
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

Ollama + Open WebUI 微服版
微服中运行的 Ollama 服务和 Open WebUI 服务
安装次数
点赞
应用评论
催更次数
桌面端
移动端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
1. 本版本是在微服中使用 CPU 运行的最新版本,随上游更新。如果购买了算力舱建议使用算力舱的版本。如果您在使用中遇到问题,请联系官方人员排查,感谢 2. 默认添加了 HF_ENDPOINT=https://hf-mirror.com 环境变量,如果您所处的环境中,不能下载模型,请及时联系我们. 3. Open-WebUI 中使用的自己的帐号体系,首次登录的时候需要配置自己的帐号密码(这个和微服的帐号体系没有关联). 4. LzcOllama 中没有带模型,您需要在界面上手动拉取模型,如 qwen3:0.6b 等. 5. 在询问中,首次问答,因为需要对模型做加载和编译,需要一点时间,请您稍等下,一旦模型加载完成,后续的询问将正常. 6. 默认关闭 Ollama 的并发,和 Open-WebUI 的输入框自动补全. 7. 如果在拉取模型过程中,超时或者进度越来越慢,您可以点击右边的X取消下载,然后重新拉取下. 8. 其他应用使用 ollama 接口,可以通过 https://lzcollama.$boxname.heiyu.space/lzcollama 访问
相关攻略


本地 RAG 实战:用 Easysearch + Ollama SDK 半小时搭建检索增强问答系统
https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.lzcollama > ✅ 目标:只用两台服务器(或同一台)就跑通 **“向量检索 + 本地大模型”** 原型 > ✅ 特点:**完全离线**、依赖极少、部署脚本即文档 > ✅ 适合:快速 PoC、内网合规场景、想深挖 RAG 工作机理的开发者 生成式 AI 聊天固然强大,但当问题依赖本地私有知识时,单靠 LLM 参数内的“世界记忆”往往答非所问。**RAG(Retrieval-Augmented Generation)** 的思路是: 1. **把文档切片 → 向量化 → 入库** 2. **用户提问 → 同样向量化 → 检索** 3. 将召回片段拼进 prompt,让大模型“带着材料”再回答 多数教程直接用云端 Embedding+OpenAI GPT-4o,但**一些团队因隐私、成本或离线环境**无法这样做。 本文选用: - **EasySearch (= OpenSearch + Elastiknn)** 做向量存取 - **Ollama SDK** 连接本地 LLM - **Python + requests + ollama** 三个依赖即可 <!-- more --> ## 1. 系统架构 ``` 用户问题 ──▶ 嵌入模型 (Ollama) ──▶ EasySearch 向量检索 ──▶ Top-k 片段 ▲ │ │ │ LLM (Ollama Chat) ◀── 拼 Prompt + 生成答案 ◀───────────────┘ ``` - **嵌入模型**:`nomic-embed-text`(768 维,多语言通用) - **检索引擎**:EasySearch 2.x + Elastiknn `knn_dense_float_vector` - **对话模型**:`deepseek-r1:7b`(轻量,好部署;可换 `llama3` / `qwen`) ## 2. 环境与依赖 ```python import os, json, requests, warnings from ollama import Client from requests.packages.urllib3.exceptions import InsecureRequestWarning warnings.filterwarnings("ignore", category=InsecureRequestWarning) ``` ```bash # Python 依赖 pip install ollama requests # 拉取模型 ollama pull nomic-embed-text ollama pull deepseek-r1:7b ``` ## 3. 代码逐段拆解 ### 3.1 全局配置 ```python # ────────────── 配置区 ────────────── ES_URL = os.getenv("ES_URL", "https://localhost:9200") ES_AUTH = ("admin", "c59a759f31e901e8d279") # 无认证设为 None INDEX = "rag_demo" OLLAMA_HOST = os.getenv("OLLAMA_URL", "http://localhost:11434") EMBED_MODEL = "nomic-embed-text" # 向量模型 CHAT_MODEL = "deepseek-r1:7b" # 对话模型 TOP_K = 4 NUM_CAND = 200 ``` 这段代码只是**给脚本提前设定一些“连接参数”与“模型选择”**,方便后面统一引用。逐行解释如下: ```python ES_URL = "https://<es_host>:9200" ``` - **ES_URL**:EasySearch / OpenSearch 集群的完整地址(含协议与端口)。 - `<es_host>` 是占位符,实际部署时要替换成你的 IP 或域名。 - 如果你的集群没开 TLS,可写成 `http://10.0.0.8:9200`。 ```python ES_AUTH = ("elastic", "password") # 无认证设为 None ``` - **ES_AUTH**:连接集群的账号密码元组。 - 脚本里传给 `requests` 的 `auth=` 参数,会自动加 Basic Auth 头。 - 若集群关闭了安全认证或走内网匿名访问,就把它设成 `None`。 ```python INDEX = "rag_demo" ``` - **INDEX**:向量索引(或文档索引)的名称。 - 脚本后面会对该索引做 _create / bulk write / search_ 等操作。 - 换成别的名字时记得保持一致,例如 `"knowledge_base"`。 ```python OLLAMA_HOST = "http://<ollama_host>:11434" ``` - **OLLAMA_HOST**:本地 Ollama 服务的 HTTP 起始地址。 - `<ollama_host>` 也是占位符;若脚本与 Ollama 在同一台机器,可写 `http://localhost:11434`。 - 端口 `11434` 是 Ollama 默认 REST 端口。 ```python EMBED_MODEL = "nomic-embed-text" ``` - **EMBED_MODEL**:用于生成文本向量(embeddings)的模型名。 - 在脚本里会调用 `client.embeddings(model=EMBED_MODEL, …)`。 - 替换规则:先执行 `ollama pull <模型名>`,确保本地已下载。 ```python CHAT_MODEL = "deepseek-r1:7b" ``` - **CHAT_MODEL**:负责最终回答的聊天 / 生成式模型。 - 脚本会用 `client.chat(model=CHAT_MODEL, …)` 进行对话。 - 同理,若想用 `llama3:8b-chat`、`qwen:7b-chat` 等,先 `ollama pull` 再改这里。 --- ### 3.2 嵌入与对话(Ollama SDK) client 是连接 Ollama 模型服务的客户端,用来发请求。 session 是访问 Elasticsearch 用的请求会话,能提高网络效率。 用指定的嵌入模型(比如 nomic-embed-text)把文本转成向量,用于相似度搜索。 用指定的聊天模型(比如 deepseek-r1:7b)回答问题,返回回复文本。 ```python # ────────────── 初始化 ────────────── client = Client(host=OLLAMA_HOST) session = requests.Session() # ────────────── Ollama 封装 ────────────── def embed(text: str) -> list[float]: """返回文本向量 (list[float])""" resp = client.embeddings(model=EMBED_MODEL, prompt=text) return resp["embedding"] def chat(prompt: str) -> str: """与聊天模型对话(完整回复)""" resp = client.chat( model=CHAT_MODEL, messages=[{"role": "user", "content": prompt}], # stream=False ) return resp["message"]["content"] ``` ### 3.3 建索引(Elastiknn) 在构建基于向量的 RAG(Retrieval-Augmented Generation)系统时,我们首先需要在向量数据库中创建一个支持向量检索的索引。本文使用 EasySearch 作为底层存储,向其中注册一个支持近似向量搜索的索引结构。 create_index 函数的作用是通过 RESTful API 创建一个名为 rag_demo 的索引,并定义字段结构如下: content:文本内容字段,类型为 text,可用于全文搜索或作为上下文返回。 vec:向量字段,类型为 knn_dense_float_vector,支持高维向量的快速相似度搜索。 配置中使用了 LSH(局部敏感哈希)模型与 cosine 相似度度量,同时设定了近似参数 L 与 k,分别控制候选样本数量和返回结果数。 通过设定 "index.knn": True,该索引支持使用 k-NN 查询来高效地检索与查询向量最相似的文档。在实际使用中,嵌入模型如 nomic-embed-text 可将输入文本转换为高维向量,存入此索引中,与用户查询语义对齐,实现高效的语义检索能力。 ```python # ---------- ① 创建索引:Elastiknn 映射 ---------- def create_index(dim: int): mapping = { "settings": { "index.knn": True }, "mappings": { "properties": { "content": { "type": "text" }, "vec": { "type": "knn_dense_float_vector", "knn": { "dims": dim, "model": "lsh", # 也可 hnsw / exact "similarity": "cosine", "L": 99, "k": 1 } } } } } r = session.put(f"{ES_URL}/{INDEX}", json=mapping, verify=False, auth=ES_AUTH) if r.status_code not in (200, 201): if "resource_already_exists_exception" not in r.text: print("Create index error:\n", r.text) r.raise_for_status() ``` ### 3.4 写入文档 以下是对这段 `bulk_upload` 函数的简明解释,可用于博客正文或技术文档: 在 RAG 系统中,为了支持高效的语义检索,我们需要将原始文本与其对应的向量一起写入向量索引中。`bulk_upload` 函数正是完成这一任务的核心组件,它使用 Elasticsearch 的 `_bulk` 接口实现批量写入,显著提高写入效率。 - 每条记录包含两个部分: 1. `index` 元数据,指定目标索引(`rag_demo`)及文档 `_id`。 2. 实际文档内容,包括: - `content`:原始文本内容; - `vec`:对应的文本向量,**必须使用 `{"values": [...]}` 的对象结构**。 - 向量通过 `embed(t)` 获得,调用本地部署的 Ollama 模型(如 `nomic-embed-text`)生成。 - 所有数据最终编码为 JSON,通过 `Content-Type: application/x-ndjson` 提交到 `/_bulk` API 接口,实现一次性批量写入。 ```python # ---------- ② 批量写入:向量必须包 {"values": …} ---------- def bulk_upload(texts: list[str]): bulk = [] for i, t in enumerate(texts): bulk.append({ "index": { "_index": INDEX, "_id": i } }) bulk.append({ "content": t, "vec": { "values": embed(t) } # ★ 关键:对象格式 }) ndjson = "\n".join(json.dumps(d, ensure_ascii=False) for d in bulk) + "\n" r = session.post(f"{ES_URL}/_bulk", data=ndjson.encode("utf-8"), headers={"Content-Type": "application/x-ndjson"}, verify=False, auth=ES_AUTH) r.raise_for_status() ``` ### 3.5 语义检索 这段 `search` 函数的作用是在 RAG 系统中执行基于向量的语义检索,以下是适合用于博客中的简明解释: RAG 系统的核心是从向量索引中找到与用户问题最相近的语义片段。`search` 函数即完成了这个过程,它调用 EasySearch 的向量检索接口,返回最相似的文本内容。 1. **文本向量化**:通过 `embed(question)` 把用户输入的问题转换成向量 `qvec`。 2. **构造检索请求**: 使用 `knn_nearest_neighbors` 查询 - `field`: 向量字段名(本例中是 `"vec"`); - `vec`: 查询向量,必须写成 `{ "values": [...] }` 的对象结构; - `model`: 向量近似检索模型(如 `"lsh"`); - `similarity`: 相似度度量方式(如 `"cosine"`); - `k`: 返回的结果数; - `candidates`: 候选池大小,用于粗排优化检索效果。 3. **发送请求并解析响应**: 请求通过 Elasticsearch `_search` 接口提交,若返回不成功,则输出报错信息;成功后提取 `_source["content"]` 字段,返回给上层用于回答生成。 ### ✅ 示例用途: 用户提问:“张三是谁”,系统会将该问题向量化,然后在已有文本向量中进行相似度匹配,从而返回如“张三是法律专家……”的片段,作为构建回答的上下文。 这段逻辑是 RAG 模型“Retriever”阶段的核心,让大模型在“有知识”的基础上作答,提升准确性和实用性。 ```python def search(question: str, top_k: int = TOP_K): qvec = embed(question) body = { "size": top_k, "query": { "knn_nearest_neighbors": { # 若 Elastiknn 0.7.x 用 elastiknn_nearest_neighbors "field": "vec", "vec": { "values": qvec }, "model": "lsh", "similarity": "cosine", "k": top_k, "candidates": 200 } } } r = session.post(f"{ES_URL}/{INDEX}/_search", json=body, verify=False, auth=ES_AUTH) if not r.ok: print("== ES response ==", r.text) r.raise_for_status() return [hit["_source"]["content"] for hit in r.json()["hits"]["hits"]] ``` ### 3.6 主循环 ```python # ────────────── CLI 主逻辑 ────────────── def main(): docs = [ # 原来的 3 条 "张三是法律专家,擅长合同法与知识产权。", "李四在人机交互领域研究多年,尤其关注可用性测试。", "王五是一名资深软件工程师,对云原生、DevOps 有丰富经验。", # 新增 100 条 "赵六是一名数据科学家,专注机器学习模型调优。", "孙七具有十年金融风控经验,熟悉巴塞尔协议。", "周八是区块链开发者,擅长智能合约安全审计。", "吴九长期研究边缘计算,在 IoT 网关架构方面有实践。", "郑十是资深 DBA,精通 MySQL 性能调优与高可用。", "钱十一擅长云原生安全治理,主导多家企业零信任落地。", "蒋十二是 GPU 运维专家,对 CUDA 优化有深入研究。", "沈十三专注深度学习推理加速,维护 TensorRT 插件。", "韩十四是 FaaS 平台架构师,关注冷启动优化策略。", "姚十五从事量化交易算法开发,对高频数据处理熟练。", "邵十六是渗透测试工程师,擅长 Web 漏洞挖掘与利用。", "汪十七主攻 AIGC 版权合规,为多家媒体机构提供方案。", "孔十八研究联邦学习,解决数据孤岛隐私问题。", "曹十九负责 SRE 团队,精通混沌工程与错误预算管理。", "严二十是网络取证专家,参与多起重大案件分析。", "华二一研发 AutoML 平台,降低模型训练门槛。", "雷二二在 5G 边缘网协同计算领域发表多篇论文。", "凌二三是 DevRel 经理,推动开源社区增长。", "史二四对 RAG 架构有深入实践,优化检索召回率。", "阮二五是 WebGPU 先行者,致力提升前端渲染性能。", "杭二六主导多云成本治理项目,节省 30% 预算。", "乔二七是一名 AIGC Prompt 工程师,专精多模态指令设计。", "詹二八擅长大规模 AB 测试框架落地。", "顾二九是 Serverless 架构布道者,编写多本技术书籍。", "龚三十关注 DORA 指标,用数据驱动 DevOps 改进。", "计三一是 API 网关专家,实现百万 QPS 低延迟。", "蒲三二研究影像分割模型,用于医学辅助诊断。", "邱三三是 Zig 语言早期贡献者,推行内存安全编码。", "庄三四长期维护 Kafka 集群,擅长 Topic 规划。", "宫三五是低代码平台架构师,关注插件生态。", "蓝三六研究 ICEBERG 表格式,提升湖仓查询效率。", "聂三七在安全编排 SOAR 产品设计上经验丰富。", "陆三八主导 SaaS 产品国际化,本地化流程成熟。", "温三九负责混合云 DR 方案,实现分钟级切换。", "袁四十是语音合成工程师,优化多 speaker 适配。", "贾四一深入研究 DDD,帮助团队理清领域边界。", "伏四二从事实时风控大数据平台架构,处理亿级流量。", "程四三是 ARM SoC 驱动工程师,对电源管理熟悉。", "屈四四在 Federated GraphQL 网关治理方面有案例。", "申四五带队实现 MLOps 自动化发布流程。", "罗四六研究 VDBMS,支持 PB 级向量检索。", "祝四七是 HTAP 数据库布道者,优化混合负载。", "左四八在 IAM 与 RBAC 设计领域深耕。", "冷四九是链路可观测性工程师,推广 OTEL 标准。", "包五十投入异构计算调度框架研究。", "滑五一精通 eBPF 在安全可观测性场景的落地。", "柴五二研究量子安全算法,对国密迁移方案熟悉。", "谈五三是内核安全研究员,发现多个 0-day 漏洞。", "鄢五四主导 SaaS 计费系统重构,支持灵活套餐。", "邸五五是绿色数据中心规划师,推动 PUE 降到 1.2。", "候五六在自动驾驶 SLAM 算法具有专利。", "古五七关注 CDP 架构,连接多源营销数据。", "丁五八是 FPGA 加速工程师,实现低延迟推理。", "靳五九研究 WASM 边缘运行时,降低冷启动。", "柴六十在 DevSecOps 流水线集成方面经验丰富。", "花六一策划大规模黑客马拉松,促成 500+ 项目孵化。", "牛六二是边缘 AI 推理框架作者,重视功耗优化。", "焦六三研究自监督学习在推荐系统的应用。", "商六四是 Rust Web 开发者,推广零拷贝 JSON 解析。", "阎六五投入数字孪生城市平台研发。", "弓六六主攻 OTA 升级安全,覆盖汽车 ECU。", "怀六七是 MAC 数据平面专家,优化转发性能。", "宓六八参与多场灾备演练,完善演练脚本体系。", "郝六九是 PKI 架构师,设计大规模证书生命周期。", "嵇七十致力于多媒体编解码标准化。", "邝七一研究 EDA 自动布线算法。", "桑七二打造 AI 工厂流水线,实现模型快速迭代。", "桂七三专注 DPU 加速网络虚拟化。", "麻七四是 Supabase 中国社区维护者,推广 BaaS。", "仇七五实现企业级 KYC 流程自动化。", "薄七六研究多模态情感分析,用于客服质检。", "谯七七是 SD-WAN 产品经理,聚焦海外专线优化。", "巫七八负责 Kafka to Pulsar 迁移方案。", "桑七九在 DAG 引擎优化 CPS 流水线。", "邬八十研究端侧 LLM 蒸馏压缩。", "臧八一是三维重建算法工程师,服务文博数字化。", "禾八二专攻 S3 兼容对象存储网关。", "原八三参与可信执行环境 TEE 方案落地。", "淦八四是工业互联网安全规划顾问。", "练八五实现 GPU 多租户 QoS 调度器。", "禹八六关注跨境合规要求,精通 GDPR。", "廉八七是 SDN 控制器开源贡献者。", "亓八八专注高并发长连接网关。", "宗八九打造零代码机器学习平台。", "公冶九十研究 PIM 存内计算架构。", "红九一是 MESH 网络性能调优专家。", "眭九二致力于 AI 合成音频版权检测。", "米九三推动碳排放数据平台建设。", "隗九四是机器人运动规划算法专家。", "拉九五研究语义分割在遥感图像的应用。", "蔺九六负责 0-RTT QUIC 协议优化。", "臧九七专注 BERT 在法律文本的细粒度实体抽取。", "昝九八是 RPG 游戏 AI NPC 行为树作者。", "贝九九研究差分隐私在广告数据的实践。", "施一百主导云原生 API 安全监控平台。", "伏一零一优化 Kafka Connect 大规模同步。", "堵一零二研究车辆 V2X 协议栈实现。", "莎一零三聚焦 A/B 决策平台可视化。", ] dim = len(embed("维度探测")) # 动态探测向量维度 create_index(dim) bulk_upload(docs) print(f"[√] 初始化完成(向量维度 {dim})。