
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

喵咒·AI Spellbook
用公式组合变幻无穷的提示词
安装次数
点赞
应用评论
催更次数
桌面端
移动端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
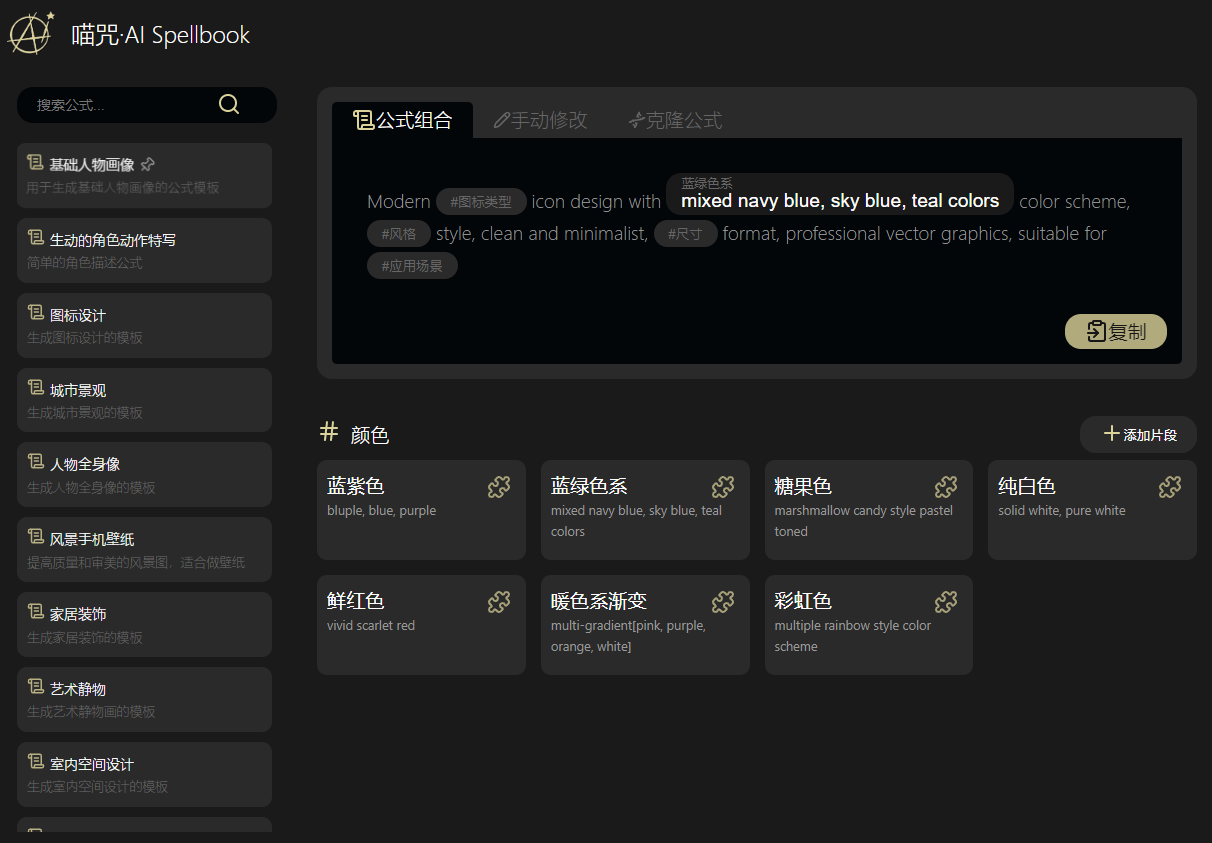
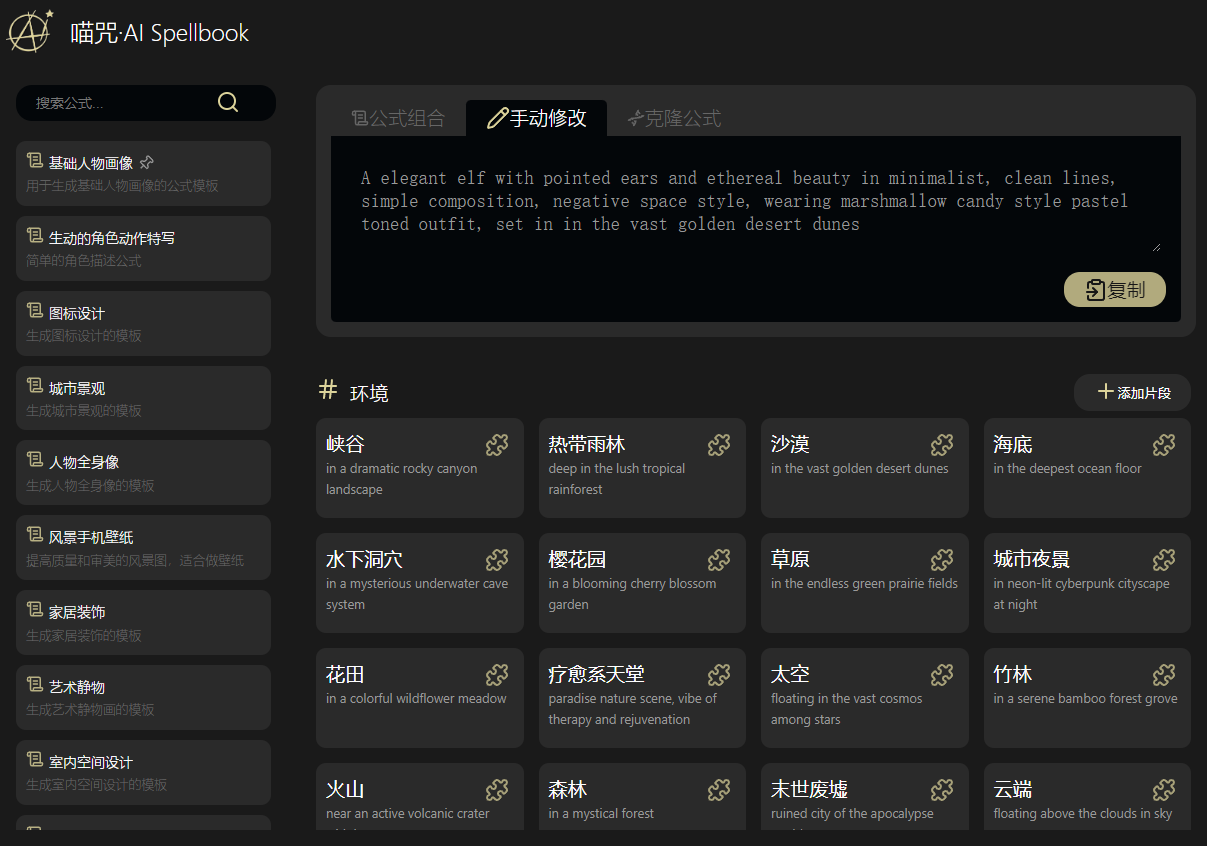
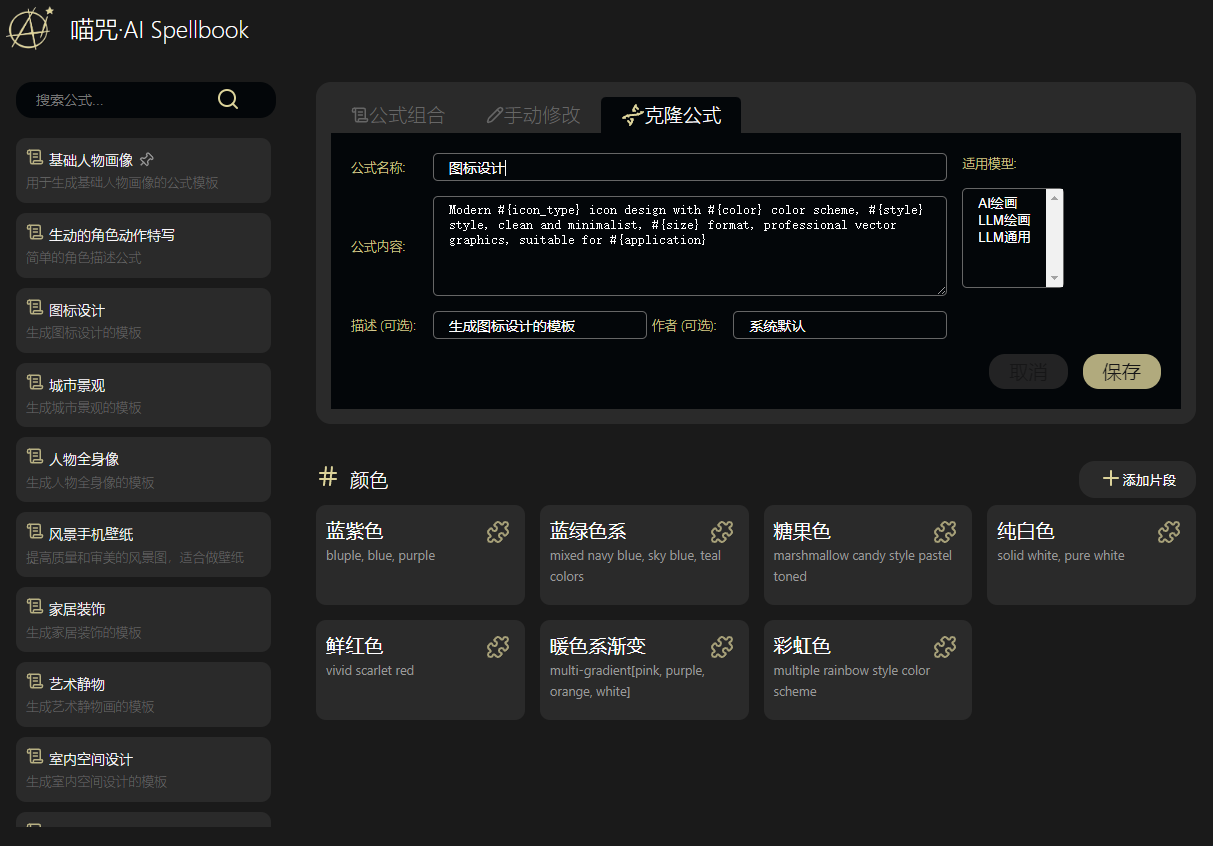
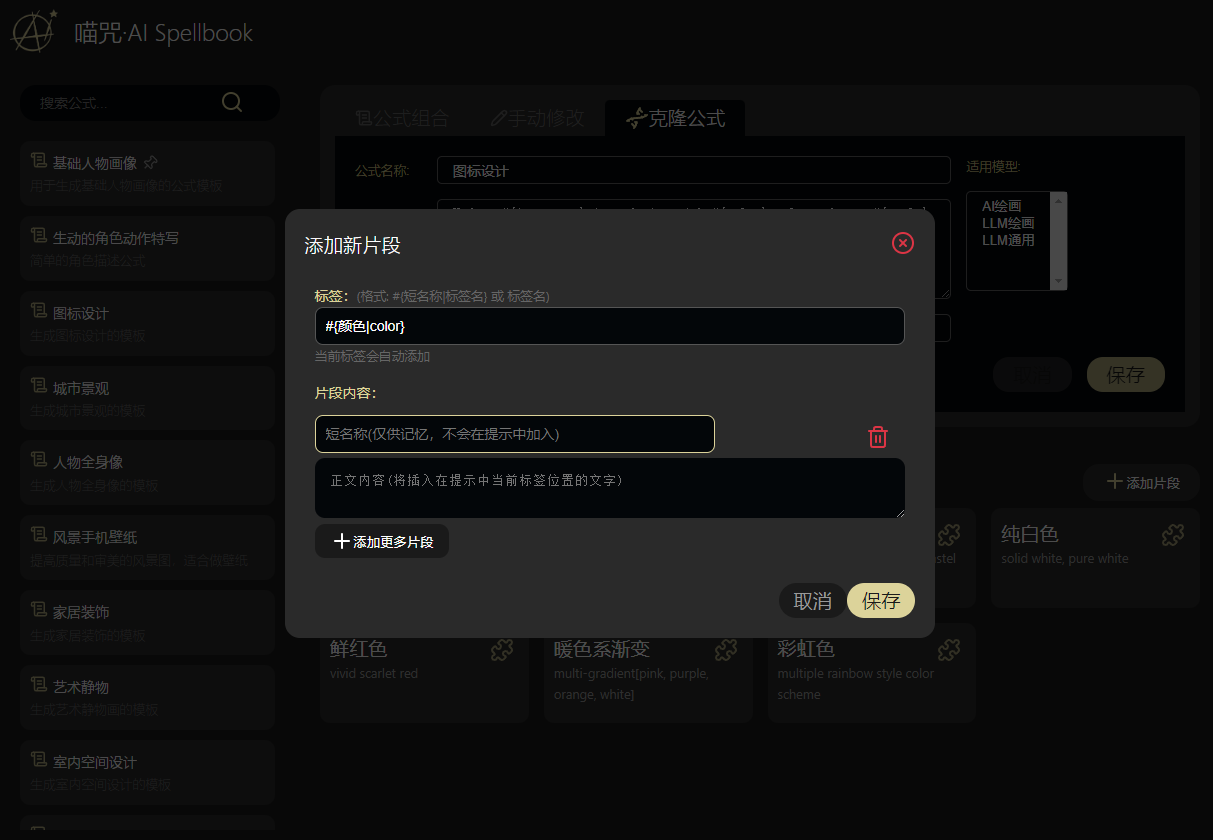
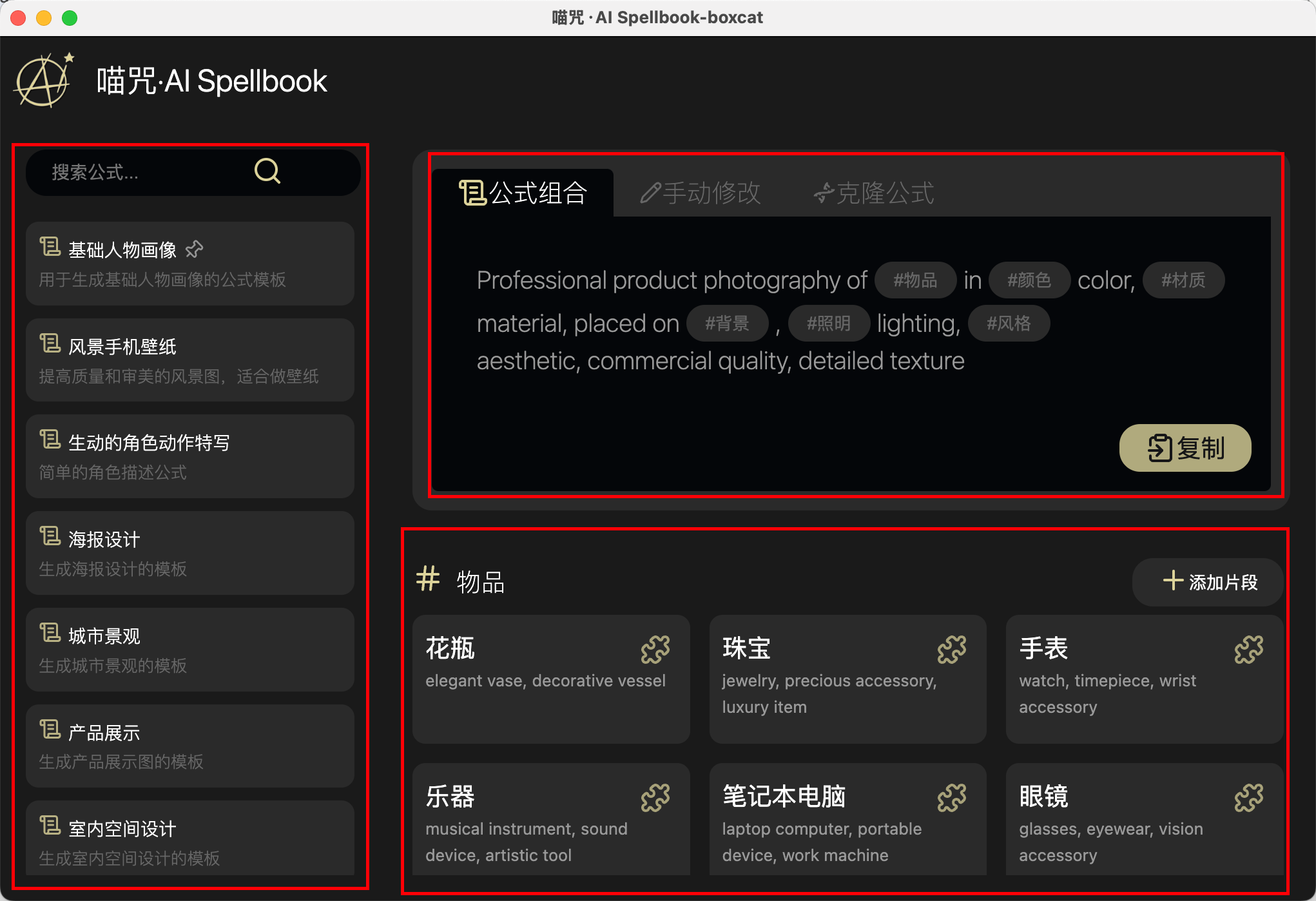
使用方法: 首先选择一个合适的公式,每个公式中可能包含N个#{标签},选择标签后会显示相应的片段列表,选择合适的内容替换进去,最后合成完整的提示词。 现在已支持直接提交到“喵绘·AI文生图”应用(喵绘需要算力舱) 特点: * 用独创的公式法组合AI提示词 * 可以克隆或自建提示词库 * 可以自建标签和片段库 * 轻松点一点拼一拼,就能写出出色的提示词 * 初始化即携带丰富的公式和内容 说明: * 首次打开需要初始化数据,估计最多5秒 * 目前初始数据中只提供传统生成式绘画AI的提示,但你同样可以将其用在LLM的提示中。 * 你也可以自建自己的,针对任何主题的LLM提示库,分类功能即将推出。 * 未来打算尝试接入算力舱,拼好提示一键出图(已实现)。
相关攻略


使用ComfyUI进行AI绘画
