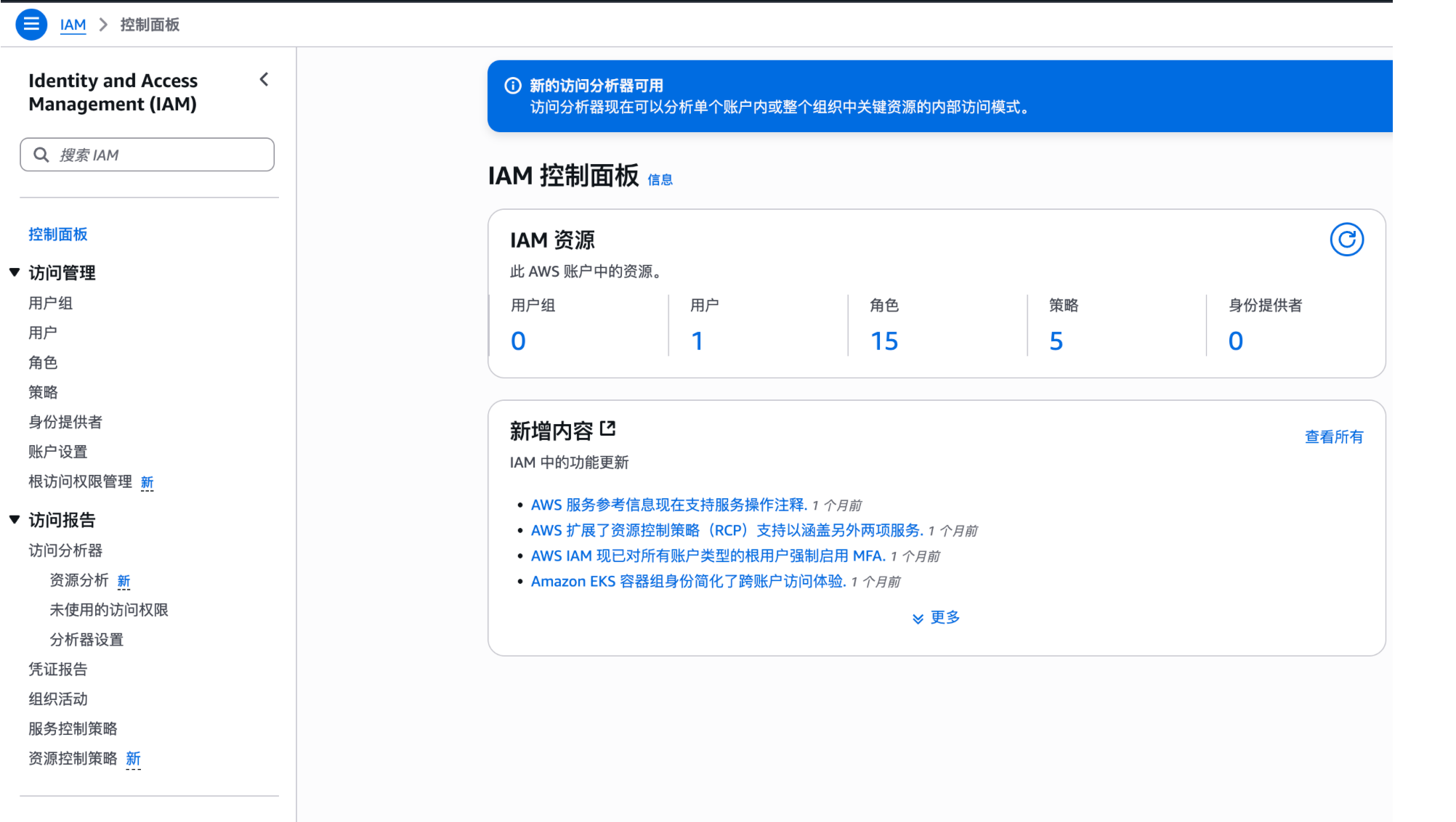
获取亚马逊云科技访问凭证
- 登录 亚马逊云科技 IAM 控制台
- 创建访问密钥(Access Key ID / Secret Access Key)
- 为用户分配最小化 S3 访问权限(推荐遵循最小权限原则)
