
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

elasticsearch
Elasticsearch 是一个开源的分布式 RESTful 搜索和分析引擎。
安装次数
点赞
应用评论
催更次数
桌面端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
Elasticsearch 是一个开源的分布式 RESTful 搜索和分析引擎。
相关攻略


Elasticsearch 的 CRUD全集
> 本章导读:本章将详细介绍 Elasticsearch 的 CRUD(创建、读取、更新、删除)操作,包括索引管理、文档操作、批量处理和数据迁移等核心功能,帮助读者掌握 ES 数据操作的基础技能。 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch ## 目录 - [前置知识](#前置知识) - [索引操作](#索引操作) - [文档操作](#文档操作) - [批量操作](#批量操作) - [更新操作详解](#更新操作详解) - [数据迁移](#数据迁移) - [实践示例](#实践示例) - [本章小结](#本章小结) - [参考资料](#参考资料) ## 索引操作 索引是 Elasticsearch 中存储数据的逻辑容器。在进行文档操作之前,通常需要先创建和配置索引。 ### 创建索引 #### 基本创建 ```json // 创建一个简单的索引 PUT /products ``` #### 带设置的创建 ```json // 创建索引并指定设置 PUT /products { "settings": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "1s" } } ``` #### 带映射的创建 ```json // 创建索引并定义映射 PUT /products { "settings": { "number_of_shards": 3, "number_of_replicas": 1 }, "mappings": { "properties": { "name": { "type": "text", "analyzer": "standard", "fields": { "keyword": { "type": "keyword" } } }, "price": { "type": "double" }, "category": { "type": "keyword" }, "description": { "type": "text" }, "stock": { "type": "integer" }, "created_at": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" }, "is_available": { "type": "boolean" }, "tags": { "type": "keyword" } } } } ``` ### 查看索引 ```json // 查看单个索引信息 GET /products // 查看索引设置 GET /products/_settings // 查看索引映射 GET /products/_mapping // 查看所有索引(表格格式) GET /_cat/indices?v // 查看索引详细信息 GET /_cat/indices/products?v&h=index,health,status,pri,rep,docs.count,store.size ``` ### 更新索引设置 ```json // 更新动态设置 PUT /products/_settings { "index": { "number_of_replicas": 2, "refresh_interval": "30s" } } // 关闭索引后更新静态设置 POST /products/_close PUT /products/_settings { "index": { "analysis": { "analyzer": { "my_analyzer": { "type": "custom", "tokenizer": "standard", "filter": ["lowercase"] } } } } } POST /products/_open ```  ### 删除索引 ```json // 删除单个索引 DELETE /products // 删除多个索引 DELETE /products,orders // 使用通配符删除(谨慎使用) DELETE /logs-2024-* // 删除所有索引(极度危险,生产环境禁用) // DELETE /_all // DELETE /* ``` > ⚠️ **警告**:删除索引是不可逆操作,请确保已备份重要数据。生产环境建议设置 `action.destructive_requires_name: true` 禁止通配符删除。 ### 索引别名 别名是指向一个或多个索引的虚拟名称,可用于零停机切换索引。 ```json // 创建别名 POST /_aliases { "actions": [ { "add": { "index": "products_v1", "alias": "products" } } ] } // 切换别名(原子操作) POST /_aliases { "actions": [ { "remove": { "index": "products_v1", "alias": "products" } }, { "add": { "index": "products_v2", "alias": "products" } } ] } // 查看别名 GET /_cat/aliases?v GET /products/_alias ``` ### 索引开关 ```json // 关闭索引(节省资源,不可读写) POST /products/_close // 打开索引 POST /products/_open // 查看索引状态 GET /_cat/indices/products?v ``` ## 文档操作 ### 创建文档 #### 指定 ID 创建 ```json // 使用 PUT 指定文档 ID PUT /products/_doc/1 { "name": "iPhone 15 Pro", "price": 8999, "category": "手机", "description": "Apple 最新旗舰手机,搭载 A17 Pro 芯片", "stock": 100, "created_at": "2024-01-15", "is_available": true, "tags": ["苹果", "5G", "旗舰"] } ``` 响应示例: ```json { "_index": "products", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 } ``` #### 自动生成 ID ```json // 使用 POST 自动生成 ID POST /products/_doc { "name": "MacBook Pro 14", "price": 14999, "category": "笔记本", "description": "Apple M3 Pro 芯片,专业级性能", "stock": 50, "created_at": "2024-01-16", "is_available": true, "tags": ["苹果", "专业", "M3"] } ``` #### 强制创建(防止覆盖) ```json // 使用 _create 端点,如果文档已存在则报错 PUT /products/_create/1 { "name": "iPhone 15", "price": 7999 } // 或使用 op_type 参数 PUT /products/_doc/1?op_type=create { "name": "iPhone 15", "price": 7999 } ``` 如果文档已存在,返回 409 冲突错误: ```json { "error": { "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, document already exists" }, "status": 409 } ``` ### 读取文档 #### 获取单个文档 ```json // 获取完整文档 GET /products/_doc/1 // 只获取 _source 字段 GET /products/_source/1 // 获取指定字段 GET /products/_doc/1?_source_includes=name,price // 排除指定字段 GET /products/_doc/1?_source_excludes=description ``` 响应示例: ```json { "_index": "products", "_id": "1", "_version": 1, "_seq_no": 0, "_primary_term": 1, "found": true, "_source": { "name": "iPhone 15 Pro", "price": 8999, "category": "手机", "description": "Apple 最新旗舰手机,搭载 A17 Pro 芯片", "stock": 100, "created_at": "2024-01-15", "is_available": true, "tags": ["苹果", "5G", "旗舰"] } } ``` #### 检查文档是否存在 ```json // 使用 HEAD 请求检查文档存在性 HEAD /products/_doc/1 ``` 存在返回 `200 OK`,不存在返回 `404 Not Found`。 #### 批量获取文档 ```json // 使用 _mget 批量获取 GET /products/_mget { "ids": ["1", "2", "3"] } // 跨索引批量获取 GET /_mget { "docs": [ { "_index": "products", "_id": "1" }, { "_index": "orders", "_id": "100" } ] } // 指定返回字段 GET /products/_mget { "ids": ["1", "2"], "_source": ["name", "price"] } ``` ### 更新文档 #### 部分更新 ```json // 使用 _update API 部分更新 POST /products/_update/1 { "doc": { "price": 8499, "stock": 90 } } ``` #### 使用脚本更新 ```json // 使用 Painless 脚本更新 POST /products/_update/1 { "script": { "source": "ctx._source.stock -= params.quantity", "params": { "quantity": 10 } } } // 条件更新 POST /products/_update/1 { "script": { "source": """ if (ctx._source.stock >= params.quantity) { ctx._source.stock -= params.quantity; } else { ctx.op = 'noop'; } """, "params": { "quantity": 5 } } } // 添加数组元素 POST /products/_update/1 { "script": { "source": "ctx._source.tags.add(params.tag)", "params": { "tag": "热销" } } } // 删除数组元素 POST /products/_update/1 { "script": { "source": "ctx._source.tags.remove(ctx._source.tags.indexOf(params.tag))", "params": { "tag": "热销" } } } ``` #### Upsert(更新或插入) ```json // 如果文档存在则更新,不存在则创建 POST /products/_update/999 { "doc": { "price": 5999 }, "upsert": { "name": "新商品", "price": 5999, "category": "其他", "stock": 100, "created_at": "2024-01-20", "is_available": true } } // 使用 scripted_upsert POST /products/_update/999 { "scripted_upsert": true, "script": { "source": """ if (ctx.op == 'create') { ctx._source.name = params.name; ctx._source.price = params.price; ctx._source.view_count = 1; } else { ctx._source.view_count += 1; } """, "params": { "name": "新商品", "price": 5999 } }, "upsert": {} } ``` #### 完全替换文档 ```json // 使用 PUT 完全替换(会删除未指定的字段) PUT /products/_doc/1 { "name": "iPhone 15 Pro Max", "price": 9999, "category": "手机" } ``` ### 删除文档 #### 删除单个文档 ```json // 根据 ID 删除 DELETE /products/_doc/1 ``` 响应示例: ```json { "_index": "products", "_id": "1", "_version": 2, "result": "deleted", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 } ``` #### 条件删除 ```json // 使用 Delete By Query 删除匹配的文档 POST /products/_delete_by_query { "query": { "term": { "is_available": false } } } // 删除某个类别的所有商品 POST /products/_delete_by_query { "query": { "term": { "category": "过期商品" } } } // 带冲突处理的删除 POST /products/_delete_by_query?conflicts=proceed { "query": { "range": { "created_at": { "lt": "2023-01-01" } } } } ``` ## 批量操作 Bulk API 允许在单个请求中执行多个索引、更新或删除操作,大幅提高数据处理效率。 ### Bulk API 基本语法 Bulk 请求使用 NDJSON(Newline Delimited JSON)格式: ``` action_and_meta_data\n optional_source\n action_and_meta_data\n optional_source\n ... ``` ### 批量索引 ```json POST /products/_bulk {"index":{"_id":"1"}} {"name":"iPhone 15","price":7999,"category":"手机","stock":100} {"index":{"_id":"2"}} {"name":"MacBook Pro","price":14999,"category":"笔记本","stock":50} {"index":{"_id":"3"}} {"name":"iPad Pro","price":8999,"category":"平板","stock":80} {"index":{"_id":"4"}} {"name":"AirPods Pro","price":1899,"category":"配件","stock":200} ``` ### 批量混合操作 ```json POST /_bulk {"index":{"_index":"products","_id":"10"}} {"name":"商品A","price":999} {"create":{"_index":"products","_id":"11"}} {"name":"商品B","price":1999} {"update":{"_index":"products","_id":"1"}} {"doc":{"price":7499}} {"delete":{"_index":"products","_id":"99"}} ``` ### Bulk 操作类型 | 操作 | 说明 | 是否需要文档体 | |------|------|----------------| | `index` | 创建或替换文档 | 是 | | `create` | 创建文档(已存在则失败) | 是 | | `update` | 部分更新文档 | 是 | | `delete` | 删除文档 | 否 | ### Bulk 响应解析 ```json { "took": 30, "errors": false, "items": [ { "index": { "_index": "products", "_id": "1", "_version": 1, "result": "created", "status": 201 } }, { "index": { "_index": "products", "_id": "2", "_version": 1, "result": "created", "status": 201 } } ] } ``` ### Bulk 性能优化 ```json // 1. 合理设置批量大小(建议 1000-5000 条或 5-15MB) // 2. 使用 refresh=false 禁用自动刷新 POST /products/_bulk?refresh=false {"index":{"_id":"1"}} {"name":"商品1","price":100} {"index":{"_id":"2"}} {"name":"商品2","price":200} // 3. 批量完成后手动刷新 POST /products/_refresh ``` **Bulk 最佳实践**: | 参数 | 建议值 | 说明 | |------|--------|------| | 批量大小 | 1000-5000 条 | 根据文档大小调整 | | 请求大小 | 5-15 MB | 避免过大导致内存问题 | | 并发数 | 2-4 | 根据集群能力调整 | | refresh | false | 批量完成后统一刷新 | ### curl 命令示例 ```bash # 从文件批量导入 curl -X POST "localhost:9200/products/_bulk" \ -H "Content-Type: application/x-ndjson" \ --data-binary @products.ndjson # products.ndjson 文件内容: # {"index":{"_id":"1"}} # {"name":"商品1","price":100} # {"index":{"_id":"2"}} # {"name":"商品2","price":200} ``` ## 更新操作详解 ### Update API Update API 用于部分更新文档,只修改指定字段而不影响其他字段。 ```json // 基本部分更新 POST /products/_update/1 { "doc": { "price": 7499, "updated_at": "2024-01-20" } } // 检测是否有实际更改 POST /products/_update/1?detect_noop=true { "doc": { "price": 7499 } } // 强制更新(即使内容相同) POST /products/_update/1?detect_noop=false { "doc": { "price": 7499 } } ``` ### Update By Query Update By Query 用于批量更新匹配条件的文档。 ```json // 将所有手机类商品价格降低 10% POST /products/_update_by_query { "query": { "term": { "category": "手机" } }, "script": { "source": "ctx._source.price = ctx._source.price * 0.9", "lang": "painless" } } // 为所有商品添加新字段 POST /products/_update_by_query { "query": { "match_all": {} }, "script": { "source": "ctx._source.updated_at = params.date", "params": { "date": "2024-01-20" } } } // 带限制的更新 POST /products/_update_by_query?scroll_size=1000&conflicts=proceed { "query": { "range": { "stock": { "lt": 10 } } }, "script": { "source": "ctx._source.is_available = false" } } ``` ### Update By Query 参数 | 参数 | 说明 | 默认值 | |------|------|--------| | `conflicts` | 冲突处理:`abort`(中止)或 `proceed`(继续) | abort | | `refresh` | 完成后是否刷新 | false | | `scroll_size` | 每批处理的文档数 | 1000 | | `wait_for_completion` | 是否等待完成 | true | | `requests_per_second` | 限流(每秒请求数) | -1(不限制) | ### 异步更新 ```json // 异步执行 Update By Query POST /products/_update_by_query?wait_for_completion=false { "query": { "match_all": {} }, "script": { "source": "ctx._source.batch_updated = true" } } // 返回任务 ID { "task": "node1:12345" } // 查看任务状态 GET /_tasks/node1:12345 // 取消任务 POST /_tasks/node1:12345/_cancel ``` ## 数据迁移 ### Reindex API Reindex API 用于将数据从一个索引复制到另一个索引,常用于映射变更、索引重建等场景。 #### 基本重建索引 ```json // 将 products_v1 的数据复制到 products_v2 POST /_reindex { "source": { "index": "products_v1" }, "dest": { "index": "products_v2" } } ``` #### 带查询条件的重建 ```json // 只迁移特定条件的数据 POST /_reindex { "source": { "index": "products_v1", "query": { "term": { "is_available": true } } }, "dest": { "index": "products_v2" } } ``` #### 使用脚本转换数据 ```json // 迁移时转换数据 POST /_reindex { "source": { "index": "products_v1" }, "dest": { "index": "products_v2" }, "script": { "source": """ ctx._source.price_with_tax = ctx._source.price * 1.13; ctx._source.migrated_at = '2024-01-20'; """ } } ``` #### 跨集群重建 ```json // 从远程集群迁移数据 POST /_reindex { "source": { "remote": { "host": "http://remote-es:9200", "username": "user", "password": "pass" }, "index": "products" }, "dest": { "index": "products_local" } } ``` #### Reindex 性能优化 ```json // 优化 Reindex 性能 POST /_reindex?wait_for_completion=false&refresh=false { "source": { "index": "products_v1", "size": 5000 }, "dest": { "index": "products_v2" } } // 使用 slices 并行处理 POST /_reindex?slices=auto { "source": { "index": "products_v1" }, "dest": { "index": "products_v2" } } ``` ### 零停机索引重建流程 ``` 步骤 1: 创建新索引(新映射) ┌─────────────────────────────────────────┐ │ PUT /products_v2 │ │ { "mappings": { ... } } │ └─────────────────────────────────────────┘ │ ▼ 步骤 2: 重建索引数据 ┌─────────────────────────────────────────┐ │ POST /_reindex │ │ { "source": {"index": "products_v1"}, │ │ "dest": {"index": "products_v2"} } │ └─────────────────────────────────────────┘ │ ▼ 步骤 3: 切换别名(原子操作) ┌─────────────────────────────────────────┐ │ POST /_aliases │ │ { "actions": [ │ │ {"remove": {"index": "products_v1", │ │ "alias": "products"}}, │ │ {"add": {"index": "products_v2", │ │ "alias": "products"}} │ │ ]} │ └─────────────────────────────────────────┘ │ ▼ 步骤 4: 删除旧索引(可选) ┌─────────────────────────────────────────┐ │ DELETE /products_v1 │ └─────────────────────────────────────────┘ ``` ## 实践示例 ### 电商商品管理完整示例 ```json // 1. 创建商品索引 PUT /shop_products { "settings": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "1s" }, "mappings": { "properties": { "product_id": { "type": "keyword" }, "name": { "type": "text", "analyzer": "standard", "fields": { "keyword": { "type": "keyword" } } }, "description": { "type": "text" }, "category": { "type": "keyword" }, "brand": { "type": "keyword" }, "price": { "type": "double" }, "original_price": { "type": "double" }, "stock": { "type": "integer" }, "sales": { "type": "integer" }, "rating": { "type": "float" }, "tags": { "type": "keyword" }, "is_available": { "type": "boolean" }, "created_at": { "type": "date" }, "updated_at": { "type": "date" } } } } // 2. 批量导入商品 POST /shop_products/_bulk {"index":{"_id":"P001"}} {"product_id":"P001","name":"iPhone 15 Pro","description":"Apple 最新旗舰手机","category":"手机","brand":"Apple","price":8999,"original_price":9999,"stock":100,"sales":500,"rating":4.8,"tags":["5G","旗舰","热销"],"is_available":true,"created_at":"2024-01-01","updated_at":"2024-01-15"} {"index":{"_id":"P002"}} {"product_id":"P002","name":"华为 Mate 60 Pro","description":"华为旗舰手机,麒麟芯片","category":"手机","brand":"华为","price":6999,"original_price":7499,"stock":80,"sales":800,"rating":4.9,"tags":["5G","旗舰","国产"],"is_available":true,"created_at":"2024-01-02","updated_at":"2024-01-15"} {"index":{"_id":"P003"}} {"product_id":"P003","name":"MacBook Pro 14","description":"Apple M3 Pro 芯片笔记本","category":"笔记本","brand":"Apple","price":14999,"original_price":15999,"stock":50,"sales":200,"rating":4.7,"tags":["专业","M3","高性能"],"is_available":true,"created_at":"2024-01-03","updated_at":"2024-01-15"} // 3. 查询商品 GET /shop_products/_doc/P001 // 4. 更新库存(减少库存) POST /shop_products/_update/P001 { "script": { "source": """ if (ctx._source.stock >= params.quantity) { ctx._source.stock -= params.quantity; ctx._source.sales += params.quantity; ctx._source.updated_at = params.now; } else { ctx.op = 'noop'; } """, "params": { "quantity": 1, "now": "2024-01-20" } } } // 5. 批量更新价格(促销活动) POST /shop_products/_update_by_query { "query": { "term": { "brand": "Apple" } }, "script": { "source": """ ctx._source.original_price = ctx._source.price; ctx._source.price = ctx._source.price * 0.9; ctx._source.tags.add('促销'); ctx._source.updated_at = params.now; """, "params": { "now": "2024-01-20" } } } // 6. 下架缺货商品 POST /shop_products/_update_by_query { "query": { "range": { "stock": { "lte": 0 } } }, "script": { "source": "ctx._source.is_available = false" } } // 7. 