
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

Dify
llm 工作流
安装次数
点赞
应用评论
催更次数
桌面端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
Dify 是一个基于自然语言处理的代码生成工具,通过自然语言描述生成代码,支持多种编程语言,支持多种代码模板,支持多种代码执行环境,支持多种代码存储方式。
相关攻略

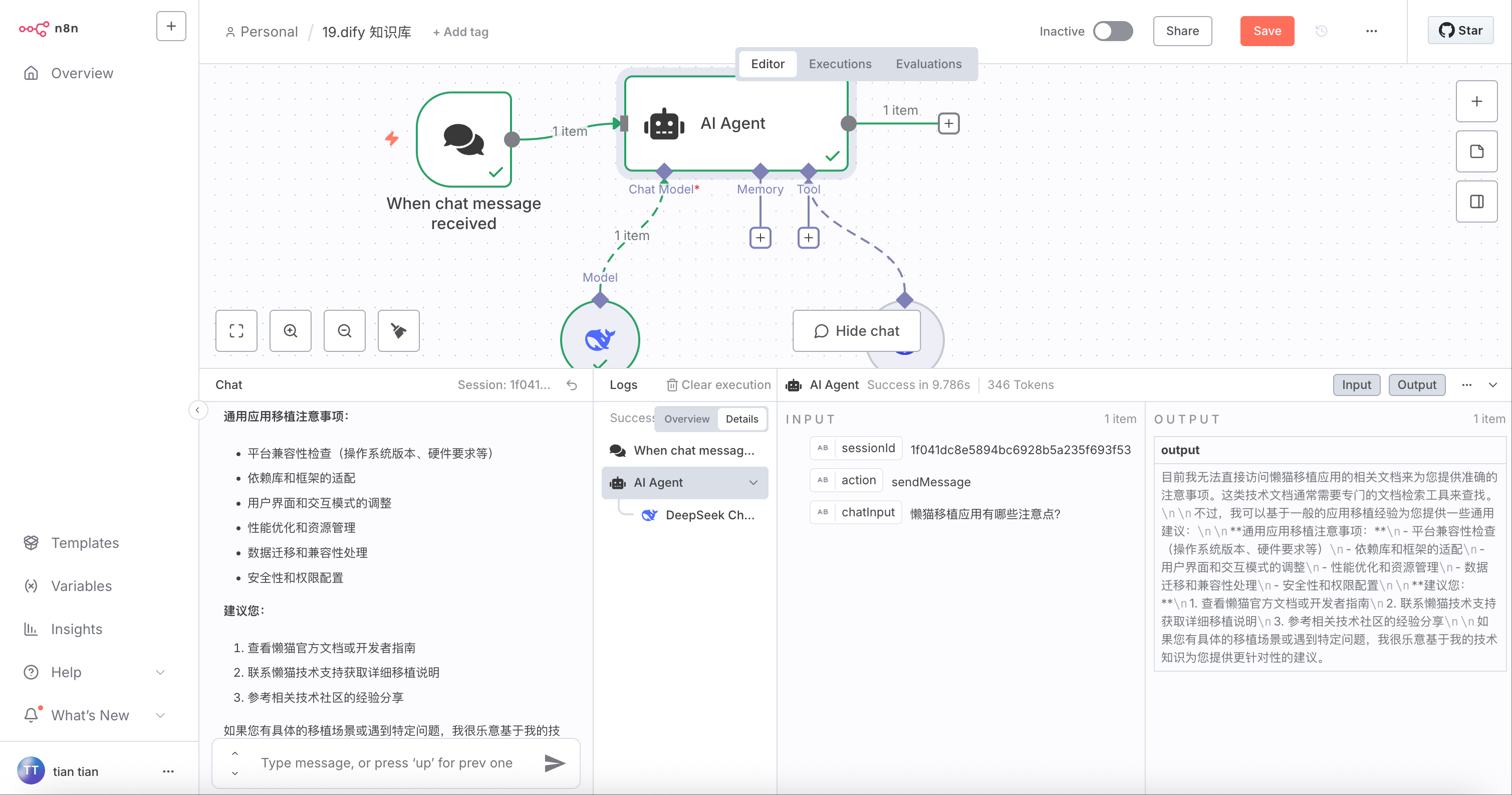
n8n 实操攻略 19:如何给 n8n 接入 dify 知识库
这个攻略是 dify 和 n8n 结合的应用,Dify 和 n8n 都是流行的自动化和工作流工具,但它们的侧重点和使用场景有明显区别: ## 核心定位 **Dify** 是一个专注于 AI 应用开发的平台,主要用于构建基于大语言模型(LLM)的应用。它提供可视化的工作流编排,让开发者能够快速搭建 AI 聊天机器人、知识库问答系统、AI 工作流等应用。 https://appstore.lazycat.cloud/#/shop/detail/dev.libr.dify **n8n** 是一个通用的工作流自动化平台,类似于 Zapier 或 Make(原 Integromat),主要用于连接各种应用和服务,实现业务流程自动化。 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.n8n ## 主要区别 **使用场景** - Dify:构建 AI 驱动的应用,如智能客服、内容生成工具、数据分析助手等 - n8n:自动化日常任务,如数据同步、邮件自动化、社交媒体管理、CRM 集成等 **技术特点** - Dify:内置 LLM 管理、向量数据库、知识库管理、prompt 工程工具等 AI 相关功能 - n8n:提供 400+ 预建集成节点,支持 webhook、定时任务、复杂的条件逻辑等 **目标用户** - Dify:AI 应用开发者、产品经理、想要快速搭建 AI 应用的团队 - n8n:运营人员、自动化工程师、需要集成多个系统的企业 ## 选择建议 如果你的需求是构建 AI 相关应用,特别是需要集成 ChatGPT、Claude 等大模型的场景,Dify 会更合适。 如果你需要的是连接各种 SaaS 工具、数据库、API 来实现业务流程自动化,n8n 会是更好的选择。 两者也可以结合使用:用 Dify 构建 AI 能力,通过 API 暴露出来,然后在 n8n 中调用这些 AI 能力,实现更复杂的自动化工作流。 ## 如何构建 在懒猫商店中,打开 dify,首次启动会比较慢 先设置一个管理员账户  登录后进入首页  点击知识库,创建一个新的知识库  这里,可以导入自己的文档。  我导入了懒猫的开发者文档,方便移植应用 点击下一步  这里默认是 经济,先不要切换到高级,高级要设置模型,但目前用不了  点击 保存并处理,它就会处理你上传的文件了  点击前往文档  知识库的名称可以改一下,方便记忆  能看到我的所有文档了  到了这一步,因为目前的版本不支持模型的安装,我只好挪到了 [dify 的官网](https://cloud.dify.ai/signin)接着操作,前面的步骤都是一致的。 