这里选择访问密钥 - 创建访问密钥,然后保存 Access Key ID / Secret Access Key 就好。
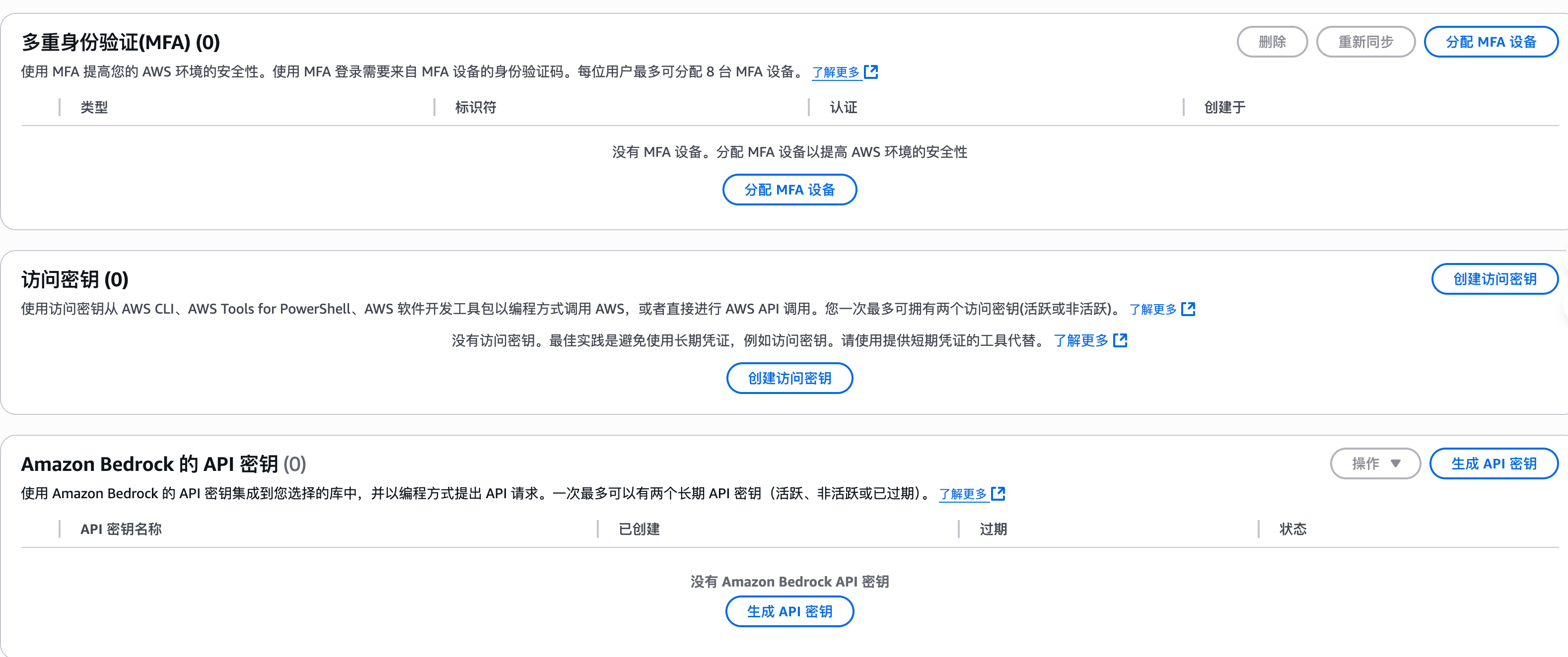
创建过程中会出现最佳实践提示,不影响后续配置,下载密钥即可使用。
其他的凭证方式虽然有 IAM Role 和 Role anywhere,但是我们这次不会用到。