https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.comfyui 首先,在应用商店安装了ComfyUI应用之后,是需要在懒猫AI浏览器中使用的。安装完之后你可以在浏览器的初始页面看到这个ComfyUI的图标。  打开之后的初始页面,有三个链接,开始创作就是打开ComfyUI本身,文件管理器可以在线打开Comfy的user目录,你可以在里面管理所有的模型和图片文件。第三项文档会链接到官方的教程和文档库。  选择第一项“开始创作”就进入ComfyUI的画布界面了。 如果你完全不了解ComfyUI的工作流方法,最简单的开箱即用方式,就是从官方内置的模板库开始了。  # 打开模板 这里不建议从第一个默认的文生图开始,因为那是基础的StableDiffusion 1.5模型,如果用基本的提示不用LoRA,结果不会太好看,而且也发挥不出懒猫设备的能力。  如果你需要通用又保质量的图片,建议使用Qwen-Image、Flux 1 Krea Dev、或基本的Flux 1模型这三个模板。 其中Qwen对于中文提示的支持很好,生成文字也很厉害,图片质量有基本保证。但缺点是人物基本上都长一个样。  Krea版的Flux美感要高于Qwen和基本Flux。但缺点是风格上有一点单调,对于一些特别的提示表现也不是很好。  基础Flux 1,尤其是Flex Dev全量,可以让成非常精细的图片质量,对照片风格的图片非常好,对提示的适应性也很好。缺点是审美比较依赖提示词,而且dev全量会比较慢。  如果你偏爱二次元动漫风格,那么SDXL是非常好的选择,在civitai之类的网站上,兼容于SDXL的checkpoint和LoRA也很多,尤其是某特“特定”风格。  # 下载模型 当你打开一个工作流,如果你缺少相应的模型,应用会提醒你下载它。这时如何点击下载,是会下载到你本地电脑的,这会有点麻烦。建议是复制URL,然后用SSH登录设备用wget拷贝过去,放在ComfyUI的model文件夹里相应的位置就可以了。  或者用另一个方式,记住你需要下的模型,关掉提示框,打开顶部的Maneger窗口,从窗口中间的Model Manager中下载。  