开始提问,Ctrl+C 退出。\n") try: while True: q = input("Q: ").strip() if not q: continue passages = search(q) context = "\n".join(f"资料{i+1}:{p}" for i, p in enumerate(passages)) prompt = (f"已知资料如下:\n{context}\n\n请根据以上资料回答用户问题:{q}") print("\nA:", chat(prompt)) print("引用:", passages, "\n") except KeyboardInterrupt: print("\nBye!") if __name__ == "__main__": main() ``` ## 4. 运行效果 ``` Q: 张三擅长什么 A: 张三是一名法律专家,专长领域为合同法与知识产权。 引用: ['张三是法律专家,擅长合同法与知识产权。'] ``` 结果如下:  完整代码: ```python import os, json, requests, warnings from ollama import Client from requests.packages.urllib3.exceptions import InsecureRequestWarning warnings.filterwarnings("ignore", category=InsecureRequestWarning) # ────────────── 配置区 ────────────── ES_URL = os.getenv("ES_URL", "https://localhost:9200") ES_AUTH = ("admin", "c59a759f31e901e8d279") # 无认证设为 None INDEX = "rag_demo" OLLAMA_HOST = os.getenv("OLLAMA_URL", "http://localhost:11434") EMBED_MODEL = "nomic-embed-text" # 向量模型 CHAT_MODEL = "deepseek-r1:7b" # 对话模型 TOP_K = 4 NUM_CAND = 200 # kNN 先粗召回条数 # ────────────── 初始化 ────────────── client = Client(host=OLLAMA_HOST) session = requests.Session() # ────────────── Ollama 封装 ────────────── def embed(text: str) -> list[float]: """返回文本向量 (list[float])""" resp = client.embeddings(model=EMBED_MODEL, prompt=text) return resp["embedding"] def chat(prompt: str) -> str: """与聊天模型对话(完整回复)""" resp = client.chat( model=CHAT_MODEL, messages=[{"role": "user", "content": prompt}], # stream=False ) return resp["message"]["content"] # ---------- ① 创建索引:Elastiknn 映射 ---------- def create_index(dim: int): mapping = { "settings": { "index.knn": True }, "mappings": { "properties": { "content": { "type": "text" }, "vec": { "type": "knn_dense_float_vector", "knn": { "dims": dim, "model": "lsh", # 也可 hnsw / exact "similarity": "cosine", "L": 99, "k": 1 } } } } } r = session.put(f"{ES_URL}/{INDEX}", json=mapping, verify=False, auth=ES_AUTH) if r.status_code not in (200, 201): if "resource_already_exists_exception" not in r.text: print("Create index error:\n", r.text) r.raise_for_status() # ---------- ② 批量写入:向量必须包 {"values": …} ---------- def bulk_upload(texts: list[str]): bulk = [] for i, t in enumerate(texts): bulk.append({ "index": { "_index": INDEX, "_id": i } }) bulk.append({ "content": t, "vec": { "values": embed(t) } # ★ 关键:对象格式 }) ndjson = "\n".join(json.dumps(d, ensure_ascii=False) for d in bulk) + "\n" r = session.post(f"{ES_URL}/_bulk", data=ndjson.encode("utf-8"), headers={"Content-Type": "application/x-ndjson"}, verify=False, auth=ES_AUTH) r.raise_for_status() # ---------- ③ 查询:knn_nearest_neighbors ---------- def search(question: str, top_k: int = TOP_K): qvec = embed(question) body = { "size": top_k, "query": { "knn_nearest_neighbors": { # 若 Elastiknn 0.7.x 用 elastiknn_nearest_neighbors "field": "vec", "vec": { "values": qvec }, "model": "lsh", "similarity": "cosine", "k": top_k, "candidates": 200 } } } r = session.post(f"{ES_URL}/{INDEX}/_search", json=body, verify=False, auth=ES_AUTH) if not r.ok: print("== ES response ==", r.text) r.raise_for_status() return [hit["_source"]["content"] for hit in r.json()["hits"]["hits"]] # ────────────── CLI 主逻辑 ────────────── def