
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

ComfyUI
最强大且模块化的视觉人工智能引擎与应用程序
安装次数
点赞
应用评论
催更次数
桌面端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
ComfyUI允许您使用基于图形/节点/流程图的界面来设计和执行先进的 Stable Diffusion 管道
相关攻略


算力舱绘图教程(2): 提示词优化
上一篇: [算力舱绘图教程(1): 文生图提示词架构](https://lazycat.cloud/playground/guideline/1326) https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 首先,上一次的提示词是这样的: >长得像日本明星的年轻女孩,活力偶像,皮肤白晳红润,黑色长直发,有一双会说话的大眼睛,穿着时尚的白色裙子,曼妙的身材,表情温柔生动,微笑地看着观众,眼中透出一抹淡淡的忧伤。背景是虚化的现代都市,阳光洒在她的脸上。专业杂志封面人像摄影师的杰作,高清照片。   其实我觉得已经很美了,基本上能切中我的审美,但是总觉得还有点“不食人间烟火”?换句话说就是“AI味”还是存在。 我们能不能再优化或修改一下以便生成更自然的图像呢? 首先让我们分解一下提示词的结构: # 提示词的基本结构 上次说到这个基本结构是【人物特征+场景+色彩光线+风格】,分解开就是: -【人物特征】长得像日本明星的年轻女孩,活力偶像,皮肤白晳红润,黑色长直发,有一双会说话的大眼睛,穿着时尚的白色裙子,曼妙的身材,表情温柔生动,微笑地看着观众,眼中透出一抹淡淡的忧伤。 -【场景】背景是虚化的现代都市 -【色彩光线】阳光洒在她的脸上 -【风格】专业杂志封面人像摄影师的杰作,高清照片 我们会发现人物特征说得特别多,其他部分就比较粗略,那么就让我们先在公式中增加更多的“参数”。 ## 丰富场景 场景要有真实感,就要加上互动的内容,比如都市就要有行人和车。另外为了突出主体,我们要在开始就保持背景的模糊。 >背景是焦外虚化的现代都市,行人快乐而轻松,公交车和汽车来来往往留下慢速曝光的动感模糊  ## 丰富光线 阳光是很好的光线描述词,但只有阳光就会比较“干巴”,正常来说皮肤这么白嫩的小姐姐不会站在直射的阳光下吧?或许这就是我们觉得不够自然的地方。 >阳光洒在她的脸上,投射出淡淡的树影。  ## 定义服装 只说裙子,AI就会搞得很简单,多少要加一点式样。这里只露肩就好了,你可以学习一下服装设计的词汇找到更多款式描述。 >她穿着时尚的露肩白色裙子  ## 定义动作 手是人类很重要的“表情”部分,手不动的话,人物就比较死板。虽然现在的AI可以把体态姿势做得比较自然,但是还是要有手的动作描述会更好。 >双手交握在胸前。  >露齿微笑,微微侧身,双臂交叉在胸前。  # 更多的细节 上次有说到“美”和“美感”,以及画面与观众间的“共鸣”,记得吗? 没有什么比一些巧妙的小细节更容易打动观众以生成这种共鸣了。 细节就是你看到/或想象到某个具体元素后,继续探索视觉/思维后的新发现。比如发型、配饰、首饰…… 让我们随意增加一点细节: >黑色长直发,发梢有深紫色渐变,背着单肩银色漆皮小挎包,耳朵上有精致的银色耳环,戴着细细的银色项链  这样,整个画面的内容够丰富了,经过适当的修饰,现在完整的提示差不多是这样的: >长得像日本明星的年轻女孩,活力偶像,皮肤白晳红润,黑色长直发,发梢有深紫色渐变,有一双会说话的明亮大眼睛,穿着时尚的白色露肩裙子,裙边有银色装饰花边。性感的身材,表情温柔生动,微笑地看着观众。露齿微笑,微微侧身,双臂交叉在胸前。眼中透出一抹淡淡的忧伤。背景是焦外虚化的现代都市,行人快乐而轻松,公交车和汽车来来往往留下慢速曝光的动感模糊。阳光洒在她的脸上,投射出淡淡的树影。专业杂志封面人像摄影师的杰作,高清照片。  很像写小说是不是?毕竟写小说时的人物/景物描写其目的也是在读者脑中显示一幅画面。 可是……是不是还有什么不对劲? -- # 缺陷美 所谓“AI味”,不光是指手指数量不对、四肢扭区、细节错误这些老问题。有时候过于完美才是硬伤。 正所谓“有缺陷才是完美的”,连缺陷都没有怎么能称得上完美呢? 所以有时候为了追求我们习惯的“凡间的美”,即真实感、接地气,我们需要人为给描述加一点不完美。 因为之前说过了,“你不说AI怎么会知道呢?”,你不提AI还以为你就是要无缺陷的画面,就像前面提到的阳光和手,不太合常理或不自然就会美得不真实。 你可以在任何地方试着增加“必要的缺陷”,但在这里让我们只是去掉原先提示中的“专业杂志封面人像摄影师的杰作,高清照片。”,改为: >不完美的手机拍摄照片,轻微抖动的模糊边缘, 漏光,过曝。 *小技巧:必要时可以在参数中试着降低一点cfg值,让AI“较少遵守提示要求”,以便"更有缺陷"。但这个数值如果过小会降低生成质量,比如结构出错。另外对于Flux系模型官方不建议改cfg(默认1),只有SD和Qwen效果好些。*   # 最终提示 现在结果是这样的: >长得像日本明星的年轻女孩,活力偶像,皮肤白晳红润,黑色长直发,发梢有深紫色渐变,有一双会说话的明亮大眼睛,穿着时尚的白色露肩裙子,裙边有银色装饰花边,戴着银色珍珠耳环。