在这个界面中搜索相应的模型并选择Install,就可以在后台自动下载模型到相应的目录了。  # 生成图片 当模型下载完成,不要被复杂的工作流吓到,在这里你其实需要注意的只是两个主要部分,一个是提示词,一个是图片尺寸。 我们以Flex 1 Krea dev为例,因为Flex系列是没有反向提示词的,所以只需要在正向提示词框中填入你想要的提示词,然后在尺寸节点输入图片尺寸(这里建议在1024x1024或相当像素数的分辨率)。 如果你需要更精细的控制,比如一次生成多张图(同样的种子以便抽卡选图),可以调整“批量大小”,但生成的时间会相应的加倍。 采样器中的“步数”是指降噪的步数,可以提高图片的精致度,但会花费更多的渲染时间,并不需要太高。 CFG是“服从率”,这个值越高,AI生成的图片就会更加符合你的提示词,但是相应的会降底一些审美,太高的话甚至质量会很差或直接崩掉。  最后,你只要点击右下角那个蓝色的“运行”按钮(旁边可以设置重复次数),就可以生成图片了!  顺便推荐我的原创应用: https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.aispellbook 它可以帮你更好地组织提示词,不妨试试😺
还在为“不会写提示词”或“提示词效果差”而烦恼吗?来看看喵咒·AI Spellbook吧!
你还在为使用Ai但Ai无法反馈你想要的内容而烦恼吗?试试这款**喵咒·AI Spellbook**吧,它内置了几类提示语,可以有效的解决你“不会写提示词”或“提示词效果差”的痛点。 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.aispellbook ## 软件介绍 软件总体分为左右两个部分,左侧主要是一些类型,右侧则是当前类型下的提示语模版,模板中的一些片段支持通过选择来进行填充。  ## 软件使用 以产品展示为案例进行演示 **1.选择产品展示,右侧会出现公式,公式支持修改**   **2.在公式里面可以选择片段进行填充,也可以自定义新增片段**   **3.最后的提示语也支持自定义修改**  **4.复制提示语到AI软件获取反馈**