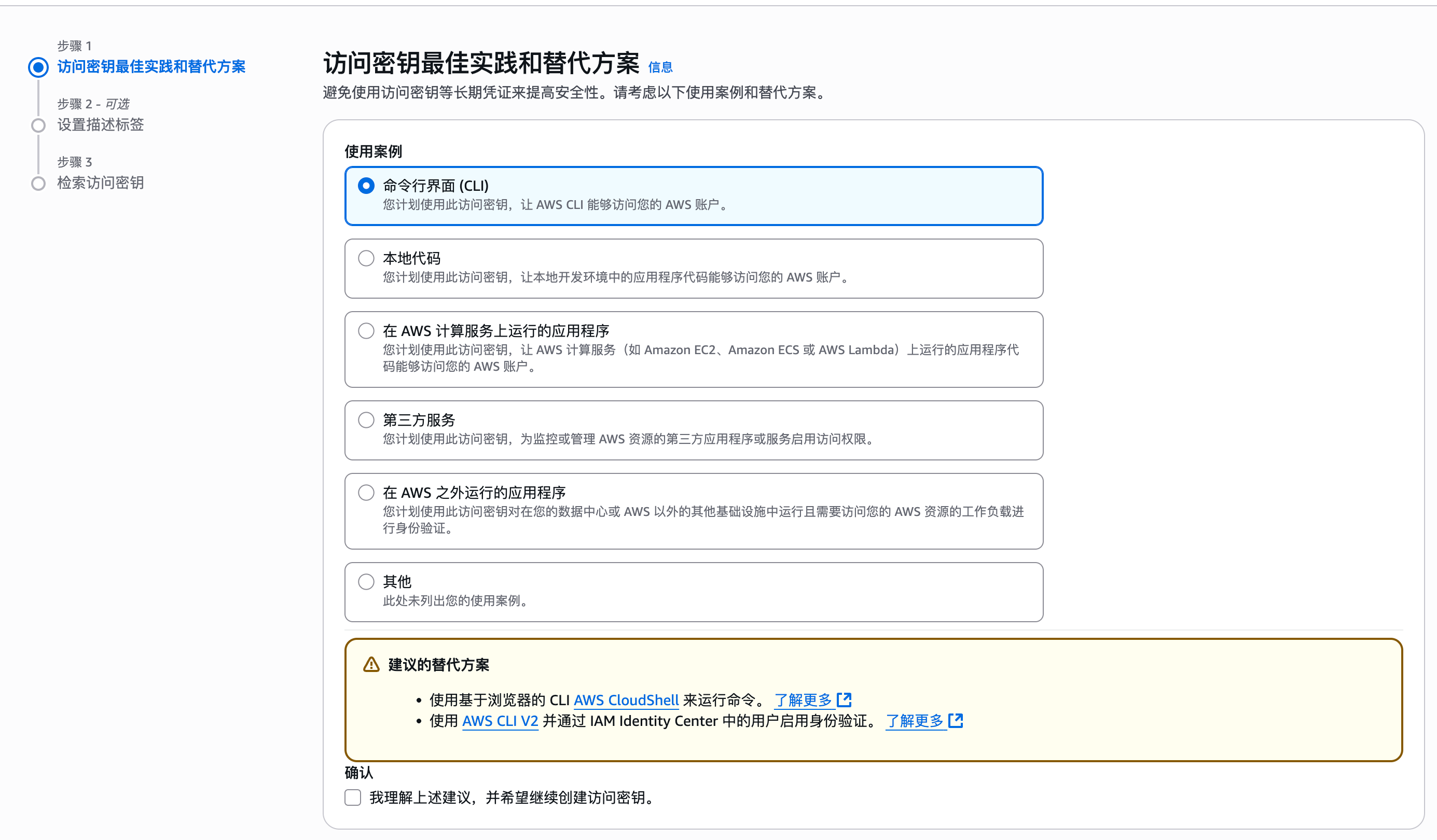
确保这个用户有访问 S3 的权限,如果是生产的环境的话,确保要采用最小权限原则来防止不必要的麻烦。如果你在存储桶上配置了对应桶策略也可以。
- 对象前缀(Prefix)配置
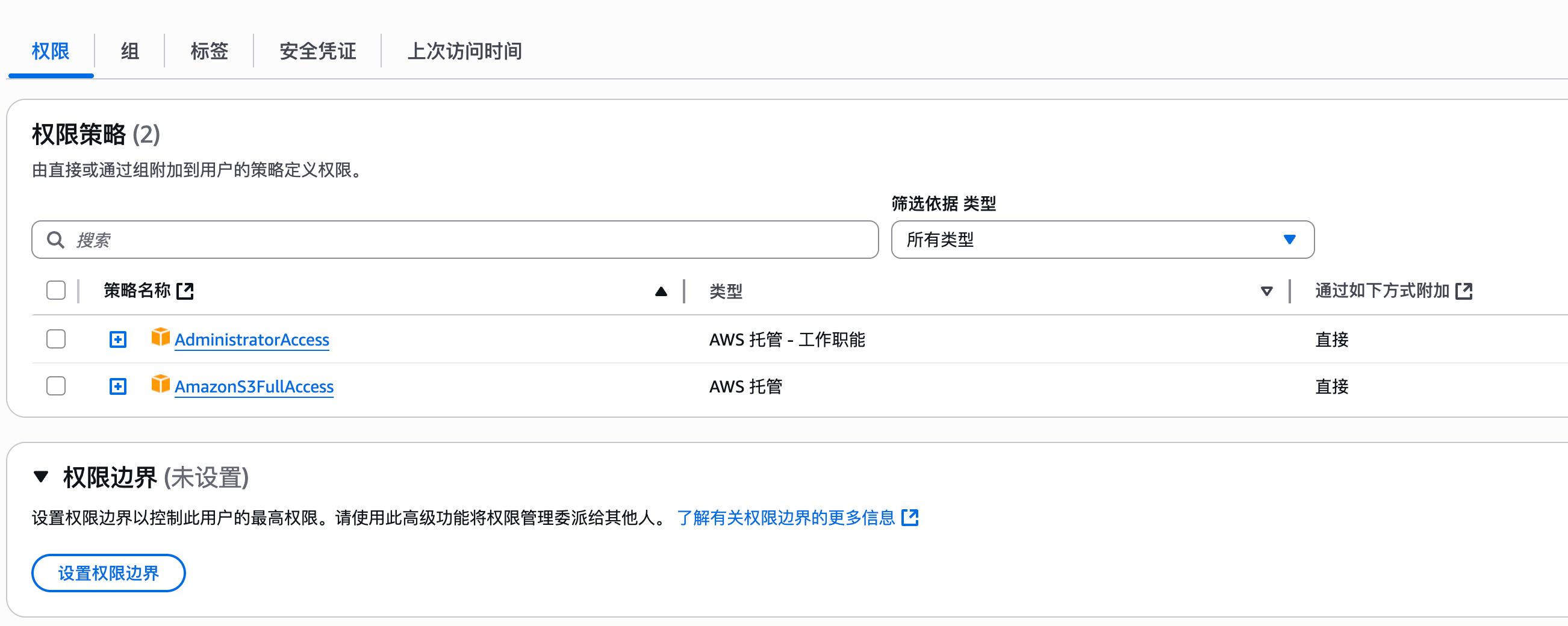
这个是我在 S3 上的对象存储,放了一些 markdown 文件上去。