性感的身材,表情温柔生动,微笑地看着观众。露齿微笑,微微侧身,双臂交叉在胸前。眼中透出一抹淡淡的忧伤。背景是焦外虚化的现代都市,行人快乐而轻松,公交车和汽车来来往往留下慢速曝光的动感模糊。阳光洒在她的脸上,投射出淡淡的树影。不完美的手机拍摄照片,轻微抖动的模糊边缘, 漏光,过曝。   英文版: >A young girl who resembles a Japanese celebrity, a vibrant idol, has fair, rosy skin, long straight black hair with a dark purple tint at the ends, and bright, expressive eyes. She wears a stylish white off-the-shoulder dress with silver trim. She wears small silver pearl earrings and a small silver patent leather shoulder bag. With a voluptuous figure and a gentle, lively expression, she gazes at the viewer with a smile. She grins, leans slightly to the side, and crosses her arms. A hint of melancholy lingers in her eyes. The background is a modern city with a blurred, out-of-focus image. Pedestrians are happy and relaxed, while buses and cars pass by, leaving a slow-motion blur. Sunlight falls on her face, casting a faint shadow of the trees. The imperfect photo, taken with a mobile phone, shows slightly shaky, blurred edges, light leaks, and overexposure. Flux1 Krea dev生成的结果可能更加自然:   到目前为止,虽然提示词我们还可以继续优化下去,但感觉继续美化的意义不大了。 现在我们知道了只要遵循固定的架构和足够详细的内容,就可以生成美感度足够高的图片。你可以任意修改其中的关键词来生成更多不同的美图。  下一篇我们讲一下如何更好地修改内容风格并尽可能发挥你的想象力。

在ComfyUI里使用Flux Kontext魔改图片
https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 首先你需要安装ComfyUI及AI浏览器,安装Flux Kontext模型(参见我之前的攻略),并打开ComfyUI官方模板“Flux Kontext Dev(基础)”。  选择并上传你想要转换的图片,在绿色框中输入提示词。  由于Flux Kontext对自然语言的理解非常好,所以只要自然的去说你需要什么风格就好了。比如: ## 写实转动漫 > change this image to anime manga style, thin strokes, bright flat pastel color, lower satuation, keep the character's pose and expression, keep the face features  | |---|---| ## 动漫转写实 > change this image to a realistic photo, perfect lighting, change this character to a real person, but keep the character's pose and expression, keep the face features  | |---|---| ## 修改某一特点 比如修改衣服的颜色,但保持画面风格: > change the character's outfit to scarlet red, keep the style and other fatures of the image | |---|---| ## 参考图片 你也可以只要一张图片的绘画风格和角色,用它来做参考画其他的主题 >use this image's style, to create a image of cat girl standing on hoverboard flying over a cyberpunk city sky | |---|---| Flux Kontext(全称 FLUX.1 Kontext)是德国 Black Forest Labs 推出的一系列先进的 多模态图像生成与编辑模型。它不仅能进行传统的文本生成图像(Text-to-Image),更擅长在已有图像基础上,通过自然语言提示进行精准编辑和风格转换。 在懒猫的ComfyUI中可以顺畅运行Flux Kontext,修改一张1024x1024的图片大约只需要200多秒。 Flux Kontext的强大功能还可以对你的图片进行更多的魔改,等待你来发掘。