AI文生图提示词实战技巧
https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.aipod.imagen 懒猫官方提供的文生图内核是FLUX引擎,下面我来分享一下使用FLUX绘画时的提示词组织技巧: # Flux 模型 FLUX是由德国黑森林实验室(Black Forest Labs)开发的文字转图像模型,该公司由多位前Stability AI员工创办。 它的特点是: * 语言理解力强:Flux 对自然语言的理解能力比传统 SD 系列好,可以接受更接近完整句子的描述。 * 偏好简洁、明确的提示:冗余和重复的词汇可能会导致输出偏弱,不如精简、分层表达有效。 * 视觉构图导向更强:相比传统 tag 堆叠,Flux 更适合以场景描述、摄影术语、画风修饰结合来组织。 # 基本架构 ## 1. 主体层 明确主要人物、物体、场景的身份和状态,不像SD系列堆关键词,对FLUX用自然语言的主谓宾结构最舒服,也就是采用“谁 + 做什么 + 在哪里(在干什么)”的句式,这样表达最清晰。 例如: > a young female samurai standing in a bamboo forest > a golden retriever dog sleeping on a red sofa ## 2. 细节层 更进一步给你的主体添加造型、特征、动作、神态等修饰信息,或者对环境进行更多描写。 例如: > wearing a traditional kimono with dragon embroidery > soft fur, peaceful expression, curled tail ## 3. 