删除过期商品 POST /shop_products/_delete_by_query { "query": { "bool": { "must": [ { "term": { "is_available": false } }, { "range": { "updated_at": { "lt": "2023-01-01" } } } ] } } } ``` ### curl 命令示例 ```bash # 创建索引 curl -X PUT "localhost:9200/products" -H 'Content-Type: application/json' -d' { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } }' # 创建文档 curl -X PUT "localhost:9200/products/_doc/1" -H 'Content-Type: application/json' -d' { "name": "iPhone 15", "price": 7999, "category": "手机" }' # 获取文档 curl -X GET "localhost:9200/products/_doc/1" # 更新文档 curl -X POST "localhost:9200/products/_update/1" -H 'Content-Type: application/json' -d' { "doc": { "price": 7499 } }' # 删除文档 curl -X DELETE "localhost:9200/products/_doc/1" # 批量操作 curl -X POST "localhost:9200/products/_bulk" -H 'Content-Type: application/x-ndjson' -d' {"index":{"_id":"1"}} {"name":"商品1","price":100} {"index":{"_id":"2"}} {"name":"商品2","price":200} ' ``` ## 本章小结 本章详细介绍了 Elasticsearch 的 CRUD 操作: 1. **索引操作**: - 创建索引时可指定设置和映射 - 动态设置可随时修改,静态设置需关闭索引后修改 - 使用别名实现零停机索引切换 2. **文档操作**: - PUT 指定 ID 创建,POST 自动生成 ID - `_create` 端点防止覆盖已存在文档 - `_mget` 批量获取多个文档 3. **批量操作**: - Bulk API 支持 index、create、update、delete 四种操作 - 建议批量大小 1000-5000 条或 5-15MB - 使用 `refresh=false` 提高批量写入性能 4. **更新操作**: - Update API 支持部分更新和脚本更新 - Update By Query 批量更新匹配条件的文档 - Upsert 实现更新或插入逻辑 5. **数据迁移**: - Reindex API 用于索引重建和数据迁移 - 支持查询过滤、脚本转换、跨集群迁移 - 配合别名实现零停机迁移 ## 参考资料 - [Index APIs](https://www.elastic.co/guide/en/elasticsearch/reference/current/indices.html) - [Document APIs](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html) - [Bulk API](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html) - [Update API](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-update.html) - [Update By Query API](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-update-by-query.html) - [Reindex API](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-reindex.html)

使用 Elasticsearch Dump 工具进行生产环境到测试环境的数据迁移与备份
`es-dump` 是 Elasticsearch 的一个实用工具,专门用于从 Elasticsearch 集群中导出或导入数据,支持数据、映射、别名、模板等多种类型的数据操作。它在数据迁移、备份、恢复等场景中非常实用。本文将展示如何使用 `es-dump` 工具执行生产到测试环境的索引复制,以及备份数据到本地文件或云存储服务中。 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch ### 1. 复制索引从生产到测试环境 在某些情况下,我们需要将生产环境中的 Elasticsearch 索引迁移到测试环境。可以通过以下步骤将生产环境中的分析器、映射和数据导出并导入到测试环境中。 #### 导出并导入分析器: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=http://staging.es.com:9200/my_index \ --type=analyzer ``` #### 导出并导入映射: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=http://staging.es.com:9200/my_index \ --type=mapping ``` #### 导出并导入数据: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=http://staging.es.com:9200/my_index \ --type=data ``` 通过上述命令,你可以完整地将生产环境的 `my_index` 复制到测试环境的 `my_index` 中,包含索引的分析器、映射和数据。 ### 2. 备份索引到文件 在进行索引备份时,可以将索引的映射和数据导出到本地文件中,以便稍后进行恢复。 #### 备份索引映射到 JSON 文件: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=/data/my_index_mapping.json \ --type=mapping ``` #### 备份索引数据到 JSON 文件: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=/data/my_index.json \ --type=data ``` ### 3. 使用 `gzip` 压缩备份 如果索引数据量较大,建议通过压缩方式来备份数据。以下命令将数据备份到 `gzip` 压缩文件中: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=$ \ | gzip > /data/my_index.json.gz ``` ### 4. 查询数据备份 在某些情况下,你可能只需要备份符合特定查询条件的数据。可以使用 `searchBody` 参数来指定查询条件: #### 备份查询结果到文件: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=query.json \ --searchBody='{"query":{"term":{"username": "admin"}}}' ``` ### 5. 拆分备份文件 对于大规模索引,可以将数据拆分成多个部分进行备份。使用 `fileSize` 参数来限制每个文件的大小: ```bash elasticdump \ --input=http://production.es.com:9200/my_index \ --output=/data/my_index.json \ --fileSize=10mb ``` ### 6. 云存储上的导入导出 有时你可能需要将数据导入或导出到云存储(如 S3 或 Minio)中。`elasticdump` 也支持这种操作。 #### 从 S3 导入数据到 Elasticsearch: ```bash elasticdump \ --s3AccessKeyId "${access_key_id}" \ --s3SecretAccessKey "${access_key_secret}" \ --input "s3://${bucket_name}/${file_name}.json" \ --output=http://production.es.com:9200/my_index ``` #### 将数据从 Elasticsearch 导出到 S3: ```bash elasticdump \ --s3AccessKeyId "${access_key_id}" \ --s3SecretAccessKey "${access_key_secret}" \ --input=http://production.es.com:9200/my_index \ --output "s3://${bucket_name}/${file_name}.json" ``` ### 7. 使用 CSV 数据导入 Elasticsearch 你也可以将 CSV 文件中的数据导入到 Elasticsearch 中。以下命令展示了如何处理 CSV 文件的导入: ```bash elasticdump \ --input "csv:///data/cars.csv" \ --output=http://production.es.com:9200/my_index \ --csvSkipRows 1 \ --csvDelimiter ";" ``` 这里的 `--csvSkipRows` 参数用于跳过 CSV 文件中的指定行,`--csvDelimiter` 用于定义 CSV 文件的列分隔符。 `elasticdump` 提供了强大的导入导出功能,帮助用户轻松地进行数据备份、恢复、索引迁移等操作。无论是将索引从生产环境迁移到测试环境,还是将数据备份到本地文件或云存储中,`elasticdump` 都能为你提供灵活的解决方案。 通过合理使用这些功能,你可以显著提高 Elasticsearch 集群的维护和管理效率,确保数据的安全性与可用性。 

几个 Elasticsearch 可视化工具推荐