main(): docs = [ # 原来的 3 条 "张三是法律专家,擅长合同法与知识产权。", "李四在人机交互领域研究多年,尤其关注可用性测试。", "王五是一名资深软件工程师,对云原生、DevOps 有丰富经验。", # 新增 100 条 "赵六是一名数据科学家,专注机器学习模型调优。", "孙七具有十年金融风控经验,熟悉巴塞尔协议。", "周八是区块链开发者,擅长智能合约安全审计。", "吴九长期研究边缘计算,在 IoT 网关架构方面有实践。", "郑十是资深 DBA,精通 MySQL 性能调优与高可用。", "钱十一擅长云原生安全治理,主导多家企业零信任落地。", "蒋十二是 GPU 运维专家,对 CUDA 优化有深入研究。", "沈十三专注深度学习推理加速,维护 TensorRT 插件。", "韩十四是 FaaS 平台架构师,关注冷启动优化策略。", "姚十五从事量化交易算法开发,对高频数据处理熟练。", "邵十六是渗透测试工程师,擅长 Web 漏洞挖掘与利用。", "汪十七主攻 AIGC 版权合规,为多家媒体机构提供方案。", "孔十八研究联邦学习,解决数据孤岛隐私问题。", "曹十九负责 SRE 团队,精通混沌工程与错误预算管理。", "严二十是网络取证专家,参与多起重大案件分析。", "华二一研发 AutoML 平台,降低模型训练门槛。", "雷二二在 5G 边缘网协同计算领域发表多篇论文。", "凌二三是 DevRel 经理,推动开源社区增长。", "史二四对 RAG 架构有深入实践,优化检索召回率。", "阮二五是 WebGPU 先行者,致力提升前端渲染性能。", "杭二六主导多云成本治理项目,节省 30% 预算。", "乔二七是一名 AIGC Prompt 工程师,专精多模态指令设计。", "詹二八擅长大规模 AB 测试框架落地。", "顾二九是 Serverless 架构布道者,编写多本技术书籍。", "龚三十关注 DORA 指标,用数据驱动 DevOps 改进。", "计三一是 API 网关专家,实现百万 QPS 低延迟。", "蒲三二研究影像分割模型,用于医学辅助诊断。", "邱三三是 Zig 语言早期贡献者,推行内存安全编码。", "庄三四长期维护 Kafka 集群,擅长 Topic 规划。", "宫三五是低代码平台架构师,关注插件生态。", "蓝三六研究 ICEBERG 表格式,提升湖仓查询效率。", "聂三七在安全编排 SOAR 产品设计上经验丰富。", "陆三八主导 SaaS 产品国际化,本地化流程成熟。", "温三九负责混合云 DR 方案,实现分钟级切换。", "袁四十是语音合成工程师,优化多 speaker 适配。", "贾四一深入研究 DDD,帮助团队理清领域边界。", "伏四二从事实时风控大数据平台架构,处理亿级流量。", "程四三是 ARM SoC 驱动工程师,对电源管理熟悉。", "屈四四在 Federated GraphQL 网关治理方面有案例。", "申四五带队实现 MLOps 自动化发布流程。", "罗四六研究 VDBMS,支持 PB 级向量检索。", "祝四七是 HTAP 数据库布道者,优化混合负载。", "左四八在 IAM 与 RBAC 设计领域深耕。", "冷四九是链路可观测性工程师,推广 OTEL 标准。", "包五十投入异构计算调度框架研究。", "滑五一精通 eBPF 在安全可观测性场景的落地。", "柴五二研究量子安全算法,对国密迁移方案熟悉。", "谈五三是内核安全研究员,发现多个 0-day 漏洞。", "鄢五四主导 SaaS 计费系统重构,支持灵活套餐。", "邸五五是绿色数据中心规划师,推动 PUE 降到 1.2。", "候五六在自动驾驶 SLAM 算法具有专利。", "古五七关注 CDP 架构,连接多源营销数据。", "丁五八是 FPGA 加速工程师,实现低延迟推理。", "靳五九研究 WASM 边缘运行时,降低冷启动。", "柴六十在 DevSecOps 流水线集成方面经验丰富。", "花六一策划大规模黑客马拉松,促成 500+ 项目孵化。", "牛六二是边缘 AI 推理框架作者,重视功耗优化。", "焦六三研究自监督学习在推荐系统的应用。", "商六四是 Rust Web 开发者,推广零拷贝 JSON 解析。", "阎六五投入数字孪生城市平台研发。", "弓六六主攻 OTA 升级安全,覆盖汽车 ECU。", "怀六七是 MAC 数据平面专家,优化转发性能。", "宓六八参与多场灾备演练,完善演练脚本体系。", "郝六九是 PKI 架构师,设计大规模证书生命周期。", "嵇七十致力于多媒体编解码标准化。", "邝七一研究 EDA 自动布线算法。", "桑七二打造 AI 工厂流水线,实现模型快速迭代。", "桂七三专注 DPU 加速网络虚拟化。", "麻七四是 Supabase 中国社区维护者,推广 BaaS。", "仇七五实现企业级 KYC 流程自动化。", "薄七六研究多模态情感分析,用于客服质检。", "谯七七是 SD-WAN 产品经理,聚焦海外专线优化。", "巫七八负责 Kafka to Pulsar 迁移方案。", "桑七九在 DAG 引擎优化 CPS 流水线。", "邬八十研究端侧 LLM 蒸馏压缩。", "臧八一是三维重建算法工程师,服务文博数字化。", "禾八二专攻 S3 兼容对象存储网关。", "原八三参与可信执行环境 TEE 方案落地。", "淦八四是工业互联网安全规划顾问。", "练八五实现 GPU 多租户 QoS 调度器。", "禹八六关注跨境合规要求,精通 GDPR。", "廉八七是 SDN 控制器开源贡献者。", "亓八八专注高并发长连接网关。", "宗八九打造零代码机器学习平台。", "公冶九十研究 PIM 存内计算架构。", "红九一是 MESH 网络性能调优专家。", "眭九二致力于 AI 合成音频版权检测。", "米九三推动碳排放数据平台建设。", "隗九四是机器人运动规划算法专家。", "拉九五研究语义分割在遥感图像的应用。", "蔺九六负责 0-RTT QUIC 协议优化。", "臧九七专注 BERT 在法律文本的细粒度实体抽取。", "昝九八是 RPG 游戏 AI NPC 行为树作者。", "贝九九研究差分隐私在广告数据的实践。", "施一百主导云原生 API 安全监控平台。", "伏一零一优化 Kafka Connect 大规模同步。", "堵一零二研究车辆 V2X 协议栈实现。", "莎一零三聚焦 A/B 决策平台可视化。", ] dim = len(embed("维度探测")) # 动态探测向量维度 create_index(dim) bulk_upload(docs) print(f"[√] 初始化完成(向量维度 {dim})。开始提问,Ctrl+C 退出。\n") try: while True: q = input("Q: ").strip() if not q: continue passages = search(q) context = "\n".join(f"资料{i+1}:{p}" for i, p in enumerate(passages)) prompt = (f"已知资料如下:\n{context}\n\n请根据以上资料回答用户问题:{q}") print("\nA:", chat(prompt)) print("引用:", passages, "\n") except KeyboardInterrupt: print("\nBye!") if __name__ == "__main__": main() ``` ### 小结 > **EasySearch × Ollama** 让我们在本地就能体验到“RAG 的爽点”:检索带来实时、可信的上下文,大模型负责自然语言表达,二者合体即是一个可交付的“企业私有知识助手”。如果你也想在内网快速验证 PoC,这份脚本拷过去改两个地址即可开跑。祝玩得开心!