风格层(Style / Medium) 决定画面的整体艺术气质或摄影风格,这里推荐用一些专业术语,如果你不了解专业术语,可以去搜索一些艺术或摄影专业的书籍或网站。 常用结构:in the style of [艺术家 / 流派],例如: > digital painting / watercolor / ukiyo-e / oil painting > cinematic photography / polaroid / 35mm film ## 4. 光影与氛围层(Lighting / Mood) Flux 对光影和氛围的响应很强,建议单独列出。好的光影设计可以完全改变画面的格调。 例如: > dramatic lighting, soft shadows, golden hour sunlight > misty atmosphere, neon glow, cyberpunk city at night ## 5. 构图与镜头层(Composition / Camera) 更偏摄影/电影化描述,用于控制画面布局。这里你就要学一点摄影或摄像相关的专业了,或者使用提示库。 例如: > close-up portrait, wide-angle shot, overhead view > rule of thirds composition, symmetrical balance ## 6. 质量修饰层(Quality Boosters) 用于提高整体质感与细节,相当于给画面最后加一层渲染要求,通常来说都是要求高清的,但有时候加入低质量的要求会更加接近写实的效果。 常用: > highly detailed, ultra realistic, 8k render, masterpiece > intricate textures, sharp focus, vibrant colors # 负面提示词 Flux 的设计初衷是通过精确的正向提示词来引导图像生成,而不是依赖负面提示词来排除不希望出现的元素。 