Easysearch 作为国产化的 Elasticsearch(ES)替代方案,兼容 Elasticsearch 生态系统中的多种工具。本文将介绍几款适合 Easysearch 用户的可视化工具,帮助您更高效地管理和查询数据。 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch ### 1. Elasticsearch Head 插件 在ES培训经常提到的Elasticsearch Head 是一款基于浏览器的插件,适合不想部署 Kibana 等复杂工具的用户。它提供了简洁的界面,方便用户查看集群状态、索引分布、分片信息等。 #### 主要功能: - **索引分布查看**  - **索引详细信息**  - **分片信息查看**  - **DSL 查询**  ### 2. Elasticvue 插件 https://appstore.lazycat.cloud/#/shop/detail/cloud.lazycat.app.elasticvue Elasticvue 是一款高评分、高颜值的插件,功能全面,适合需要更丰富功能的用户。 #### 主要功能: - **节点信息查看**  - **索引查看**  - **DSL 查询**  - **快照存储库管理**  ### 3. Cerebro https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.cerebro Cerebro 是一款需要自行部署的工具,建议在懒猫商店安装。 #### 主要功能:  - **网络请求处理** Cerebro 有自己的后端服务,请求并非直接从浏览器发出。因此,启动 Docker 容器时,避免连接 `localhost`,以免进入容器内部。  查看索引信息:  可视化功能一览:  ### 4. 认证与安全 对于需要密码认证的连接,可以使用以下两种方式: 1. **直接连接**: `https://admin:xxxxx@localhost:9200/` 2. **Base64 编码凭证**: 可以使用 Postman 或其他工具生成 Base64 编码的凭证,并在请求头中传递。 ```python import requests url = "https://localhost:9200" payload = "" headers = { 'Authorization': 'Basic YWRtaW46NzllYTM4MzMwMmM2OGZiYWM0MDc=' } response = requests.request("GET", url, headers=headers, data=payload) print(response.text) ``` ### 总结 以上工具各有特色,用户可以根据自己的需求选择合适的工具。无论是简单的浏览器插件,还是功能更强大的 Cerebro,都能帮助您更好地管理和查询 ES 集群。

Elasticsearch vs Meilisearch:两种搜索引擎的不同哲学
https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.meilisearch 在现代信息系统中,**“搜索”已经不只是查找文本,而是体验的一部分**。从日志分析到商品推荐,从开发者工具到企业知识库,搜索系统的性能、可扩展性与易用性,往往直接决定了产品的质量。 目前最主流的两种搜索引擎是 **Elasticsearch** 和 **Meilisearch**。它们都能实现全文检索,但走的路完全不同。本文将从技术架构、使用场景、性能表现等多个维度,系统地对比这两款搜索引擎。 --- ## 一、设计哲学的分野 Elasticsearch(简称 ES)诞生于 2010 年,是 **“大数据 + 分布式 + 企业级搜索”** 的代表。 Meilisearch 则诞生于 2018 年,是 **“轻量化 + 开箱即用 + 开发者友好”** 的新派搜索引擎。 一句话概括: > **ES 面向企业级系统的复杂需求,Meilisearch 面向开发者的快速体验。** ES 基于 Lucene 构建,继承了强大的倒排索引、聚合分析和集群管理能力; Meilisearch 则用 Rust 重写了一套搜索引擎内核,追求低内存占用与极致响应速度。 --- ## 二、架构差异:庞然大物 vs 轻骑兵 | 项目 | Elasticsearch | Meilisearch | | ----- | -------------------- | --------------- | | 核心语言 | Java + Lucene | Rust | | 部署复杂度 | 高(JVM 调优、节点协调、分片、副本) | 极低(单可执行文件运行) | | 扩展性 | 支持多节点分布式集群 | 轻量单机为主(分布式仍在完善) | | 存储引擎 | 基于 Lucene 的倒排文件系统 | 自研内存 + SSD 结构 | | 运维成本 | 高(需要监控、内存管理) | 极低(几乎零维护) | 对于企业平台来说,ES 像一艘航空母舰:能干很多事,但操作复杂; 而 Meilisearch 像一辆越野摩托:启动快,维护轻,适合单点高效场景。 --- ## 三、索引与数据建模 在数据建模层面,两者的差异更明显。 * **Elasticsearch** * 索引结构:`Index → Shard → Document` * 字段类型丰富(text、keyword、geo、date、nested 等) * 支持复杂 mapping 与自定义分词器 * 具备自动 schema 推断,但建议显式定义 * 适合多维数据建模与复杂过滤 * **Meilisearch** * 结构更简单:`Index → Document` * 自动推断字段类型,几乎零配置 * 分词内置、语义相关度自动调优 * 不支持嵌套字段或复杂 mapping * 面向“即插即用”的开发体验 一句话总结: > Elasticsearch 适合“建模丰富的数据体系”,Meilisearch 适合“快速上线的搜索功能”。 --- ## 四、查询语言与开发体验 Elasticsearch 使用 DSL(Domain Specific Language)语法,功能强大但学习曲线陡峭。 例如一次查询就可能包含 match、filter、must、should、bool、aggs、script 等结构。 Meilisearch 的 API 则简洁得多: ```bash GET /movies/search?q=inception ``` 返回自动排序、高亮、模糊匹配结果。没有 DSL,也不需要学习额外语法。 对于前端或全栈开发者而言,Meilisearch 的 API 十分亲切; 但对于需要复杂检索逻辑的后端系统,Elasticsearch 的 DSL 才是真正的利器。 --- ## 五、性能对比:规模与延迟的平衡 | 指标 | Elasticsearch | Meilisearch | | ---- | --------------------- | -------------- | | 数据规模 | 支持 TB 级以上 | 建议 < 100GB | | 写入速度 | 高(批量写入、异步 flush) | 中(单线程优化) | | 查询延迟 | 毫秒级 | 亚毫秒级 | | 内存占用 | 高(JVM + Lucene Cache) | 低(Rust + 内存高效) | | 可扩展性 | 高度可扩展 | 轻量化为主 | 结论: > 如果你要在生产环境里分析日志、跑聚合、搞监控,就用 ES; > 如果你只是想做一个 App 内搜索、博客搜索、商品推荐,就用 Meilisearch。 --- ## 六、功能特性比较 | 功能 | Elasticsearch | Meilisearch | | ---- | --------------------------------- | --------------- | | 聚合分析 | ✅ 支持复杂聚合(sum、avg、terms、histogram) | ❌ 不支持复杂聚合 | | 模糊搜索 | ✅ 支持 edit distance | ✅ 内置模糊匹配与拼写纠错 | | 向量搜索 | ✅ 支持 KNN、dense_vector | ⚙️ 实验性支持 | | 安全认证 | ✅ 支持 TLS、RBAC、API Key | ⚙️ 简单 API Key | | 插件生态 | ✅ 丰富(ML、Alert、Ingest) | ❌ 较少 | | 管理工具 | ✅ Kibana | ✅ Web Dashboard | --- ## 七、应用场景建议 | 场景 | 推荐引擎 | | -------------- | ------------- | | 日志监控与安全审计 | Elasticsearch | | 电商商品搜索 | Meilisearch | | 内容推荐 / App 内搜索 | Meilisearch | | 知识库 / 企业搜索 | Elasticsearch | | 数据分析与 BI 可视化 | Elasticsearch | | SaaS 工具搜索 | Meilisearch | --- ## 八、谁更适合你? | 用户类型 | 建议 | | ---------------------- | ------------------------------- | | 企业平台 / 安全审计 / 大数据团队 | **Elasticsearch** | | 创业团队 / 博客 / SaaS 产品开发者 | **Meilisearch** | | 有 AI 检索、向量需求 | **Elasticsearch(或 EasySearch)** | | 想快速上线搜索功能,不想管集群 | **Meilisearch** | --- ## 九、总结:不同路线的成功 Elasticsearch 和 Meilisearch 并非竞争关系,而是 **两种不同哲学的成功体现**: * ES 用复杂性换来了灵活性和规模; * Meilisearch 用简单性换来了极致体验和开发效率。 如果用一句话总结: > Elasticsearch 是“企业级分布式搜索分析引擎”; > Meilisearch 是“轻量化即时搜索引擎”。 在选型时,不妨问自己一句话: > “我需要的是一个**可扩展的分析系统**,还是一个**快速的搜索体验**?” 
Elasticsearch 第1章:简介
> 本章导读:本章将介绍 Elasticsearch 的发展历史、核心特性、与其他搜索引擎的对比,以及典型的应用场景,帮助读者建立对 Elasticsearch 的整体认识。 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch  ## 目录 - [什么是 Elasticsearch](#什么是-elasticsearch) - [发展历史与版本演进](#发展历史与版本演进) - [核心特性](#核心特性) - [与其他搜索引擎对比](#与其他搜索引擎对比) - [典型应用场景](#典型应用场景) - [本章小结](#本章小结) - [练习题](#练习题) - [参考资料](#参考资料) ## 什么是 Elasticsearch Elasticsearch 是一个基于 Apache Lucene 构建的开源、分布式、RESTful 风格的搜索和数据分析引擎。它能够快速地存储、搜索和分析海量数据,通常在毫秒级别内返回搜索结果。 ### 核心定位 - **搜索引擎**:提供全文搜索、结构化搜索、地理位置搜索等多种搜索能力 - **分析引擎**:支持复杂的聚合分析,可用于日志分析、业务指标分析等场景 - **数据存储**:作为 NoSQL 数据库使用,支持 JSON 文档的存储和检索 ### 为什么选择 Elasticsearch 1. **近实时搜索**:文档索引后约 1 秒即可被搜索到 2. **分布式架构**:天然支持水平扩展,可处理 PB 级数据 3. **高可用性**:通过副本机制保证数据安全和服务可用 4. **RESTful API**:简单易用的 HTTP 接口,支持多种编程语言 5. **丰富的生态**:与 Kibana、Logstash、Beats 等组成完整的 Elastic Stack ## 发展历史与版本演进 ### 起源与发展 | 时间 | 里程碑 | |------|--------| | 2010年2月 | Shay Banon 发布 Elasticsearch 0.4 版本 | | 2012年 | Elastic 公司成立 | | 2014年 | 发布 1.0 版本,标志着产品成熟 | | 2015年 | 发布 2.0 版本,引入 Pipeline Aggregations | | 2016年 | 发布 5.0 版本(跳过 3.x/4.x 与 ELK 版本统一) | | 2017年 | 发布 6.0 版本,移除 mapping types | | 2019年 | 发布 7.0 版本,默认单 type,引入新集群协调层 | | 2021年 | 发布 8.0 版本,默认启用安全特性 | | 2023年 | 8.x 持续迭代,增强向量搜索和 AI 能力 | ### 主要版本特性 #### Elasticsearch 7.x 主要特性 - 移除 mapping types,每个索引只有一个 type(`_doc`) - 新的集群协调层,提升大规模集群稳定性 - 引入 High Level REST Client 作为推荐客户端 - 默认分片数从 5 改为 1 - 引入 ILM(索引生命周期管理) #### Elasticsearch 8.x 主要特性 - 默认启用安全特性(TLS、认证) - 原生向量搜索(kNN)支持 - 新的 Java API Client 替代 High Level REST Client - 改进的 Lucene 9 支持 - 增强的机器学习和 NLP 能力 ### 版本选择建议 | 场景 | 推荐版本 | |------|----------| | 新项目 | 8.x 最新稳定版 | | 已有 7.x 项目 | 评估升级到 8.x | | 对安全要求高 | 8.x(默认安全) | | 需要向量搜索 | 8.x | ## 核心特性 ### 1. 分布式架构 ``` ┌─────────────────────────────────────────────────────────┐ │ Elasticsearch 集群 │ ├─────────────────┬─────────────────┬─────────────────────┤ │ Node 1 │ Node 2 │ Node 3 │ │ ┌───────────┐ │ ┌───────────┐ │ ┌───────────┐ │ │ │ Shard P0 │ │ │ Shard P1 │ │ │ Shard P2 │ │ │ │ Shard R1 │ │ │ Shard R2 │ │ │ Shard R0 │ │ │ └───────────┘ │ └───────────┘ │ └───────────┘ │ └─────────────────┴─────────────────┴─────────────────────┘ P = Primary Shard(主分片) R = Replica Shard(副本分片) ``` - **自动分片**:数据自动分布到多个节点 - **自动路由**:请求自动路由到正确的分片 - **自动恢复**:节点故障时自动重新分配分片 ### 2. 全文搜索 基于 Lucene 的强大全文搜索能力: ```json // 示例:全文搜索 GET /products/_search { "query": { "match": { "description": "高性能 搜索引擎" } } } ``` ### 3. 实时分析 强大的聚合分析能力: ```json // 示例:按类别统计商品数量 GET /products/_search { "size": 0, "aggs": { "category_count": { "terms": { "field": "category.keyword" } } } } ``` ### 4. 高可用与容错 - **副本机制**:每个主分片可配置多个副本 - **自动故障转移**:主分片不可用时,副本自动提升 - **跨集群复制**:支持多数据中心部署 ### 5. Schema Free - 支持动态映射,无需预定义 schema - 也支持显式映射,精确控制字段类型 ## 与其他搜索引擎对比 ### Elasticsearch vs Solr | 特性 | Elasticsearch | Solr | |------|---------------|------| | 基础 | Lucene | Lucene | | 分布式 | 原生支持 | 需要 SolrCloud | | 配置 | JSON/YAML | XML | | API | RESTful | RESTful + SolrJ | | 实时搜索 | 近实时(~1秒) | 近实时 | | 学习曲线 | 较平缓 | 较陡峭 | | 社区活跃度 | 非常活跃 | 活跃 | | 适用场景 | 日志分析、全文搜索 | 传统企业搜索 | ### Elasticsearch vs 关系型数据库 | 特性 | Elasticsearch | MySQL/PostgreSQL | |------|---------------|------------------| | 数据模型 | 文档(JSON) | 表(行列) | | 查询语言 | Query DSL | SQL | | 全文搜索 | 原生支持,功能强大 | 有限支持 | | 聚合分析 | 非常强大 | 支持,但复杂查询较慢 | | 事务支持 | 不支持 ACID | 完整支持 | | 关联查询 | 有限支持 | 强大的 JOIN | | 扩展性 | 水平扩展容易 | 垂直扩展为主 | ### Elasticsearch vs MongoDB | 特性 | Elasticsearch | MongoDB | |------|---------------|---------| | 定位 | 搜索和分析引擎 | 通用文档数据库 | | 全文搜索 | 核心功能,非常强大 | 支持,但功能有限 | | 聚合 | 非常强大 | 强大 | | 事务 | 不支持 | 支持(4.0+) | | 实时性 | 近实时(~1秒) | 实时 | | 适用场景 | 搜索、日志、分析 | 通用数据存储 | ### 选型建议 ``` ┌─────────────────────────────────────────────────────────┐ │ 选型决策树 │ ├─────────────────────────────────────────────────────────┤ │ │ │ 需要全文搜索? ──Yes──> Elasticsearch │ │ │ │ │ No │ │ │ │ │ 需要复杂聚合分析? ──Yes──> Elasticsearch │ │ │ │ │ No │ │ │ │ │ 需要 ACID 事务? ──Yes──> 关系型数据库 │ │ │ │ │ No │ │ │ │ │ 需要灵活 Schema? ──Yes──> MongoDB │ │ │ └─────────────────────────────────────────────────────────┘ ``` ## 典型应用场景 ### 1. 日志分析(ELK Stack) 最经典的应用场景,使用 Elasticsearch + Logstash + Kibana 构建日志分析平台: ``` ┌─────────┐ ┌──────────┐ ┌───────────────┐ ┌────────┐ │ 应用 │───>│ Filebeat │───>│ Logstash │───>│ ES │ │ 日志 │ │ │ │ (解析/转换) │ │ │ └─────────┘ └──────────┘ └───────────────┘ └────┬───┘ │ ┌────▼───┐ │ Kibana │ │ (可视化)│ └────────┘ ``` **应用价值**: - 集中管理分布式系统日志 - 快速定位问题和异常 - 实时监控系统状态 - 支持复杂的日志查询和分析 ### 2. 全文搜索 为网站或应用提供搜索功能: ```json // 电商商品搜索示例 GET /products/_search { "query": { "bool": { "must": [ { "match": { "name": "iPhone" } } ], "filter": [ { "term": { "category": "手机" } }, { "range": { "price": { "gte": 5000, "lte": 10000 } } } ] } }, "highlight": { "fields": { "name": {} } } } ``` **应用场景**: - 电商商品搜索 - 内容管理系统 - 知识库搜索 - 站内搜索 ### 3. 业务数据分析 利用聚合功能进行业务指标分析: ```json // 按天统计销售额 GET /orders/_search { "size": 0, "aggs": { "daily_sales": { "date_histogram": { "field": "order_date", "calendar_interval": "day" }, "aggs": { "total_amount": { "sum": { "field": "amount" } } } } } } ``` **应用场景**: - 销售数据分析 - 用户行为分析 - 实时大屏展示 - BI 报表 ### 4. 安全分析(SIEM) 使用 Elastic Security 进行安全事件分析: **应用场景**: - 安全日志分析 - 威胁检测 - 合规审计 - 入侵检测 ### 5. APM(应用性能监控) 使用 Elastic APM 监控应用性能: **应用场景**: - 分布式链路追踪 - 性能瓶颈分析 - 错误监控 - 服务依赖分析 ### 6. 地理位置服务 利用地理位置查询能力: ```json // 查找附近 5km 内的门店 GET /stores/_search { "query": { "geo_distance": { "distance": "5km", "location": { "lat": 39.9042, "lon": 116.4074 } } } } ``` **应用场景**: - 附近门店搜索 - 外卖配送范围 - 打车服务 - 地理围栏 ## 本章小结 本章介绍了 Elasticsearch 的基础知识: 1. **定位**:Elasticsearch 是一个分布式搜索和分析引擎,基于 Lucene 构建 2. **历史**:从 2010 年发布至今,已发展到 8.x 版本,功能不断完善 3. **特性**:分布式架构、全文搜索、实时分析、高可用是其核心特性 4. **对比**:相比 Solr 更易用,相比数据库搜索能力更强,与 MongoDB 定位不同 5. **场景**:日志分析、全文搜索、数据分析、安全分析、APM、地理位置服务 ## 参考资料 - [Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html) - [Elasticsearch: The Definitive Guide](https://www.elastic.co/guide/en/elasticsearch/guide/current/index.html) - [Elastic 官方博客](https://www.elastic.co/blog/) - [Elasticsearch GitHub 仓库](https://github.com/elastic/elasticsearch)