但官网的导入文档只能导入一个(需要花钱升级才让批量上传),所以我用的firecrawl 抓的开发者文档  在这一步就可以选择模型了  点击进入 API  在右上角可以拿到 API 密钥,先保存到本地,待会要用  进入知识库,在这里可以继续添加文件  在这里可以看到红框内的是我们的知识库 Id  到这里 dify 的知识库已经完成了,下面我们要在 n8n 中调用这个知识库。 在 n8n中新建一个工作流  选择你的大模型,这里我用到 DeepSeek,主要配置是右侧的 http Request 节点 把这里的 Id,替换成自己的知识库 Id  请求头里,换成自己的 apikey  点击执行,就可以尽情的向他提问了。 比如问它怎么移植应用,  上面的 json 文件我放在这里了,抄作业的同学可以参考: ``` { "name": "知识库", "nodes": [ { "parameters": { "options": {} }, "type": "@n8n/n8n-nodes-langchain.chatTrigger", "typeVersion": 1.3, "position": [ -256, 0 ], "id": "1ed033dc-26cf-41dc-82a1-589b62687b76", "name": "When chat message received", "webhookId": "c484e9fb-0be4-42dd-bd2b-f9ca059840c0" }, { "parameters": { "promptType": "define", "text": "=先优先查看文档,尽量用文档的东西回答问题,问题:{{ $json.chatInput }}", "options": {} }, "type": "@n8n/n8n-nodes-langchain.agent", "typeVersion": 2.2, "position": [ -48, -16 ], "id": "a0ea8a64-3f7d-4b6b-901b-d6e14ae85f49", "name": "AI Agent" }, { "parameters": { "options": {} }, "type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek", "typeVersion": 1, "position": [ -48, 160 ], "id": "c40685f3-fbbd-46fd-9565-ccaf3f85e0fe", "name": "DeepSeek Chat Model", "credentials": { "deepSeekApi": { "id": "vfn66fhHzd6mF6j1", "name": "DeepSeek account" } } }, { "parameters": { "method": "POST", "url": "https://api.dify.ai/v1/datasets/这里写你的知识库id/retrieve", "sendHeaders": true, "headerParameters": { "parameters": [ { "name": "Authorization", "value": "Bearer 这里写你的知识库api key" }, { "name": "Content-Type", "value": "application/json" } ] }, "sendBody": true, "specifyBody": "json", "jsonBody": "={\n \"query\": \" {{ $json.chatInput }} \",\n \"retrieval_model\": {\n \"search_method\": \"hybrid_search\",\n \"top_k\": 5,\n \"score_threshold_enabled\": false,\n \"reranking_enable\": false\n }\n}\n", "options": { "redirect": { "redirect": {} } } }, "type": "n8n-nodes-base.httpRequestTool", "typeVersion": 4.2, "position": [ 112, 192 ], "id": "ac7cff2a-0b70-4e37-9ea1-21ff0d9109b7", "name": "HTTP Request" } ], "pinData": {}, "connections": { "When chat message received": { "main": [ [ { "node": "AI Agent", "type": "main", "index": 0 } ] ] }, "DeepSeek Chat Model": { "ai_languageModel": [ [ { "node": "AI Agent", "type": "ai_languageModel", "index": 0 } ] ] }, "HTTP Request": { "ai_tool": [ [ { "node": "AI Agent", "type": "ai_tool", "index": 0 } ] ] } }, "active": false, "settings": { "executionOrder": "v1" }, "versionId": "fcca2fde-d07b-41fc-9ec3-d54e42f774d7", "meta": { "templateCredsSetupCompleted": true, "instanceId": "ff06cd56528164550e83a0b0bc9f32963f8355543707a1ed77847e72afe71d53" }, "id": "zL5dlqy4K6nBeBsx", "tags": [] } ```
Dify系列:如何使用插件来接入模型供应商
https://appstore.lazycat.cloud/#/shop/detail/dev.libr.dify 首次打开应用后,点击右上角用户名,点击**设置**  点击模型供应商,会发现这里面没有任何大模型可以选择。因为Dify对于社区版把大模型供应商安装改成了插件安装。  # 下面介绍两种安装方式 > 虽然方式上都是从本地安装。 ## 1. Dify官方市场安装 首先,打开[Dify市场](https://marketplace.dify.ai)  比如我想安装openai兼容的API,方便我接入三方API,那么在搜索框里输入“**openai**”,在搜索结果里选择**OpenAl-APl-compatible**  进入后,点击**安装**是需要输入公网dify地址,所以暂时无法操作,只能先选择**下载**  下载后,我们回到本地Dify,点击**插件**,选择**本地插件**  选择我们刚才下载的文件,dify的插件都是以“**difypkg**”为结尾,前面的0.22就是对应的插件版本号,点击**打开**  在跳出的对话框里,点击**安装**  然后就稍微等待几分钟,插件安装好后,就可以在插件页面看到刚刚安装好的**OpenAl-APl-compatible**  ## 2. 