由于FLUX官方并不提供负面提示词,文生图应用中也没有负面提示词的表单项,但是有人还是发掘出一些方法,比如建议在正向提示词中使用否定副词,如“not wearing a ...”,以间接排除不希望出现的元素。 当然,因为AI对语言的理解总是可能不稳定,所以为了避免混乱,大部分情况下还是不建议加入负面提示词。 # 提示词结构模板 虽然自然语言写法比较自由,然仍然有个推荐的提示词结构,模板如下: ``` [主体] + [细节] + [风格/媒介] + [光影/氛围] + [构图/镜头] + [质量修饰] (+ 否定副词 [负面提示]) ``` 比如: ``` prompt a young female samurai standing in a bamboo forest, wearing a traditional kimono with dragon embroidery, focused gaze, digital painting in the style of 70s japanese manga, soft warm light, cinematic atmosphere, rule of thirds composition, highly detailed, vibrant colors, masterpiece ``` >一位年轻的女武士站在竹林中,身着绣有龙纹的传统和服,目光专注,70年代日本漫画风格的数字绘画,柔和温暖的光线,电影般的氛围,三分构图,细节丰富,色彩鲜艳,杰作  ``` prompt a golden retriever sleeping on a red sofa, soft fur, peaceful expression, curled tail, cinematic photography, 35mm film, golden hour sunlight, cozy living