算力舱绘图教程(1): 文生图提示词架构
这是一篇理论攻略,出发点来自老王问我怎样优化绘画提示词。 所以这里的内容将不仅适用于算力舱的ComfyUI之类,也适应于SD webUI,以及外部的ChatGPT、Nano Banana、豆包等其他AI绘画应用。 我将主要使用AI算力舱内置的ComfyUI,主力模型是Qwen-image和Flux1 Krea dev。 至于ComfyUI及相关模型的基本应用,在之前的攻略里已经说过了,不放在这个系列里,需要的话请移步: - [使用ComfyUI进行AI绘画](https://lazycat.cloud/playground/guideline/1191) - [ComfyUI:用Qwen-Image一键出封面图](https://lazycat.cloud/playground/guideline/1194) https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 提示词架构总的来说就是怎样描述出你想要的画面。 --- 但是首先,让我们提一个问题: # 什么是“美”和“美感”? 根据柏拉图的说法,在类似天国一样不可触及的“完美国度”中,每样事物(包括你我)都有一个完美的范本。(反过来说,现实世界中不可能存在“完美”。) 你我所认为的凡间“美”的事物,只不过是在忽略了我们注意不到(或下意识忽视)的瑕疵之后,其绝大部分刚好符合我们心中对那个完美范本记忆的映象,会引起我们对那个完美国度的怀念,仅此而已。 这样说有点玄,但可以有更现实的解释: 当你看到一个画面,它能勾起你曾经的某个美好回忆或者符合你的某个美好幻想,让你感觉似曾相识,甚至可能勾起你五感的刺激,甚至心理上的共鸣,我们就称其为“美”。 “美”和“美感”并不是一回事。 大家公认的“美”,可能更多包含了人类生理上或共识上的认同,比如协调感、变化感、匀衡感、统一感、矛盾感……色调搭配是不是舒适、人物五官是否协调、穿戴搭配是否有创意、表情是否生动……这些造就了我们公认的对“美”的定义。 但每个人的“美感”又可能不同,同一样东西可能不同人的感受不同。生命和大自然有其美感,死亡和灾难也可能有其美感(要么你为啥爱看暴力或灾难片?),当然还有颓废美感(摇滚)、变态美感(你懂的)或其他。 我的一个美术老师对我说过:美就是统一与变化。我觉得可以扩充一下:美就是统一与矛盾的协调旋律。 为什么说这么多?我们要优化提示词,本质目的就是要指导AI既要符合大众共识的“美”、又要符合你或观众的“美感”。 # AI“眼"中的世界 AI是没有物理眼睛的,它对世界外观的理解来自于海量的图片训练数据,并且只能用算法去理解这些数据。所以AI的理解与人脑的理解区别,有点像早先的模拟图像到数码图像的转换,甚至跨度要更大、区别要更细密。 在AI对绘画的理解里,有个潜空间(latent)的概念,这个潜空间是一个多维空间,里面有几十几百甚至可能成千上万个矢量维度。  这些维度是什么呢?很难用人类能理解的语言去描述,但是用简化的类比大致可以这样说: - 比如颜色的色相可以矢量化成一个色轴,类似于我们常见的彩虹色。 - 比如光线的明暗可以矢量化成0-255(或者更细密)的亮度轴。 - 比如角色的年龄从幼到老、从高到矮、从胖到瘦都可以是不同的维度。 - 比如风格从抽象到卡通到写实照片,也能理解成风格维度。 - 甚至可以加入一个稳定/扰乱维度,用其随机位置控制输出内容的不同(种子) 当AI输出一张图片,我们可以理解中它在这个超空间中通过参数坐标及算法找到了一个各维度的交点,这个交点就是这张图片本身,它表现了上述N个参数的集合。 如果这个交点刚好与你的“美感”相切合,你就会认为这张图是“美”的,反之就会觉得有哪里不对劲。 # 人脑的潜空间 人脑的想象和审美也可以理解成同样的潜空间,或者说AI的潜空间是人脑潜空间(可意识到部分的)的超集。 但由于我们无法像AI一样精确控制自己的具象思维(除非终身训练的天才画家才能接近),所以可以说人脑的潜空间里面只是一些混沌离散且模糊的坐标点。 那么当优化提示词时,你需要做的就是把你人脑潜空间里那个混沌坐标提取出来,用文字描述成AI潜空间里,用矢量维度和算法能聚焦和表达的交点。 长远来讲,你可能甚至要反向揣测和估摸AI可能会怎样理解和表达某些概念,但这就需要长期摸索和训练了。 你可能会觉得,文字会有信息损失和表达局限。这是自然的,但不要紧,AI的强大能力之一就是预测和完善,你没表达全的部分参数,AI会用预测值和随机值给你补全。 同时,因为观众脑内坐标也是模糊的,所以这个坐标只要在大致上能和观众脑内潜空间的混沌坐标能产生共鸣就行了。 如何把握这个模糊的“度”并尽可能多产生“共鸣”,就是绘画提示词工程里最重要的部分。 # 完整表达你的意图 AI不是你肚子里的蛔虫,所以你想要的一定要说出来,你不想要的也要避免或否定。否则其他的部分只能靠AI揣测和随机补全,其结果可能不符合你的要求也是理所当然的事情,怪不得AI。 想象有一个公式,或者有一个程序,它有一百个参数,而你只填写了其中一个,其他的使用随机值,那么出来的结果能达到你的预期吗? 