还是这张图,我使用的是东京区的存储桶 dify233,所以 endpoint 是 s3.ap-northeast-1.amazonaws.com。
这里的对象前缀可以理解为目录,在 S3 设置之初会把所有文件夹的名称当作前缀加到文件名前面,所以也有 S3 是扁平化管理一说。
五、集成效果
完成连接后,S3 中的 Markdown 文件可被 Coco-AI 实时索引与检索,点击搜索结果即可跳转到 S3 公网访问链接,例如:
https://<bucket>.s3.<region>.amazonaws.com/<对象名>
不仅支持标题关键词搜索,还可结合 LLM 实现语义检索,极大提升信息获取效率。
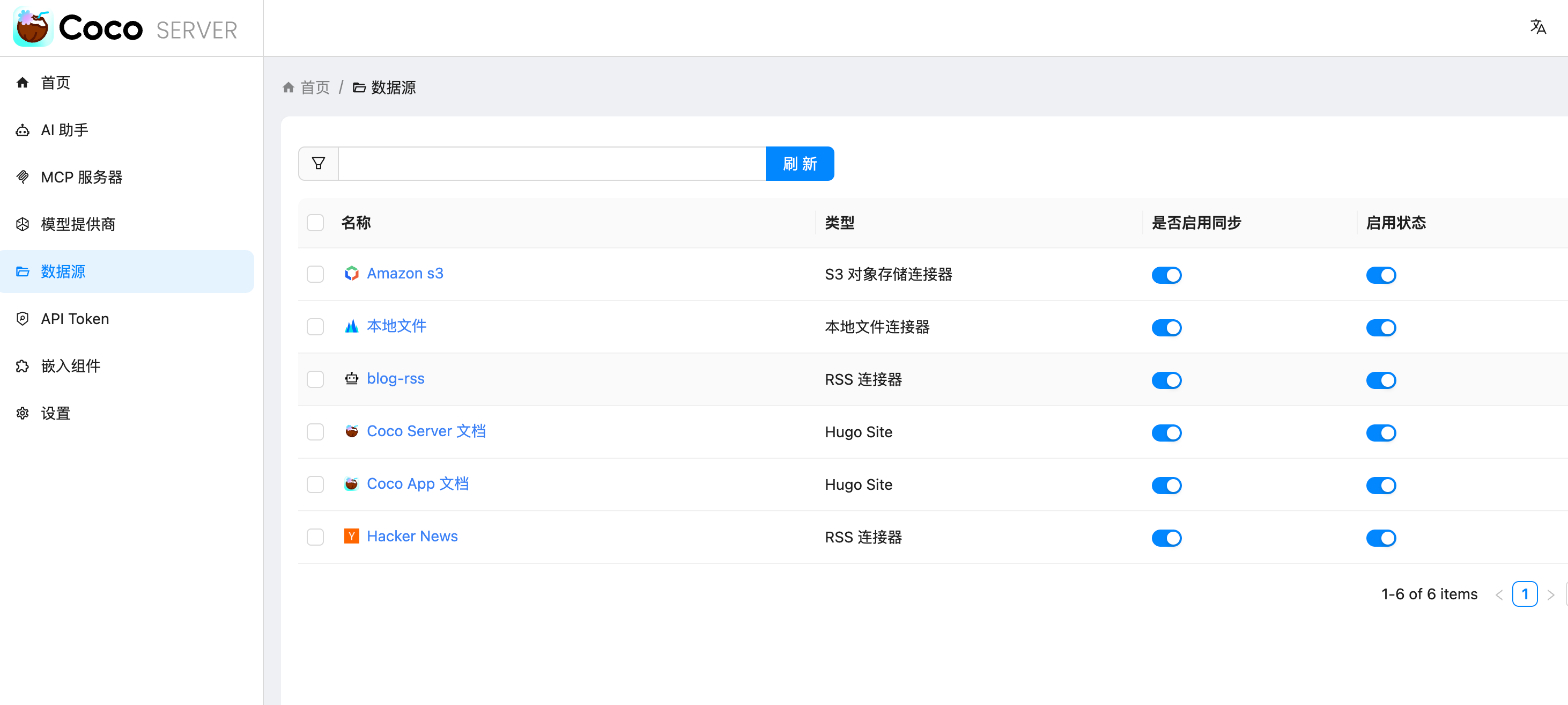