从GitHub仓库下载安装 这是我在网上找到的一个还持续更新的Dify [插件仓库](https://github.com/svcvit/dify_plugin_collection) 打开后,点击**downloads**  这里我们还是选择安装模型供应商为例,选择**model**  这次以**ollama**为例,打开后,我们可以通过按**Ctrl+F**,然后输入**ollama**来快速定位找到**ollama**插件  或者也可以在**go to file**里输入**ollama**,点击所需对应的版本号即可  然后点击右上的下载按钮进行下载  安装方式同上面操作方式一样,安装插件-本地插件-选择文件-安装  > 以上就是两种获取插件的途径以及安装方式。 # 下面进行模型供应商配置三方API。 点击右上角用户,点击**设置**,点击**OpenAl-APl-compatible**右下的**选择模型**  在跳出的对话框,按照要求对应填写即可,可以参考下图,然后点击**保存**  保存后就会出现在模型下方  # 下面来测试一下配置的三方API实际是否连接成功。 点击**工作室**,选择**聊天助手**,点击**创建空白应用**  点击**聊天助手**,应用名称可随意填写,我这边就写了**懒猫微服**,点击**创建**  右上角选择**模型**,因为我只添加了一个**gpt-5**,所以这里就不用修改。然后左侧**提示词**区域填入你需要的提示词。填入后即可在右侧对话框内输入内容,开启对话,可见下图效果。  > 至此,我们就完成了模型插件安装,模型API配置,以及调取模型进行对话的操作了。
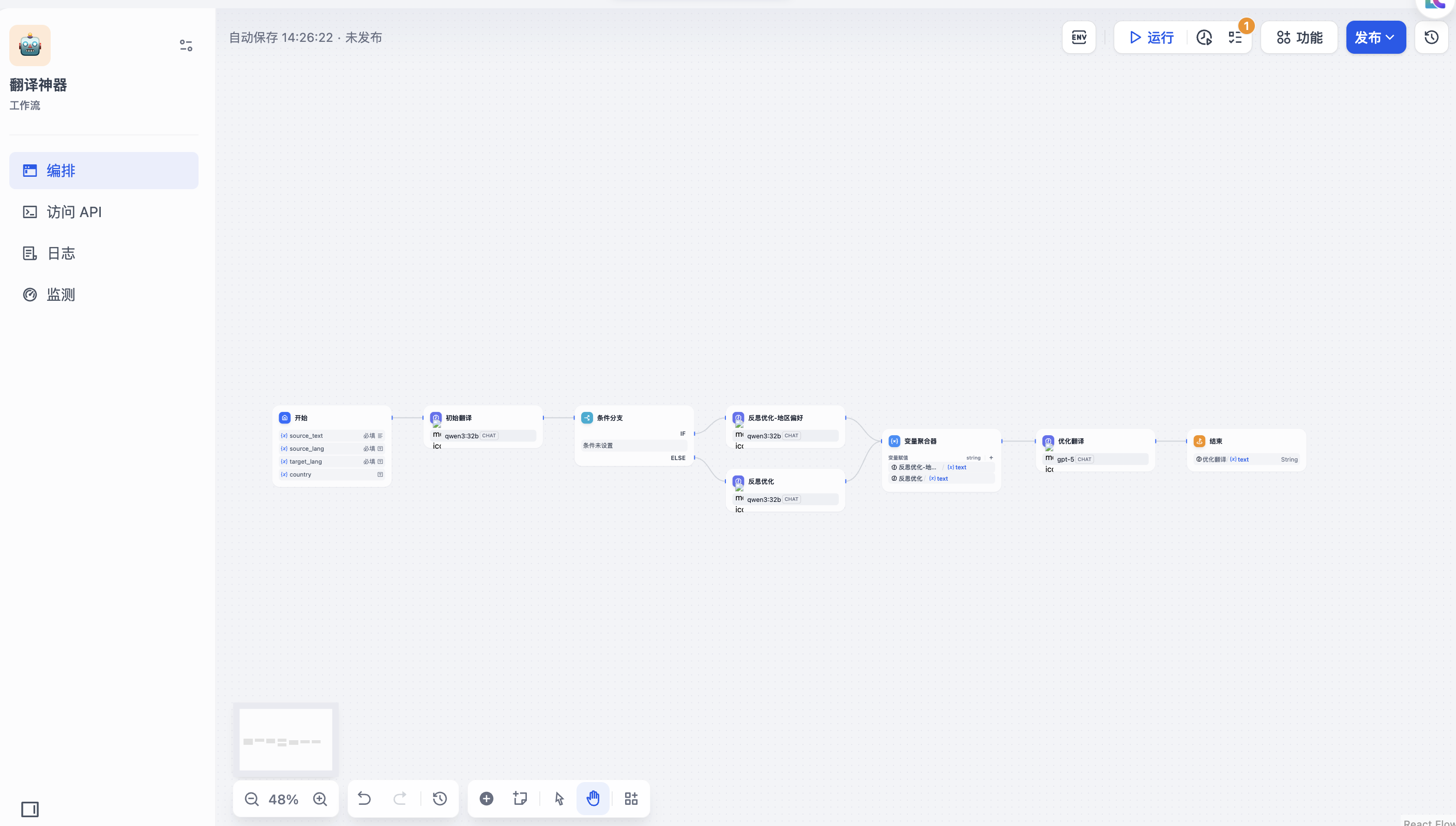
Dify系列:复刻吴恩达翻译神器+调用算力仓Ollama开源模型
https://appstore.lazycat.cloud/#/shop/detail/dev.libr.dify 今天我们就用Dify来复刻一下吴恩达翻译神器,并且调用算力仓Ollama开源模型来解决一下token燃烧的焦虑。 > 注意,调取算力仓模型需要购买一台算力仓才能配合使用哦!!!如无,可以使用其他模型供应商进行测试。 ## 1. 先在Dify里安装Ollama模型插件,进行配置,这里我就直接演示如何配置算力仓模型,点击选择模型,按照要求对应填写,可参考下图。  ## 2. 回到Dify主页,点击**工作室**,点击**创建空白应用**,见下图。  ## 3. 选择**工作流**,应用名称和描述可按需自定义填写,点击**创建**  ## 4. 点击**开始**,在右侧选择加号,进行输入变量配置  ## 5. 在变量对话框里,选择**文本**,按照下面的内容对应添加进去,需要配置4个。除了Souce_text是选择段落外,其余都是文本。 > 输入变量配置: > - source_text: 需要翻译的具体文本内容 > 作用:接收用户要翻译的原文,支持长文本 > > - source_lang: 源语言 > 作用:指定原文的语言,如"English"、"Chinese"等 > > - target_lang: 目标语言 > 作用:指定要翻译成的目标语言 > > - country: 国家地区偏好(可选) > 作用:用于调整翻译风格,使其符合特定地区的语言习惯  下图是添加之后的效果  ## 6. 点击右上角加号,选择**LLM**,进行添加模型供应商  ## 7. 名称改成“**初始翻译**”,右侧SYSTEM里,输入下面的系统提示词,**{source_lang}** 和 **{target_lang}** 请点击“**x**“对应选择替换变量。然后再点击下方**添加消息** > 你是一位专业的语言学家,专门从事{source_lang}到{target_lang}的翻译工作。  ## 8. 在User里添加以下用户提示词,跟上面系统提示词一样,点击”**x**“对应替换变量 > 这是一个从到{source_lang}到{target_lang}翻译任务,请提供这段文本的{target_lang}翻译。 > > 请只提供翻译内容,不要提供任何解释或其他文本。 > > {source_lang}: {source_text} > > {target_lang}:  ## 9. 点击**初始翻译**右上角加号,选择**条件分支**  点击**添加条件**,选择**country**  后面选择**不为空**  下面两个节点也都分别点击**选择下一个节点**  名称改一下,一个为**反思优化-地区偏好**,另一个为**反思优化**。  > 判断逻辑: > - 如果提供了 country 参数: > → 走地区优化的反思优化路径 > - 如果未提供 country 参数: > → 走标准反思优化路径 ## 10. 反思优化节点配置 ### 带地区偏好的反思优化 还是按照上述配置系统提示词和用户提示词,按照下图对应填写,记得对应修改变量 **系统提示词** > 你是一位专业的语言学家,专门从事到{source_lang}的{target_lang}翻译工作。你将获得一段源文本及其翻译,你的目标是改进这个翻译。  **用户提示词** > 你的任务是仔细阅读一段源文本及其从{source_lang}到{target_lang}的翻译,然后给出建设性的批评和有助于改进翻译的建议。 > > 最终的翻译风格和语气应该符合{target_lang}地区的口语表达方式。 > > 源文本和初始翻译用XML标签<SOURCE_TEXT></SOURCE_TEXT>和<TRANSLATION></TRANSLATION>标记如下: > > <SOURCE_TEXT> > {source_text} > </SOURCE_TEXT> > > < TRANSLATION> > {初始翻译的结果} > < /TRANSLATION> > > 在写建议时,请注意是否有以下方面可以改进: > (i) 准确性(通过纠正添加错误、误译、遗漏或未翻译的文本) > (ii) 流畅性(通过应用的语法、拼写和标点规则,确保没有不必要的重复) > (iii) 风格(通过确保翻译反映源文本的风格并考虑文化背景) > (iv) 术语(通过确保术语使用的一致性并反映源文本领域;确保只使用中对等的习语) > > > 请列出具体的、有帮助的和建设性的建议来改进翻译。 > 每个建议应针对翻译的一个具体部分。 > 只输出建议,不要输出其他内容。 ``` 复制粘贴时,把< TRANSLATION>和< /TRANSLATION>前面的空格删掉哦!这里是因为md语法问题不去掉的话无法显示 ```  ### 标准反思优化 跟上面一样进行设置 **系统提示词** > 你是一位专业的语言学家,专门从事到{source_lang}的{target_lang}翻译工作。你将获得一段源文本及其翻译,你的目标是改进这个翻译。  **用户提示词** > 你的任务是仔细阅读一段源文本及其从{source_lang}到{target_lang}的翻译,然后给出建设性的批评和有助于改进翻译的建议。 > > 源文本和初始翻译用XML标签<SOURCE_TEXT></SOURCE_TEXT>和<TRANSLATION></TRANSLATION>标记如下: > > <SOURCE_TEXT> > {source_text} > </SOURCE_TEXT> > > < TRANSLATION> > {初始翻译的结果} > < /TRANSLATION> > > 在写建议时,请注意是否有以下方面可以改进: > (i) 准确性(通过纠正添加错误、误译、遗漏或未翻译的文本) > (ii) 流畅性(通过应用的语法、拼写和标点规则,确保没有不必要的重复) > (iii) 风格(通过确保翻译反映源文本的风格并考虑文化背景) > (iv) 术语(通过确保术语使用的一致性并反映源文本领域;确保只使用中对等的习语) > > > 请列出具体的、有帮助的和建设性的建议来改进翻译。 > 每个建议应针对翻译的一个具体部分。 > 只输出建议,不要输出其他内容。 ``` 复制粘贴时,把< TRANSLATION>和< /TRANSLATION>前面的空格删掉哦!这里是因为md语法问题不去掉的话无法显示 ``` 相比较**带地区偏好的反思优化**少了“**最终的翻译风格和语气应该符合{target_lang}地区的口语表达方式。**”  ## 11. 配置变量聚合器 点击下方加号,选择**变量聚合器**  然后点击了两个反思优化右上角加号,拖拽到**变量聚合器**上  **变量赋值**右侧,点击加号,把**反思优化-地区偏好**和**反思优化**增加进去  点击**选择下一个节点**,选择**LLM**  新节点名称改为**优化翻译**  ## 12. 配置优化翻译 还是按照上述配置系统提示词和用户提示词,按照下图对应填写,记得对应修改变量 **系统提示词** > 你是一位专业的语言学家,专门从事{source_lang}到{target_lang}的翻译编辑工作。  **用户提示词** > 你的任务是仔细阅读并编辑一个从{source_lang}到{target_lang}的翻译,同时考虑专家建议和建设性的批评。 > > 源文本、初始翻译和专家语言学家的建议分别用XML标签<SOURCE_TEXT></SOURCE_TEXT>、<TRANSLATION></TRANSLATION>和<EXPERT_SUGGESTIONS></EXPERT_SUGGESTIONS>标记如下: > > <SOURCE_TEXT> > {source_text} > </SOURCE_TEXT> > > < TRANSLATION> > {初始翻译的结果} > < /TRANSLATION> > > <EXPERT_SUGGESTIONS> > {反思大模型的输出结果} > </EXPERT_SUGGESTIONS> > > 请在编辑翻译时考虑专家建议。