我们固然不可能描述所有细节,填完所有的矢量参数,但把脏活累活交给AI去做之前,至少要把你想要的(或不想要的)明确地传达给AI才行。 要做好这一点,可能需要长期的摸索、参考别人的作品、与AI磨合、学习更多美学、观察更多的细节、幻想更多场景等。 但要做到生成的图片基本“可看”并不难,其实就像写小说差不多,你要描绘一个人物角色,或者铺设一个场景,就必须专注描写你能想到的所有细节,用足够的篇幅去完善文字,尽可能让读者理解你脑中的那个幻想。 所以提示词架构的第一步,你只要能够完整表达意图就可以了。 # 提示词架构实例 下面让我们画个美女(以下主要使用Qwen-image)。 首先,你不能只说“画一个女人”,AI会画成这样:   你要“美女”自然至少要说上“美”。 当然你可以只说“画一个美女”,然而虽然能保证基本漂亮,但AI画出来是这样:  还不错不是么?至少比上面的好些,但不太能满足我们的要求,她可能并不是我们在提出需求前设想的那个样子,至少远远不能满足我的“美感”。 让我们来正式搭建这个提示词: > 长得像日本明星的女孩,年轻活力,皮肤白晳红润,黑色长直发  如果没有特殊要求,你并不需要特别说明“双眼皮”、“卧蚕”、“皓齿红唇”、“年龄20岁上下”。这些属于传统的“美”,现代的绘画模型都可以默认地从“像日本明星的女孩”中预测到了你喜欢“东方式美感”和特征及年龄等需求,从而理解并为你填充参数。 那么什么是你为了更多“美感”而需要去完善的呢?让我们接着扩展: >长得像日本明星的女孩,年轻活力,皮肤白晳红润,黑色长直发,**有一双会说话的大眼睛,穿着时尚的白色裙子,曼妙的身材**  现在的结果,严格来说不能说比上一张“更美”,但可以说“更符合我的美感”。 符不符合你的美感我不知道,毕竟美感每个人是不同的,我们只能适应一部分人的美感。 那么再进一步: >长得像日本明星的女孩,年轻活力,皮肤白晳红润,黑色长直发,有一双会说话的大眼睛,穿着时尚的白色裙子,曼妙的身材,**表情温柔生动,微笑地看着观众,眼中透出一抹淡淡的忧伤。**  *【小技巧】我在这个“统一”的美中增加了一点“矛盾”,让它多了一点忧伤感。当然不一定非得忧伤,可以是爱意、倔强、憎恨等任何你想要的词。总之在统一中增加矛盾,就会产生更多的情感变量,更容易让人产生“心理共鸣”,让画面更“生动”(虽然这张图中AI处理得有点过)。* 接下来,由于我不太喜欢这个阴郁的调调、俯视的视角和半截马路牙子的背景: >长得像日本明星的女孩,年轻活力,皮肤白晳红润,黑色长直发,有一双会说话的大眼睛,穿着时尚的白色裙子,曼妙的身材,表情温柔生动,微笑地看着观众,眼中透出一抹淡淡的忧伤。**背景是虚化的现代都市,阳光洒在她的脸上。** AI自动调整了视角以符合都市背景,阳光也冲淡了忧郁的调调,但是你可以注意到眼中“淡淡的忧伤”仍然存在,而且不像之前那么矫情了。  最后,我们增加照片风格的描述,以保证在其他模型上也能稳定输出,同时给画面再增加一点氛围: >长得像日本明星的年轻女孩,活力偶像,皮肤白晳红润,黑色长直发,有一双会说话的大眼睛,穿着时尚的白色裙子,曼妙的身材,表情温柔生动,微笑地看着观众,眼中透出一抹淡淡的忧伤。背景是虚化的现代都市,阳光洒在她的脸上。**专业杂志封面人像摄影师的杰作,高清照片。**   提示词工程里还有很多“小技巧”但这里先不提,由于AI模型本身就默认理解为照片,而我只加了一句简单的照片风格说明,我们可以看到画面的主体没怎么变,但是人物的动作更加自然了。 这样,【人物特征+场景+色彩光线+风格】,一个最基本的提示词架构就搭好了。 现在让我们把这段提示翻译成英语(大部分非国产模型还是更认英文),喂给其他模型: > A young girl who resembles a Japanese celebrity, a vibrant and charming idol, with fair and rosy skin, long, straight black hair, expressive large eyes, wearing a stylish white dress, a graceful figure, a gentle and lively expression, smiling at the audience with a hint of melancholy in her eyes. The background is a blurred cityscape, with sunlight softly illuminating her face. A masterpiece by a professional magazine cover portrait photographer; high-resolution photo. ## Flux1 Krea dev   ## Flux dev 全量   ## Stable Diffustion 3.5   不同模型的风格略有不同,有些模型表达还是不够自然,但我们已经基本上保证了画面丰富度和美感。 下一篇中让我们试着再进一步优化提示。

使用ComfyUI进行AI绘画
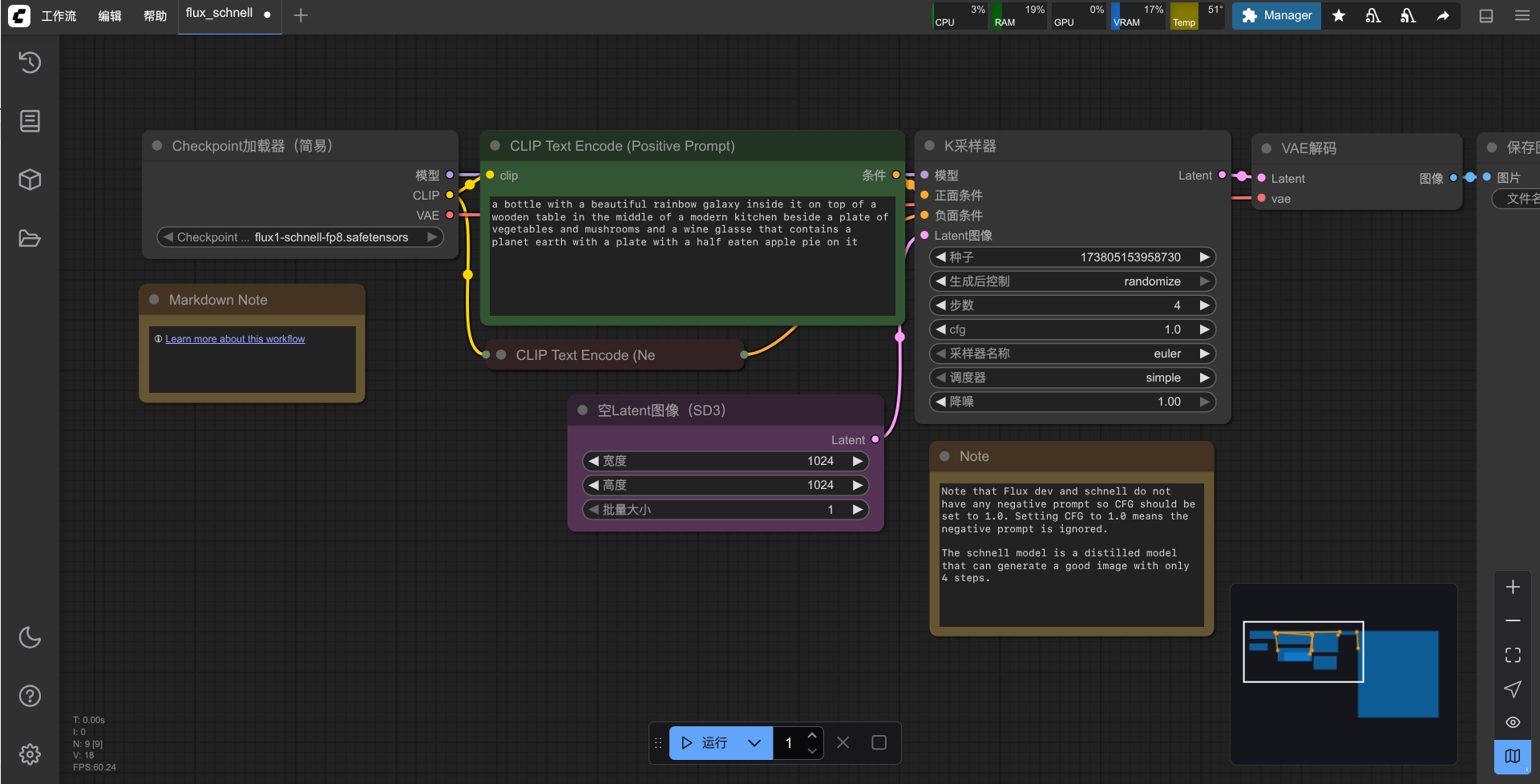