添加完成后可以看到我同时接入了 S3、本地文件和 RSS,我们这里主要开介绍关于 S3 的连接器。
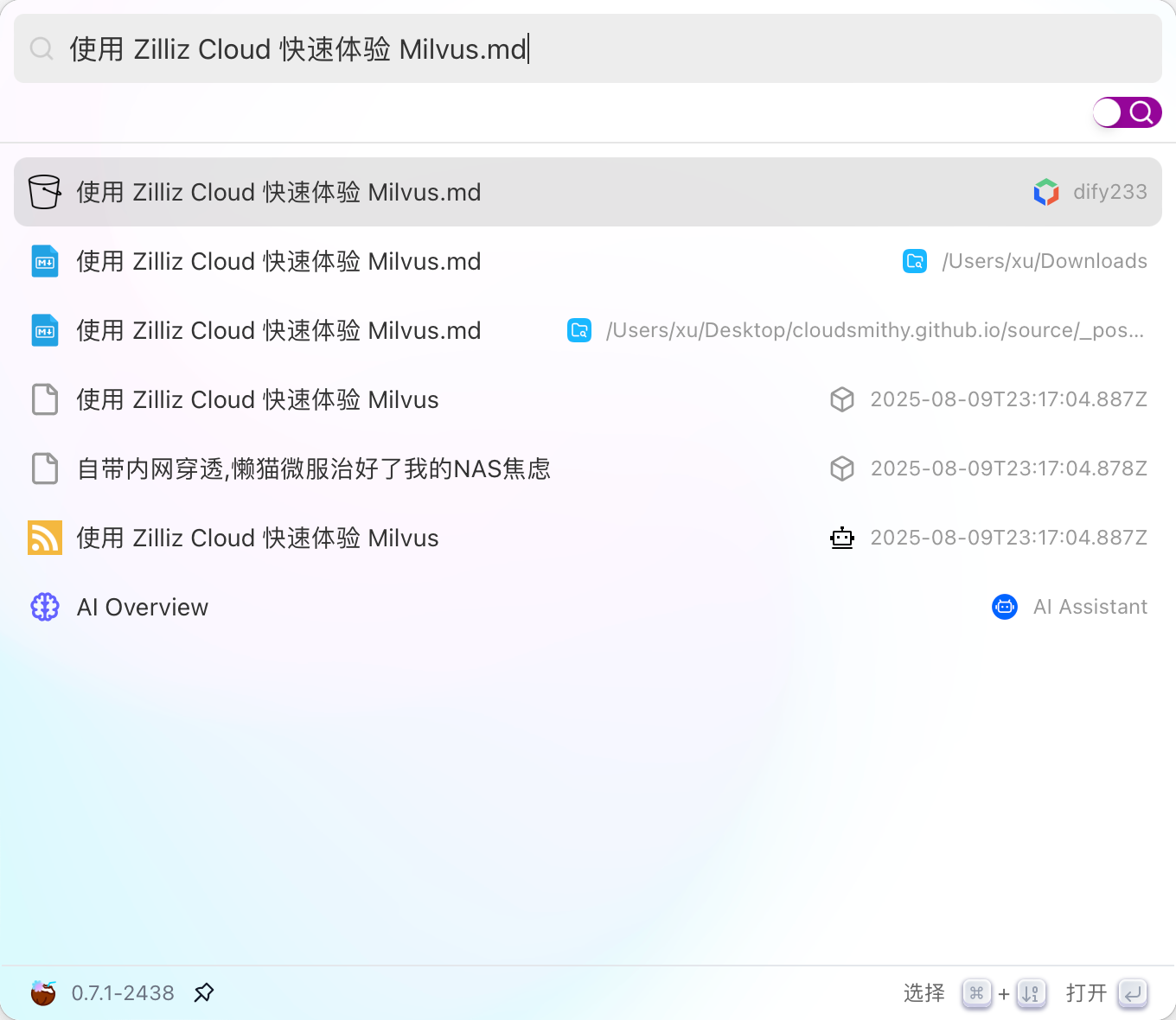
使用 Coco-AI 搜索时,能快速检索到 s3 中的 markdown 文件。
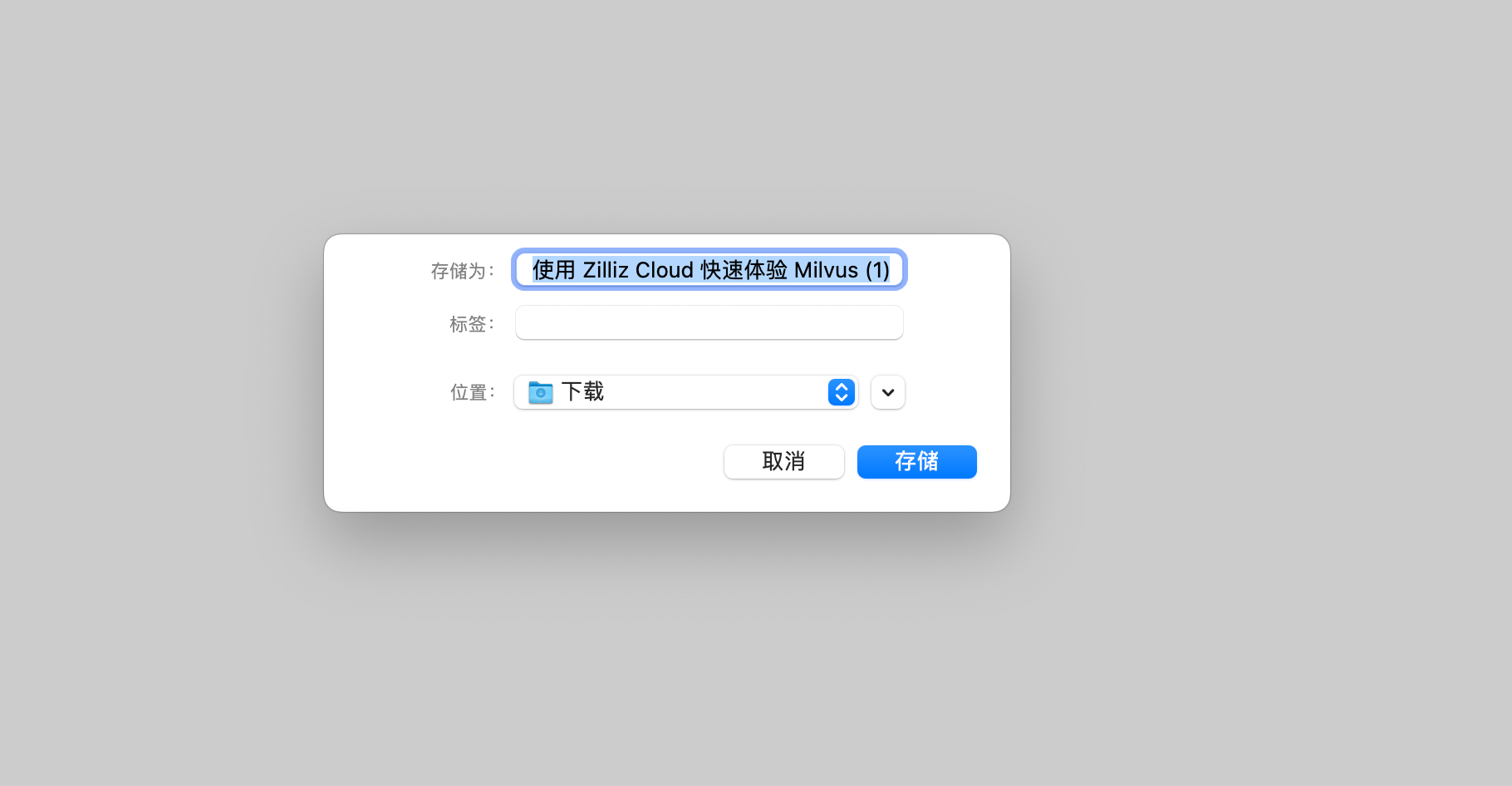