编辑翻译时请确保: > (i) 准确性(通过纠正添加错误、误译、遗漏或未翻译的文本) > (ii) 流畅性(通过应用{target_lang}的语法、拼写和标点规则,确保没有不必要的重复) > (iii) 风格(通过确保翻译反映源文本的风格) > (iv) 术语(不适合上下文的术语、使用不一致) > (v) 其他错误 > > 输出: > 只输出新的翻译结果,不要输出其他内容。 ``` 复制粘贴时,把< TRANSLATION>和< /TRANSLATION>前面的空格删掉哦!这里是因为md语法问题不去掉的话无法显示 ```  ## 12. 结束进程 点击**优化翻译**右上角加号,选择**结束**节点  点击**输出变量**右侧加号,选择**优化翻译**即可  > 至此,这个翻译工作流就基本上配置成功了,下面我们就来测试一下实际效果。 # 实际演示 点击**运行**,对应填写相关内容,点击**开始运行**  可以点击**追踪**,查看进度  原文: > In the flood of darkness, hope is the light. It brings comfort, faith, and confidence. It gives us guidance when we are lost, and gives support when we are afraid. And the moment we give up hope, we give up our lives. The world we live in is disintegrating into a place of malice and hatred, where we need hope and find it harder. In this world of fear, hope to find better, but easier said than done, the more meaningful life of faith will make life meaningful. 结束后,点击**结果**,即可看到最终翻译内容  最终翻译: > 在黑暗的洪流中,希望是光。它带来安慰、信仰和信心,当我们迷失时给予指引,恐惧时给予支持。一旦我们放弃希望,就是放弃了生命。我们生活的世界正在崩溃成一个充满恶意和仇恨的地方,我们需要希望,但找到它却比说起来难得多。在这个充满恐惧的世界里,我们渴望找到更好的生活,但信仰赋予生活更深层的意义。 你可以查看**已深度思考**来看看思考过程  至此,整套翻译工作流已正常运行了。点右上角的**发布**就可以在探索里直接使用了。  > 我把这个工作流上传到了网盘里,链接如下。如果失效了,可以在群里找我要。 > https://transfer.it/t/K7Y4EvpTyDbQ
懒猫评分/评论
4.3
4 条评论
新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
"更新上游最新1.13.3、修复模型供应商和本地插件安装错误问题"
nickcc7930
1/9/2026
安装插件会报错
u53180592
10/21/2025
下载完成首次安装插件会报错,Reached maximum retries (3),但实际上我只点击了一次,烦请作者检查一下插件安装这一块是否有Bug
Leo_chen
7/9/2025
能否更新到最新版,另外安装插件会失败,接口访问地址是127.0.0.1