https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 首先,在应用商店安装了ComfyUI应用之后,是需要在懒猫AI浏览器中使用的。安装完之后你可以在浏览器的初始页面看到这个ComfyUI的图标。  打开之后的初始页面,有三个链接,开始创作就是打开ComfyUI本身,文件管理器可以在线打开Comfy的user目录,你可以在里面管理所有的模型和图片文件。第三项文档会链接到官方的教程和文档库。  选择第一项“开始创作”就进入ComfyUI的画布界面了。 如果你完全不了解ComfyUI的工作流方法,最简单的开箱即用方式,就是从官方内置的模板库开始了。  # 打开模板 这里不建议从第一个默认的文生图开始,因为那是基础的StableDiffusion 1.5模型,如果用基本的提示不用LoRA,结果不会太好看,而且也发挥不出懒猫设备的能力。  如果你需要通用又保质量的图片,建议使用Qwen-Image、Flux 1 Krea Dev、或基本的Flux 1模型这三个模板。 其中Qwen对于中文提示的支持很好,生成文字也很厉害,图片质量有基本保证。但缺点是人物基本上都长一个样。  Krea版的Flux美感要高于Qwen和基本Flux。但缺点是风格上有一点单调,对于一些特别的提示表现也不是很好。  基础Flux 1,尤其是Flex Dev全量,可以让成非常精细的图片质量,对照片风格的图片非常好,对提示的适应性也很好。缺点是审美比较依赖提示词,而且dev全量会比较慢。  如果你偏爱二次元动漫风格,那么SDXL是非常好的选择,在civitai之类的网站上,兼容于SDXL的checkpoint和LoRA也很多,尤其是某特“特定”风格。  # 下载模型 当你打开一个工作流,如果你缺少相应的模型,应用会提醒你下载它。这时如何点击下载,是会下载到你本地电脑的,这会有点麻烦。建议是复制URL,然后用SSH登录设备用wget拷贝过去,放在ComfyUI的model文件夹里相应的位置就可以了。  或者用另一个方式,记住你需要下的模型,关掉提示框,打开顶部的Maneger窗口,从窗口中间的Model Manager中下载。  在这个界面中搜索相应的模型并选择Install,就可以在后台自动下载模型到相应的目录了。  # 生成图片 当模型下载完成,不要被复杂的工作流吓到,在这里你其实需要注意的只是两个主要部分,一个是提示词,一个是图片尺寸。 我们以Flex 1 Krea dev为例,因为Flex系列是没有反向提示词的,所以只需要在正向提示词框中填入你想要的提示词,然后在尺寸节点输入图片尺寸(这里建议在1024x1024或相当像素数的分辨率)。 如果你需要更精细的控制,比如一次生成多张图(同样的种子以便抽卡选图),可以调整“批量大小”,但生成的时间会相应的加倍。 采样器中的“步数”是指降噪的步数,可以提高图片的精致度,但会花费更多的渲染时间,并不需要太高。 CFG是“服从率”,这个值越高,AI生成的图片就会更加符合你的提示词,但是相应的会降底一些审美,太高的话甚至质量会很差或直接崩掉。  最后,你只要点击右下角那个蓝色的“运行”按钮(旁边可以设置重复次数),就可以生成图片了!  顺便推荐我的原创应用: https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.aispellbook 它可以帮你更好地组织提示词,不妨试试😺

使用ComfyUI把图片动起来
ComfyUI不只是AI绘图,还能做视频,这你知道的吧? 我在之前的攻略《[使用ComfyUI进行AI绘画](https://lazycat.cloud/playground/guideline/1191)》介绍了用Flex Dev绘图,下面介绍一下图生视频。 你将需要AI算力舱,并安装ComfyUI。 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 首先我会使用这张图样用懒猫AI文生图绘制的猫咪图片:  打开ComfyUI之后,忽略默认打开的SD1.5工作流,直接从左上角菜单打开“浏览模板”  从“视频生成”类选择Wan 2.2 14B Image to Video。 当然,Wan 2.2也支持文生视频,但文生视频对于提示词的要求更高些,我会在以后再讲解。  初次打开会要求下载两个超巨大的模型,因为我已经下载过了就不再截图了,我记得大约每个是14G左右,总共是28G,需要等待足够的时间。 下载完之后工作流自动打开,这个模板是使用双模型渲染,所以相对比较复杂。如果你用过古老的SDXL可能会熟悉双模型,在这里我会详细解释一下。  Wan2.2 t2v有两个模型文件,分别是: * wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors * wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors 顾名思义,high-noise用来进行高噪声生成,会让画面有更多的创意和变化,low-noise用来降低噪声,让结果更符合初始画面和符合提示词。两个模型要分别处理生成过程的前半段和后半段,其中Step的分配比例可能会很大地影响到结果的动感和质量。 首先让我们在图片输入节点上传之前那张小猫的图片。  再在绿色的提示框输入提示词,红色的反向提示可以直接保留。 