room, close-up shot, shallow depth of field, ultra realistic, 8k render, sharp focus ``` > 一只金毛猎犬睡在红色沙发上,柔软的皮毛,平静的表情,卷曲的尾巴,电影摄影,35毫米胶片,黄金时段的阳光,舒适的客厅,特写镜头,浅景深,超逼真,8K渲染,清晰对焦  # 组织技巧与实用建议 根据个人经验,这里还有一些近一步的建议: * 中英文皆可,但实际上还是推荐英文更好。 * 以上的各层次不见得都需要,因为有时随机的效果也不错,只有需要的时候才加更多修饰。 * 虽然推荐,但也不见得完全依照顺序,如果有哪些元素(比如风格、服装)是需要强调的,可以移到最前面。 * 层次分明而非堆叠:避免一口气堆满形容词,按层次逐步添加,Flux 理解更好。 * 少量优先,高权重词精挑:比如“samurai”“golden retriever”这样的核心词不要被稀释。 * 先定大方向,再做精修:先跑几张看整体,再用细节/负面去修正。 * 尝试完整句子:Flux 对接近自然语言的提示很友好,不必完全依赖碎片化 tag。 * 风格控制单独列出:不要把风格和主体混写,否则画面可能混乱。 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.aispellbook 最近夹带点私货,再次推荐我的提示词应用,它基本上是用类似(但更通用)的结构来设计的,可以帮助你组织提示词。  你只要随便点几处鼠标(或手动修改部分关键词),把结果提示词复制进文生图应用,就可以生成高质量的AI图片了。    
懒猫评分/评论
5.0
1 条评论
应用信息
新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
增加将提示词直接提交到“喵绘·AI文生图”算力舱应用以生成图片的按钮,修复部分已知BUG。
金东
5/18/2026
用不了