点击搜索结果可直接跳转到对应链接。
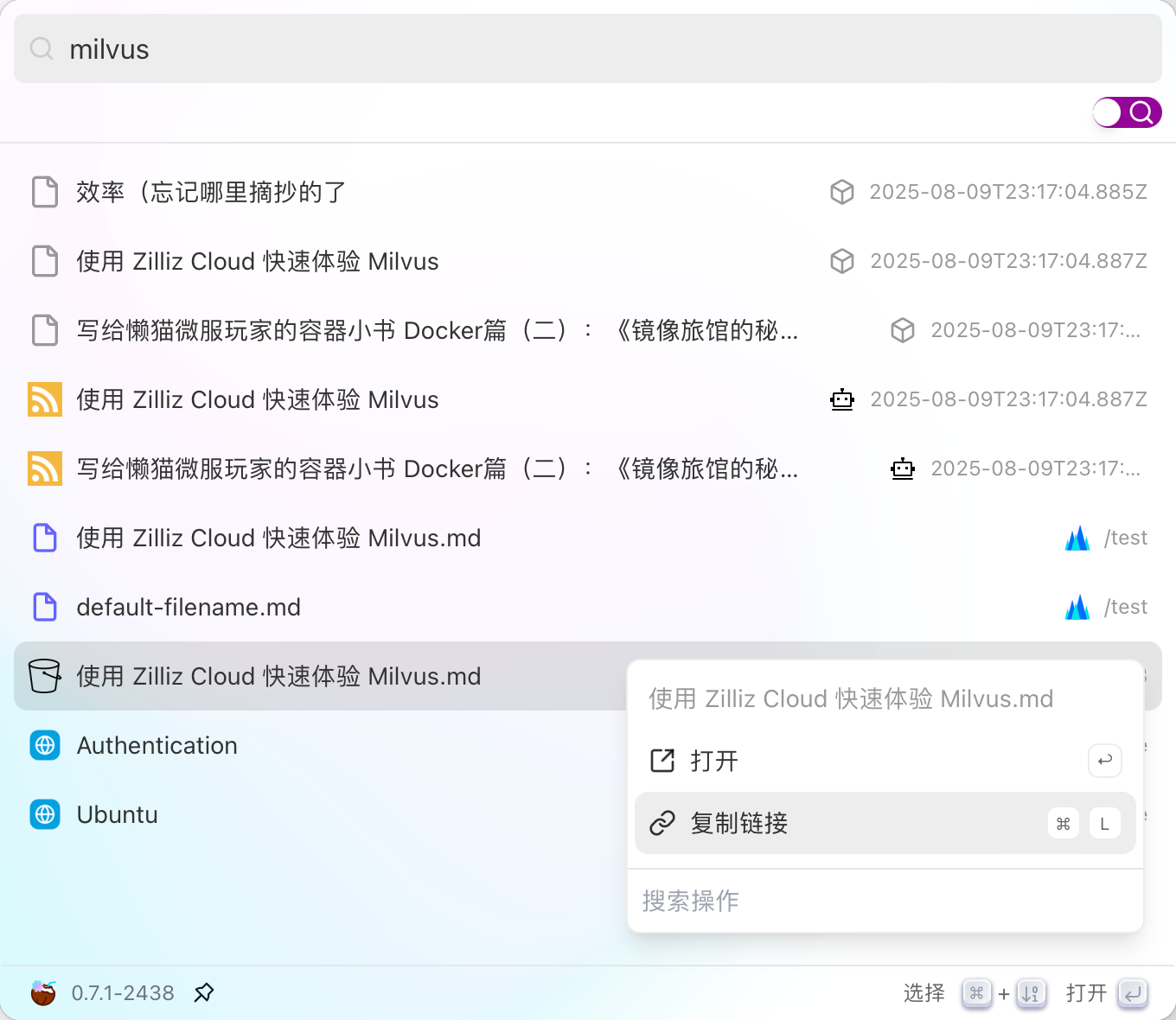
也支持把地址复制出来:https://dify233.s3.ap-northeast-1.amazonaws.com/对象名,其实就是S3的https 链接了。
六、适用场景
- 企业内部知识库:研发文档、政策文件、培训资料统一存放于 S3
- 个人云端资料管理:博客、项目资料随时调用
- 跨团队协作:多地访问,实时共享
通过 Coco-AI S3 连接器,只需几步,即可让 ** Amazon S3** 成为高效智能检索系统的云端引擎。
无论是个人开发者,还是大型企业团队,都能快速构建跨云端、本地、第三方数据源的统一知识平台。
评论
0暂无评论