初始提示词: > 生气的小猫咪,抬起爪子向镜头抓来,动感夸张的社交媒体GIF动画,低帧率快速动画,大幅度的动作,强烈的冲觉冲击感,有趣的运镜。  然后要设置图片的大小,这张图我打算生成动画表情包,所以使用微信表情包的图片大小240x240,这样生成速度也比较快。帧数我想要36帧(会被自动校正为37)。  如果你在意质量,可以保留模板中的现有步数设计(25步),但是我的要求不高,而且求快,所以我要将总步数设置为15步。 这里你会看到两个K采样器,分别对应前面提到的high-noise和low-noise模型。第一个停在第5步,第二个从第5步开始走完剩下的10步。  点击“运行”按钮,你会从顶部进度条看到AI开始工作了。你也可以点击右上角的图标查看动态日志。  按上述的尺寸和步数设置,生成一段动画只需要两分钟。  嗯,动起来了,运镜尚可,可是动画感不够强烈,可能是AI并不太理解猫需要什么动作。 让我们优化一下提示词,给它一个明显的动作: > 生气的小猫咪,抬起爪子向镜头抓来,动感夸张的社交媒体GIF动画,低帧率快速动画,大幅度的动作,强烈的冲觉冲击感,有趣的运镜。 小猫咪听话(并生气)地挥舞起了爪子: 接下来我们进行传说中的抽卡,就是多生成几份挑选最好的,反正无限Token不是么?    让我们把提示词再优化一点,加上镜头动作: >生气的小猫咪,抬起爪子向镜头抓来,动感夸张的社交媒体GIF动画,低帧率快速动画,大幅度的动作,强烈的冲觉冲击感。有趣的运镜,镜头在爪子抓来时快速后退,仿佛在躲避爪子,镜头晃动但始终对准小猫,镜头晃动时有一点跑焦,但很快又恢复了自动对焦。   从此表情包自由了。 

算力舱ComfyUI:主流模型生成插画评测
由于总是用算力舱~~不务正业~~生成图片,所以我打算做一系列针对各主流模型绘制不同风格的性能和质量评测。 由于懒猫算力舱内置支持ComfyUI,所以可以自由下载各种常用的绘画大模型,加上可以独立运行,所以就成了一个很好的图片生成工厂。 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 本次将主要针对插画风格的图片进行测试,选用了两个提示词,用同样的参数对Flux1 Krea dev / Stable Diffustion 3.5 / Qwen-image / SDXL / Flux Dev 全量这五个(我常用的)模型进行对比。 # 参数 ## 提示词1 提示词: >a girl holding flowers in her hands, the bouquet is made of various colorful and beautiful plants, dark purple background, white shirt, digital illustration style, bright light on face, half body portrait, glowing highlights, glow effect, high contrast, surrealism, fantasy, art by ryo takemasa, tatsuya tanaka, makoto shinkai, studio ghibli style 翻译过来是: >一个女孩手里拿着鲜花,花束由各种五颜六色美丽的植物制成,深紫色背景,白色衬衫,数字插图风格,脸上明亮的光线,半身像,发光的亮点,发光效果,高对比度,超现实主义,幻想,艺术,来自武政谅,田中达也,新海诚,吉卜力工作室风格 这个提示词的意图是营造一种清新梦幻的风格,其中:武政谅是风格很清新明快的插画师;田中达也是微摄摄影师,风格细腻安静;新海诚和吉卜力就不用多说了,都是以风格清新闻名。 ## 提示词2 >a full-body character concept art of a demon geisha wearing black and red with devil horns, holding a small kitten in her hand, in the style of minjae lee. the background is simple, and the artwork is a digital illustration in a vector style painting with a detailed design and full color. 翻译 >一个全身的角色设定,恶魔艺妓穿着黑色和红色的衣服与魔鬼的角,手里拿着一只小猫,Minjae Lee的风格。背景很简单,艺术品是数字插图,矢量风格绘画,有详细设计和全色。 这里的Minjae Lee并不是明星李敏宰,而是一个韩国艺术家,插画风格比较繁杂细致(这里也可以看看AI认不认识此人) ## 测试时使用的通用参数: 尺寸:928x1232 步数:20步 ---- # 测试结果对比 ## Flux1 Krea Dev  ### 生成时间:图一120秒 图二125秒  优点:画面很细腻,Krea特训过的模型人物本来就有一种特有的白净感,加上提示词中艺术家的描述后更加增强了这种风格,所以画面显得很干净,同时有很均匀的朦胧光晕。 缺点:并不是数字插画而是动漫风格,不过因为引用了新海诚和吉卜力,所以也不能说偏离太过,但这个风格更像是动画片里的场景。  