AnythingLLM:打造自己的专属知识库
## 什么是 AnythingLLM ? AnythingLLM 是 Mintplex Labs Inc. 开发的一款可以与任何内容聊天的私人 ChatGPT,是高效、可定制、开源的企业级文档聊天机器人解决方案。 它能够将任何文档、资源或内容片段转化为大语言模型(LLM)在聊天中可以利用的相关上下文。 软件特点: > 多用户实例支持和权限管理 > 全新的可嵌入式聊天小部件,适用于您的网站 > 支持多种文档类型(PDF、TXT、DOCX等) > 通过简单的用户界面管理您的向量数据库中的文档 > 两种聊天模式:对话模式和查询模式。对话模式保留之前的问题和修改记录。查询模式用于对您的文档进行简单的问答。 > 聊天中的引用文献功能 > 完全适用于云部署。 > “自带 LLM “模型。 > 极其高效的成本节约措施,用于管理非常大的文档。您将永远不会为嵌入的大型文档或转录付费超过一次。比其他文档聊天机器人解决方案更省成本,降低 90%。 > 提供完整的开发者 API,用于自定义集成! https://appstore.lazycat.cloud/#/shop/detail/me.ironfeet.app.anythingllm ## 如何使用 应用安装后,打开主页  在设置里,把语言改成中文  先创建一个工作区间  起个名字  发个消息,发现是报错的  这是因为应用默认不带模型,如果需要模型,可以自行配置 API Key 或者手动通过 Ollama 下载。 咱们懒猫商店里有另外一个应用,本身提供了Ollama模型: https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.lzcollama 先试一下功能,是正常的  在设置里,找到API密钥,复制下来,待会要用  回到AnythingLLM应用,点左下角设置  点LLM首选项,选择Ollama模型  url填入:https://lzcollama.你的懒猫.heiyu.space/lzcollama 注意它默认后面是没有/lzcollama的,你要手动加上。 Auth Token填入你刚才复制的api密钥  如果上面的都填对了,这里会出来模型选择  保存之后,回到工作区间。点击设置  这里选择Ollama模型,保存  代理配置,同样选择Ollama  再回到工作区间,发个消息  能看到正常回复了。 不过我问他天气怎么样,把我气到了  图片还不能识别  这取决于模型的能力,如果对接OpenAI的api应该会好些。 更多的玩法可以自己探索。

Ollama 和 Open-WebUI 使用指南
使用 Intel Ipex 优化后的 Ollama, 老实说,目前的用户体验还远非理想,我们正在探索如何优化。 - 安装过程可能会比较耗时 - 首次加载模型慢 ## 商店安装 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.lzcollama 首次启动时,应用需要安装intel oneAPI驱动。这个过程比较耗时(也取决当前微服的负载),可能会导致用户可能会看到以下提示。  我们正在努力改善这一点,但目前只能建议您保持耐心,等待2-4分钟。 ## 使用指南: 1. 打开应用后,点击底部的"开始使用"按钮。  2. 创建管理员账号。这是Open-WebUI项目的内部管理员,与懒猫微服的管理员不同。  根据您实际的信息填写即可,这个我填写为以下信息,邮箱可以填一个不存在,并没有校验,只是用来区分多用户。  3. 选择默认模型"builtin-qwen2.5:0.5b"开始对话。  在您选择模型后,就可以在输入框中进行询问,但需要注意的一点是,**目前模型首次加载很慢** 这个我们还在优化中...  4. 使用其他模型,可以在左上角中的选项中进行搜索,如果已经下载,则可以直接选用,还可以直接从 Ollama 中拉取  **在拉取模型的过程中,如果遇到速度越来越慢,则可以点击右边的 X 按钮,取消后重新拉取,之前的下载的进度会保留**  5. AnythingLLM 应用中,直接使用 Ollama 的 API 接口 第一步,先打开 AnythingLLM 的配置项.  然后点击左侧的 LLM 配置项,在底部的 Base URL 配置中填上 https://lzcollama.$boxname.heiyu.space/lzcollama  **注意替换 $boxname 为您微服名称**
如何用 Open Notebook 打造你的自动化知识播客
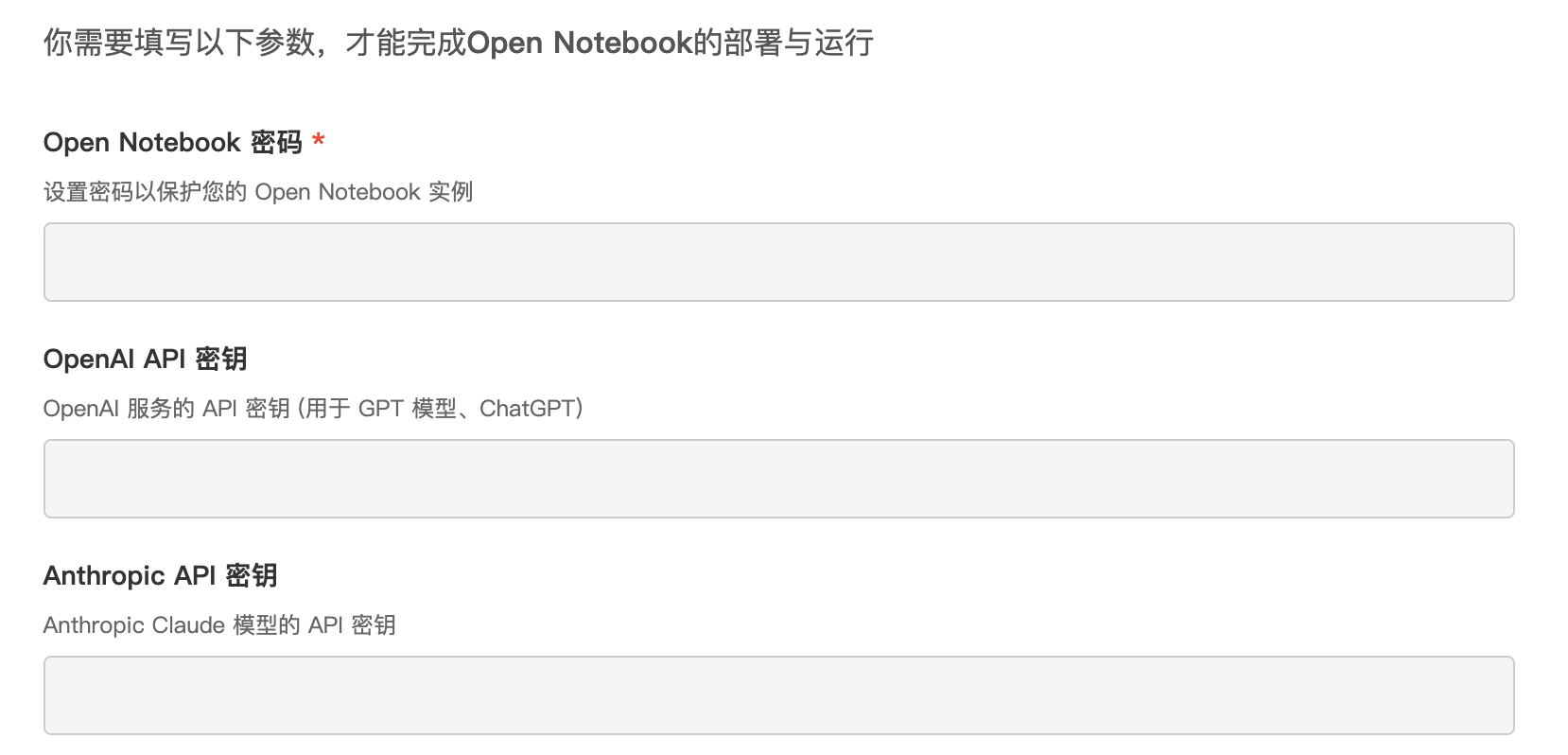