优点:果然是Krea的白净感,各方面表达都不错,艺伎的表现很好 缺点:不是矢量感,猫不够生动。 ## SD 3.5  ### 生成时间:图一100秒 图二99秒  优点:画面细致感足够高,因为要求的是数字插画,所以风格在动漫和写实之间,略带一点3D的感觉。光线从顶部洒下对花的渲染很好。 缺点:有点矢量或3D感,而且把这两种风格混合了,虽然都不偏离数字插画的风格,但这种风格其实较少见。花的顶部有些过于散乱,整体美感还差点意思。  优点:出乎意料的细致,有日本风,或许理解了李敏宰画家的风格。 缺点:不是矢量风,猫动作很怪。 ## Qwen-Image  ### 生成时间:图一212秒 图二209秒  优点:虽然我总觉得Qwen有Flux血统,和Krea风格有时很近,但由于它的架构其实比Flux1要新,至少在语义理解的方面更好一些。这一幅的人物是风格上最接近吉卜力风的(没错,其实吉卜力风并不是你常见到的GPT画的那种),画面美感是这些测试中最好的。 缺点:人物和花的渲染有些过于“平面了”,虽然在提示中并没有要求而且平面也是一种不错的风格,但平面感和光晕背景多少有些不搭。  优点:有日本风,完美理解了矢量感。 缺点:细致并不够,但由于提示是矢量感所以可以理解。 # SDXL  ### 生成时间:图一59秒 图二23秒  SDXL虽然算是应该淘汰掉的模型了,但做为二次元风格尤其是**某些内容**的图片主力,其实是我很常用的。但因为传统的XDSL是双模型且效果一般,所以我这里用了一个checkpoint而非原生模型。 优点:风格有强烈的动漫感,色彩明快,突出主要人物,焦点明确。更重要的优点是**生成速度超级快**,大约是其他家的1/2-1/4时间。 缺点:要求是插画而不是漫画,风格较为单一,虽然精度够了,但细节相对较少。  优点:速度极快,只有23秒,用时为Qwen的1/10。 缺点:完全没有理解风格和内容要求,风格单一,甚至理解为整个人坐在手上,手的结构还出错了。(虽然产生了意外的趣味) ## Flux Dev 全量  ### 生成时间:图一130秒 图二145秒  优点:作为原生的FLux,其实它本身定位和主打是绘制写实照片,所以画倒这个水平其实是超出预期的,细致感很高,表达也很好。 缺点:光影有点怪,较强的线条感导致更加“动漫”,立体感和质感不强。  优点:中规中矩理解了要求,风格虽然不是矢量感但也比较平面。 缺点:尾巴结构有误,神态和整体美感比较一般。 ---- # 总结 模型|Flux1 Krea Dev|Stable Diffusion 3.5|Qwen-image|SDXL|Flux dev |---|---|---|---|---|---| 速度|约120秒|约100秒|约210秒|小于50秒|约130秒| 质量|++++|+++|++++|++|++ 理解力|+++|++|++++|++|+++ 美感|++++|+++|+++|+++|++ 特点|美感相对高,质量优秀|比较通用,时有惊喜|符合需求,复杂理解较好|求快,二次元|在插画方面无明显优势 总之:Krea相对来说各方面比较平衡,美感有保证,速度也可以接受。SD3.5相对来说也能符合一般的要求。Qwen除了速度较慢,理解能力很好,美感也能兜底。SDXL超快,如果喜欢二次元可以尝试。原生FLux感觉存在感不强,同样要求不如试试Krea版。

用AI做猫娘3D手办
首先你需要ComfyUI。 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 在官方模板中随便打开一个绘图应用,我这里用的是Qwen-Image,因为它对中文支持得很好,省心。 提示词: > 生成一个卡通玩偶的三视图,用来生成3D模型,要求标准视角,形象是可爱的猫娘 如果你用的是英文模型,也可以试试这个提示: > fashion doll, cat girl, blindbox, solid white background  | |--|--| | 图片有了,下面是3D的模型,同样在Comfy中打开官方3D模型,这里三个都可以选,但其实最简单的图生模型就够了,后面的多图和Turbo时间会久一些。  一般来说正面图就很好,所以从刚才生成的图片中截取正面的部分就可以了。  如果你想要多图,就分别截取出不同的角度粘贴进去,大小有点区别不要紧。  但如果你输入的不是方图,可以加一下外补,不然生成的模型可能会在比例上有点被压扁,虽然压扁的轴在3D软件里也很好调整就是了。  3D的模型通常很小,所以生成的时间不会太久,感觉上和生一张高清图差不太多的速度,当然多图的要加倍。 生成完之后,可以直接在结果框中看到预览。  可能因为图上有渐变,有时生成的模型会多出一点平面,只要在3D软件中编辑删掉就好了。 如果你想用外部的3D软件打开,最简单的是用Blender导入。什么?没有Blender?别担心,懒猫的应用商店里也有Blender3D。 https://appstore.lazycat.cloud/#/shop/detail/chestnut.app.blender 呆毛和衣服的花纹都生成出来了。  背后也很完美。  结果相当精细,要拿去打印3D手办还是做动画,就随你怎么玩了。 

ComfyUI:用Qwen-Image一键出封面图