大伙可能都听说过 NotebookLM 了。NotebookLM 是 Google 推出的一款 AI 驱动的研究和写作助手。 它的核心特点是 **“扎根于你的内容”**。你先上传自己的资料(如 PDF、Google 文档、网页链接、视频等),然后 NotebookLM 会基于你提供的这些资料来帮你完成任务,实现高度个性化、可控的“专属知识库”和“AI 伙伴”。 很幸福哈,我们懒猫微服应用商店上架了一个完全私有、本地化的 Notebook https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.opennotebook 这次用一个最简单的例子,介绍 Open Notebook 是如何生成一个独属于你的播客节目 ## 安装 Open Notebook 安装应用是非常简单的,主要是安装之后第一屏的设置。  因为可配置项提供得非常多,这里调几个最常用的必备的配置 首先密码是肯定要设置的,我们跳过这一项。 直接来到这里:  如果你有官网 DeepSeek 账号,并且有充值可以用 API,可以直接将你申请到的密钥填到这里。 但是下面这个可能才是有懒猫的猫友必填的一个配置。 Ollama API 你可以在你的电脑上运行 ollama,然后将你电脑的内网地址直接贴到这里。但是你也可以选择在懒猫微服安装一个 ollama https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.lzcollama 那么你的地址可以填写: ``` https://lzcollama.${微服名称}.heiyu.space/lzcollama ``` 因为官方这个 ollama 应用我看到有用 Intel OpenVINO 加速,所以直接在懒猫跑参数量不大的模型速度还是可以的。跑一个 embedding 模型应该是最常用的选择 当时如果你恰好财力雄厚拥有算力仓,你可以安装这个 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.webollama 地址填这个: ``` https://ollama-ai.${微服名称}.heiyu.space ``` 那么恭喜你,你将享受完全的私有化!连 AI 服务都是私有化! **以上配置适合所有可以配置 ollama 的地方**,各位可以举一反三 接下来是这个,注意一下自己使用的服务,这会影响生成播客功能  然后是冗长的 “兼容 OpenAI” 系列配置 什么是“兼容 OpenAI”,就是所有可以用 openai sdk 调用的接口。换句话说,GLM 4.6 就是可以用 openai 调用的,ollama 其实也是兼容 openai sdk 的。  因为我们用的服务可能万国造,所以 Open Notebook 把所有用到的功能都独立可配置 OpenAI 兼容配置。这样方便我的 embedding 使用 qwen,文本转语音和语音转文本使用 Fish Audio,大语言模型问答直接使用 GLM 4.6 等  所以不用慌,是因为自定义程度比较高造成的看起来配置很多,很多配置都可以放空不配置 ## 初看 Open Notebook Open Notebook 最重要的就是笔记本(Notebook),AI 会围绕你建立的笔记本进行问答。 所以我们第一步:先去配置模型  然后,先建立一个 Notebook  这里我用 Hacker News 举例子  创建好之后是这样的  让我们添加第一个资源  可以看到,Open Notebook 的功能也很丰富  如果填链接的话,它会自己抓这一页网页的内容(但不是爬虫,如果你需要爬取一个网页的内容,建议结合一些自动化工具完成),这里我填了HN的地址,然后直接点 Done 等待一会,就会发现这个资源已经准备好了  你可以添加任何跟你想要创建的这个“笔记本”相关的内容,然后就可以在最右侧的 Chat with Notebook 开始问答了。 例如,我想问“最近大家都在关注什么技术问题,用一句话回答”  ## 对我的知识生成一个播客吧 Notebook LM 一开始最迷人的功能就是可以针对你的知识生成一个对答的播客访谈节目,在 Open Notebook 也可以。 首先进入播客功能   这里用我自己配置的商业分析,来针对刚刚抓的这个知识生成一个播客。 点击生成播客  选择好自己的 notebook,写上标题,就可以让 Notebook 开始生成播客了,我们要做的只有等。**如果你想生成中文的播客,记得在附加提示词里写:使用中文**  这样就是开始生成了  生成完成之后是这样的,点开可以看到播客的目录和播客的字幕  ## 没有合适的文本转语音服务? 巧了,懒猫微服的商店里有一个可以称之为“专武”的应用 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.edge-tts 这个应用有多好用?我们下一篇攻略见
懒猫算力仓初探(三):如何SSH免密登陆以及配置免密sudo?