Qwen-Image 是阿里巴巴推出的一款图像生成基础模型,用于文本生成图像(Text-to-Image)以及高精度图像编辑。该模型开源授权为 Apache-2.0。它拥有大约 200 亿参数,采用 MMDiT(Multimodal Diffusion Transformer)架构,专门优化了在图像中渲染复杂文本与多语言内容的能力。 Qwen-Image 可以在图像中准确渲染多行、多语言文本——不仅支持英语,而且对汉字等象形文字也表现非常精准。 首先让我们仍然从ComfyUI开始: https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui  打开官方的Qwen-Image模板,设置你需要的尺寸,为了速度快一些,我使用了约为800x600的幅面。 输入以下关键词: > 制作一张封面图,背景是抽象的科技感电路图,有景深效果,前景是冰蓝色和淡紫色渐变的霓虹效果文字,主标题“懒猫微服”,副标题“实在是很牛逼” 一张简单的封面图就做好了。  由于不是图生图,所以如果你想在上面加图片,需要手动合成,或者使用Comfy的工作流来做。 我们先改变图片的尺寸,约为1200x600,然后修改提示词: > 制作一张封面图,背景是抽象的科技感电路图,有景深效果,前景是冰蓝色和淡紫色渐变的霓虹效果文字,主标题“懒猫微服”,副标题“实在是很牛逼”,图片的左半边只有背景,文字只在右半边,背景要充满画面。 可以看到生成的图片是附合要求的。  然后我们增加一个额外的图片合成流程(都是ComfyUI内置节点)  可以直接拿去做广告了...OK,现在懒猫的设计师可以下岗了(不是 ヾ(≧▽≦*)o  如果不需要合成,你也可以直接输入想要的画面描述,然后带上想要的文字: > 制作一张封面图,背景是一个漂亮的中国女孩,穿着漂亮的职业时装裙,模糊的焦外城市背景,手里拿着一个白色横幅,上面用书法毛笔字写着“用Qwen-image做封面图”  > 制作一张封面图,背景是一个漂亮的中国女孩,穿着漂亮的红色旗袍,模糊的焦外旧上海城市背景,手里拿着一个红色和金色的节庆横幅,上面用书法毛笔字写着“用Qwen-image做封面图”,仿民国时期海报风格  当然,也不一定是封面图,你想要的表情图也可以轻松做好: > 正面顶视图,从上方俯视,一个可爱的20岁中国女孩,黑色长直发,皮肤白晳,羞涩的表情,站在粉色的花田里,身穿白色的连衣裙,曼妙的身材,仰视看向镜头,直视观看者,天真的大眼睛中充满了崇拜,对观看着无比着迷和赞赏的表情,恋爱脑痴情女孩。明亮的阳光照在她的脸上,她的双手握在胸前,表示崇拜和景仰。身边有一个叠加上去的对话气泡,里面用粗体字写着“老王真牛逼!”,对称感的画面布局 
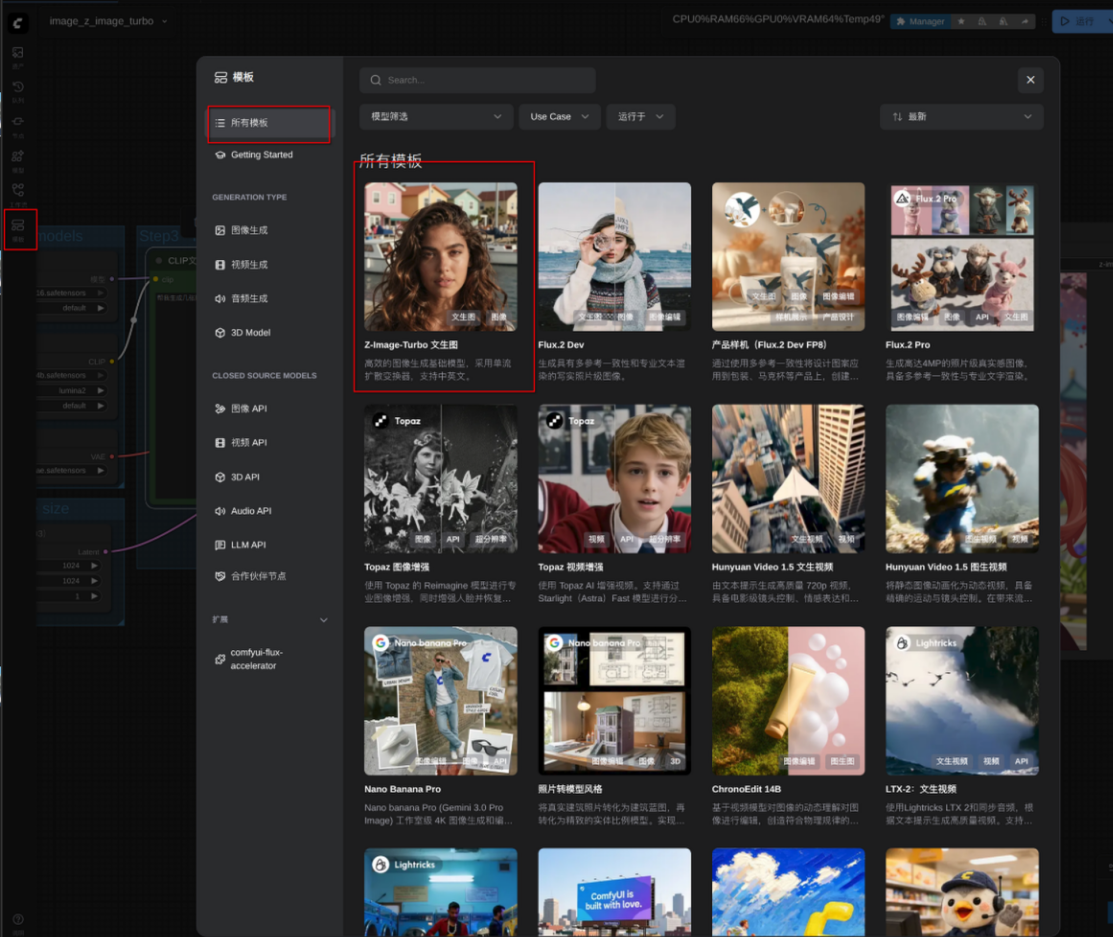
使用comfyui工作流结合算力舱部署z-image生图模型
https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 启动comfyui后在左侧的导航栏中选择模板,所有模板,找到Z-IMAGE-TURBO文生图  comfyui官方的模型库暂时没有收录这个工作流中所需要的模型 您可以导入模板之后点击下载,使用文件管理器上传到对应目录    如果嫌麻烦,或者上传速度不理想,可以直接手动下载到算力舱中的对应目录 ssh进入算力舱 ssh nvidia@算力舱ip 在AI POD中查看算力舱的ip  默认密码为nvidia 进入算力舱,cd到存放模型的目录 cd /ssd/lzc-ai-agent/data/cloud.lazycat.aipod.comfyui/app/models 使用官方工作流需要下载三个模型  分别cd到 text_encoders vae diffusion_models 目录下手动--wget 链接--下载模型 如果您的微服没有做科学,可以使用镜像站下载 wget 将链接字段中的 huggingface.co替换成hf-mirror.com 使用aria2多线程下载,跑满带宽 sudo apt install aria2 (参数说明 -x 16:使用16线程下载 -s 16:将文件分成16块下载 -o 将下载的文件重命名为工作流需要的模型名字) sudo aria2c -x 16 -s 16 下载链接 -o 模型名 eg. sudo wget https://hf-mirror.com/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/vae/qwen_image_vae.safetensors 确保您的算力舱的这三个目录中都有对应的文件  等待模型下载完成后刷新comfyui的页面,就可以开始工作了 在CLIP文本编码中输入您的提示词  点击右上角运行等待生图  开始把玩最新生图模型 
懒猫评分/评论
5.0
1 条评论

新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
v1.0.10 - 升级 ComfyUI 到 0.5.1+ master 分支最新提交 33aa808 - 支持后续升级不丢失安装的自定义节点插件和 Python 依赖
nickfc5104
8/12/2025
电商批量生图神器,非常好用。