https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.lzcollama 在拿到懒猫AI算力仓之后,除了插显示器操作,更常见的方式是通过 SSH 远程管理。这样不仅方便日常使用,也能在不接显示器的情况下完成调试和部署。本文将一步步演示如何用 SSH 登录算力仓,并配置免密登录与免密 sudo,让远程操作更高效、更顺滑。 懒猫算力仓启动后,我们可以通过 **SSH** 来进行远程管理。设备出厂时已默认开启 SSH 服务端,所以我们要做的第一步是获取它的 IP 地址。 ### 一、获取IP地址 如果你使用路由器,可以在路由器后台查看分配到的 IP,并用 `telnet ip地址` 测试端口是否开放:  如果外接了显示器,也可以直接在终端执行: ```bash ip addr ``` 懒猫算力仓的默认用户名和密码都是 `nvidia`,所以我们可以直接尝试登录: ```bash ssh nvidia@192.168.1.100 ``` 首次登录会提示是否接受 `fingerprint`,输入 `yes` 即可。 ### 二、配置 SSH 免密登录 每次输入密码太麻烦,可以配置免密登录。 1. **在本地生成 SSH 密钥**(如果还没有): ```bash ssh-keygen -t rsa -b 4096 ``` 一路回车,默认生成在 `~/.ssh/id_rsa` 和 `~/.ssh/id_rsa.pub`。 2. **将公钥拷贝到目标机**: ```bash ssh-copy-id nvidia@192.168.1.100 ``` 如果目标机没有 `ssh-copy-id`,可以手动追加: ```bash cat ~/.ssh/id_rsa.pub | ssh nvidia@192.168.1.100 "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys" ``` 以后只需执行: ```bash ssh nvidia@192.168.1.100 ``` 就能直接登录而无需密码。  ### 三、使用 `~/.ssh/config` 简化命令 如果你经常要连同一台设备,可以在本机配置 SSH 简化命令。 编辑: ```bash vim ~/.ssh/config ``` 添加配置: ``` Host orin HostName 192.168.1.100 User nvidia Port 22 IdentityFile ~/.ssh/id_rsa ``` 保存后,就可以直接: ```bash ssh orin ``` 配合免密登录,体验更流畅。  ### 四、配置免密 sudo Ubuntu 上免密 `sudo` 有两种方式: #### 方式一:直接修改 sudoers 文件 进入算力仓: ```bash sudo vim /etc/sudoers ``` 找到: ``` root ALL=(ALL:ALL) ALL ``` 在下面新增: ``` nvidia ALL=(ALL:ALL) NOPASSWD:ALL ``` 保存退出即可。 #### 方式二(推荐):新建 sudoers.d 配置文件 这样不会污染原始配置,更安全: ```bash echo "nvidia ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/nvidia sudo chmod 440 /etc/sudoers.d/nvidia ``` ### 五、验证配置 1. 尝试免密 SSH 登录。 2. 登录后执行: ```bash sudo ls /root ``` 如果无需输入密码,说明免密 sudo 已生效。 ### 六、SSH 常见排查方法(通用 Linux) 如果 SSH 无法登录,可以按“本地 → 网络 → 服务端 → 配置”逐步排查: #### 1. 确认基本信息 * 用户名、IP 是否正确: ```bash ssh user@192.168.1.100 ``` * 如果端口改过,需显式指定: ```bash ssh -p 2222 user@192.168.1.100 ``` #### 2. 本地网络检查 * 测试连通性: ```bash ping 192.168.1.100 ``` * 确认端口是否开放: ```bash telnet 192.168.1.100 22 # 或 nc -zv 192.168.1.100 22 ``` #### 3. 服务端检查 * 确认 SSH 服务是否运行: ```bash sudo systemctl status ssh # Ubuntu/Debian sudo systemctl status sshd # CentOS/RedHat ``` * 若未运行,启动并设置开机自启: ```bash sudo systemctl enable ssh --now ``` #### 4. 防火墙/安全组 * Ubuntu: ```bash sudo ufw status sudo ufw allow 22/tcp ``` * CentOS/RHEL: ```bash sudo firewall-cmd --permanent --add-service=ssh && sudo firewall-cmd --reload ``` #### 5. SSH 配置文件 检查: ```bash sudo nano /etc/ssh/sshd_config ``` 关键项: ``` Port 22 PermitRootLogin no PasswordAuthentication yes ``` 修改后重启: ```bash sudo systemctl restart ssh ``` #### 6. 日志排查 * Ubuntu: ```bash sudo tail -f /var/log/auth.log ``` * CentOS: ```bash sudo tail -f /var/log/secure ``` #### 7. 权限检查 确保 `.ssh` 目录和文件权限正确: ```bash chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys ``` 通过本文的步骤,我们完成了以下几件事: 1. 使用 SSH 登录懒猫算力仓; 2. 配置 SSH 公钥,实现免密登录; 3. 利用 ~/.ssh/config 简化连接命令; 4. 配置免密 sudo,省去输入密码的麻烦; 5. 提供了常见 SSH 故障的排查方法。 这样配置下来,你就能在懒猫算力仓上实现“一步登录 → 直接 sudo”的丝滑体验。无论是本地调试模型,还是在局域网中远程部署服务,你都能做到“一条命令直达 root 权限”。这让懒猫算力仓真正变成了一个可以随时掌控的 AI 算力伙伴
懒猫评分/评论
5.0
1 条评论

新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
v0.21.0 - 升级 Ollama 到 v0.30.7 版本 - 升级 Open WebUI 到 v0.9.6 - 2026-06-10 版本
Konata9
10/11/2025
应用是很好的,但是 Open-Webui 的版本还会更新吗?因为版本有点低,像 qweb3 9b 就下载不了了