Elasticsearch第3章:架构原理
# https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch > 本章导读:本章将深入介绍 Elasticsearch 的架构设计,包括集群架构、节点类型、数据存储原理等,帮助读者理解 ES 的内部工作机制。 ## 目录 - [前置知识](#前置知识) - [集群架构概览](#集群架构概览) - [节点类型详解](#节点类型详解) - [数据存储原理](#数据存储原理) - [分布式架构](#分布式架构) - [本章小结](#本章小结) - [参考资料](#参考资料) ## 集群架构概览 ### 整体架构图 ``` ┌─────────────────────────────────────────────────────────────────────────────┐ │ 客户端请求 │ │ (REST API / Transport Protocol) │ └─────────────────────────────────────────────────────────────────────────────┘ │ ▼ ┌─────────────────────────────────────────────────────────────────────────────┐ │ Elasticsearch 集群 │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ 协调层 (Coordinating) │ │ │ │ 接收请求 → 路由到分片 → 聚合结果 → 返回响应 │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ │ │ │ │ ┌──────────────────────────┼──────────────────────────┐ │ │ ▼ ▼ ▼ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ Master │ │ Data │ │ Ingest │ │ │ │ Node │ │ Node │ │ Node │ │ │ │ │ │ │ │ │ │ │ │ • 集群状态 │ │ • 数据存储 │ │ • 数据预处理│ │ │ │ • 索引管理 │ │ • 搜索执行 │ │ • Pipeline │ │ │ │ • 分片分配 │ │ • 聚合计算 │ │ │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ │ │ ▼ │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ 存储层 (Lucene) │ │ │ │ 倒排索引 / Doc Values / 段文件 │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────────────────────────┘ ``` ### 架构组件说明 | 组件 | 职责 | |------|------| | 协调层 | 接收客户端请求,路由到正确的分片,聚合各分片结果 | | Master 节点 | 管理集群元数据,处理索引创建/删除,分片分配决策 | | Data 节点 | 存储数据,执行数据相关操作(CRUD、搜索、聚合) | | Ingest 节点 | 执行 Ingest Pipeline,在索引前预处理文档 | | 存储层 | 基于 Lucene 的底层存储,管理倒排索引和段文件 | ## 节点类型详解 ### Master 节点 Master 节点负责集群级别的管理操作: **职责**: - 维护集群状态(Cluster State) - 创建和删除索引 - 分片分配和重平衡决策 - 节点加入和离开处理 **配置**: ```yaml # elasticsearch.yml node.roles: [master] ``` **最佳实践**: - 生产环境至少 3 个 Master-eligible 节点 - 专用 Master 节点不存储数据,资源需求较低 - 配置 `cluster.initial_master_nodes` 防止脑裂 ```yaml # 专用 Master 节点配置 node.roles: [master] cluster.initial_master_nodes: ["master-1", "master-2", "master-3"] ``` ### Data 节点 Data 节点负责数据存储和处理: **职责**: - 存储分片数据 - 执行 CRUD 操作 - 执行搜索和聚合 **配置**: ```yaml # elasticsearch.yml node.roles: [data] ``` **数据节点分层**(8.x 新特性): | 角色 | 说明 | 适用数据 | |------|------|----------| | `data_hot` | 热数据节点 | 最新、频繁访问的数据 | | `data_warm` | 温数据节点 | 较少访问的历史数据 | | `data_cold` | 冷数据节点 | 很少访问的归档数据 | | `data_frozen` | 冻结数据节点 | 极少访问,可搜索快照 | | `data_content` | 内容数据节点 | 非时序数据 | ```yaml # 热数据节点配置 node.roles: [data_hot] # 温数据节点配置 node.roles: [data_warm] ``` ### Coordinating 节点 协调节点(也称为客户端节点)专门处理请求路由: **职责**: - 接收客户端请求 - 将请求路由到相关分片 - 聚合各分片返回的结果 - 返回最终结果给客户端 **配置**: ```yaml # 专用协调节点(不设置任何角色) node.roles: [] ``` **工作流程**: ``` 客户端请求 │ ▼ ┌─────────────────┐ │ Coordinating │ │ Node │ └────────┬────────┘ │ 路由请求 ┌────┴────┬────────┐ ▼ ▼ ▼ ┌───────┐ ┌───────┐ ┌───────┐ │Shard 0│ │Shard 1│ │Shard 2│ └───┬───┘ └───┬───┘ └───┬───┘ │ │ │ └────┬────┴────────┘ │ 聚合结果 ▼ ┌─────────────────┐ │ Coordinating │ │ Node │ └────────┬────────┘ │ ▼ 客户端响应 ``` ### Ingest 节点 Ingest 节点在文档索引前执行预处理: **职责**: - 执行 Ingest Pipeline - 数据转换和丰富 - 字段提取和格式化 **配置**: ```yaml # elasticsearch.yml node.roles: [ingest] ``` **Pipeline 示例**: ```json PUT _ingest/pipeline/my-pipeline { "description": "处理日志数据", "processors": [ { "grok": { "field": "message", "patterns": ["%{IP:client_ip} - %{DATA:user} \\[%{HTTPDATE:timestamp}\\]"] } }, { "date": { "field": "timestamp", "formats": ["dd/MMM/yyyy:HH:mm:ss Z"] } }, { "geoip": { "field": "client_ip" } } ] } ``` ### ML 节点 机器学习节点执行 ML 任务: **职责**: - 异常检测作业 - 预测分析 - 数据帧分析 **配置**: ```yaml # elasticsearch.yml node.roles: [ml] xpack.ml.enabled: true ``` ### 节点角色组合建议 **小型集群(开发/测试)**: ```yaml # 所有节点都是全角色 node.roles: [master, data, ingest] ``` **中型集群**: ``` ┌─────────────────────────────────────────────────────────┐ │ 3 x Master/Data 节点 │ │ node.roles: [master, data, ingest] │ └─────────────────────────────────────────────────────────┘ ``` **大型集群**: ``` ┌─────────────────────────────────────────────────────────┐ │ 3 x 专用 Master 节点 │ │ node.roles: [master] │ ├─────────────────────────────────────────────────────────┤ │ N x 专用 Data 节点 │ │ node.roles: [data_hot] / [data_warm] / [data_cold] │ ├─────────────────────────────────────────────────────────┤ │ 2+ x 协调节点 │ │ node.roles: [] │ ├─────────────────────────────────────────────────────────┤ │ 2+ x Ingest 节点 │ │ node.roles: [ingest] │ └─────────────────────────────────────────────────────────┘ ``` ## 数据存储原理 ### Lucene 基础 Elasticsearch 底层使用 Apache Lucene 作为搜索引擎库。每个分片本质上是一个 Lucene 索引。 ``` ┌─────────────────────────────────────────────────────────┐ │ Elasticsearch 分片 │ │ ┌─────────────────────────────────────────────────┐ │ │ │ Lucene Index │ │ │ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │ │ │ │Segment 0│ │Segment 1│ │Segment 2│ ... │ │ │ │ └─────────┘ └─────────┘ └─────────┘ │ │ │ └─────────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────┘ ``` ### 倒排索引(Inverted Index) 倒排索引是全文搜索的核心数据结构: **正向索引 vs 倒排索引**: ``` 正向索引(文档 → 词项): ┌─────────┬────────────────────────────┐ │ Doc ID │ Content │ ├─────────┼────────────────────────────┤ │ 1 │ "Elasticsearch is fast" │ │ 2 │ "Elasticsearch is scalable"│ │ 3 │ "Lucene is fast" │ └─────────┴────────────────────────────┘ 倒排索引(词项 → 文档): ┌───────────────┬─────────────────────────┐ │ Term │ Posting List │ ├───────────────┼─────────────────────────┤ │ elasticsearch │ [1, 2] │ │ fast │ [1, 3] │ │ is │ [1, 2, 3] │ │ lucene │ [3] │ │ scalable │ [2] │ └───────────────┴─────────────────────────┘ ``` **倒排索引结构**: ``` ┌─────────────────────────────────────────────────────────┐ │ 倒排索引 │ ├─────────────────────────────────────────────────────────┤ │ Term Dictionary (词项字典) │ │ ┌─────────────────────────────────────────────────┐ │ │ │ elasticsearch → offset: 0 │ │ │ │ fast → offset: 100 │ │ │ │ scalable → offset: 200 │ │ │ └─────────────────────────────────────────────────┘ │ │ │ │ │ ▼ │ │ Posting List (倒排列表) │ │ ┌─────────────────────────────────────────────────┐ │ │ │ Doc IDs: [1, 2] │ │ │ │ Term Frequency: [1, 1] │ │ │ │ Positions: [[0], [0]] │ │ │ │ Offsets: [[0-13], [0-13]] │ │ │ └─────────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────┘ ``` ### Doc Values Doc Values 是列式存储,用于排序、聚合和脚本访问: ``` 倒排索引(搜索用): Doc Values(聚合/排序用): Term → Doc IDs Doc ID → Field Value "apple" → [1, 3] 1 → "apple" "banana" → [2] 2 → "banana" "cherry" → [4] 3 → "apple" 4 → "cherry" ``` **Doc Values vs Fielddata**: | 特性 | Doc Values | Fielddata | |------|------------|-----------| | 存储位置 | 磁盘 | 内存 | | 构建时机 | 索引时 | 查询时 | | 适用类型 | keyword, numeric, date, ip, geo | text | | 内存占用 | 低 | 高 | | 默认状态 | 启用 | 禁用 | ```json // 禁用 Doc Values(节省磁盘,但无法排序/聚合) PUT /my-index { "mappings": { "properties": { "description": { "type": "keyword", "doc_values": false } } } } ``` ### 段(Segment) 段是 Lucene 索引的基本单位,是不可变的: **段的生命周期**: ``` 1. 文档写入内存缓冲区 ┌─────────────────┐ │ Memory Buffer │ ← 新文档 └─────────────────┘ 2. Refresh:内存缓冲区 → 新段(可搜索) ┌─────────────────┐ │ Segment 0 │ ← 可搜索 └─────────────────┘ 3. 更多文档写入,创建更多段 ┌─────────┐ ┌─────────┐ ┌─────────┐ │Segment 0│ │Segment 1│ │Segment 2│ └─────────┘ └─────────┘ └─────────┘ 4. Merge:多个小段合并为大段 ┌─────────────────────────────────┐ │ Merged Segment │ └─────────────────────────────────┘ ``` **段合并(Merge)**: ```json // 强制合并(谨慎使用,资源消耗大) POST /my-index/_forcemerge?max_num_segments=1 ``` ### _source 字段 `_source` 存储文档的原始 JSON: ```json // 禁用 _source(节省存储,但无法更新/reindex) PUT /my-index { "mappings": { "_source": { "enabled": false } } } // 部分存储 PUT /my-index { "mappings": { "_source": { "includes": ["title", "date"], "excludes": ["content"] } } } ``` ### 存储结构总结 ``` ┌─────────────────────────────────────────────────────────────────┐ │ Lucene Segment │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ │ │ Inverted Index │ │ Doc Values │ │ _source │ │ │ │ │ │ │ │ │ │ │ │ • Term Dict │ │ • 列式存储 │ │ • 原始 JSON │ │ │ │ • Posting List │ │ • 排序/聚合用 │ │ • 更新/高亮用 │ │ │ │ • 全文搜索用 │ │ │ │ │ │ │ └─────────────────┘ └─────────────────┘ └─────────────────┘ │ │ │ │ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ │ │ Stored Fields │ │ Term Vectors │ │ Norms │ │ │ │ │ │ │ │ │ │ │ │ • 存储的字段值 │ │ • 词项位置信息 │ │ • 字段长度归一化│ │ │ │ │ │ • 高亮/MLT 用 │ │ • 评分用 │ │ │ └─────────────────┘ └─────────────────┘ └─────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────┘ ``` ## 分布式架构 ### 文档路由 文档通过路由算法分配到特定分片: ``` shard_num = hash(routing) % number_of_primary_shards ``` 默认 `routing` 值为文档 `_id`。 ```json // 自定义路由 PUT /products/_doc/1?routing=user123 { "name": "Product A", "user_id": "user123" } // 查询时指定路由(提高效率) GET /products/_search?routing=user123 { "query": { "match": { "user_id": "user123" } } } ``` ### 写入流程 ``` 1. 客户端发送写入请求到协调节点 2. 协调节点根据路由计算目标主分片 3. 请求转发到主分片所在节点 4. 主分片执行写入 5. 主分片并行复制到所有副本分片 6. 所有副本确认后,返回成功响应 ┌────────┐ ┌─────────────┐ ┌─────────────┐ │ Client │────>│ Coordinating│────>│ Primary │ └────────┘ │ Node │ │ Shard │ └─────────────┘ └──────┬──────┘ │ ┌───────────┼───────────┐ ▼ ▼ ▼ ┌────────┐ ┌────────┐ ┌────────┐ │Replica │ │Replica │ │Replica │ │ 1 │ │ 2 │ │ 3 │ └────────┘ └────────┘ └────────┘ ``` ### 搜索流程 搜索分为两个阶段:Query Phase 和 Fetch Phase。 **Query Phase**: ``` 1. 协调节点将请求发送到所有相关分片 2. 每个分片执行本地搜索,返回匹配文档的 ID 和排序值 3. 协调节点合并结果,确定最终的 Top N 文档 ┌────────┐ ┌─────────────┐ │ Client │────>│ Coordinating│ └────────┘ │ Node │ └──────┬──────┘ │ Query ┌────────────┼────────────┐ ▼ ▼ ▼ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ Shard 0 │ │ Shard 1 │ │ Shard 2 │ └────┬────┘ └────┬────┘ └────┬────┘ │ │ │ └────────────┼────────────┘ │ Doc IDs + Scores ▼ ┌─────────────┐ │ Coordinating│ │ Node │ └─────────────┘ ``` **Fetch Phase**: ``` 1. 协调节点向包含目标文档的分片发送 Fetch 请求 2. 分片返回完整文档内容 3. 协调节点组装最终结果返回客户端 ┌─────────────┐ │ Coordinating│ │ Node │ └──────┬──────┘ │ Fetch (Doc IDs) ┌────────────┼────────────┐ ▼ ▼ ▼ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ Shard 0 │ │ Shard 1 │ │ Shard 2 │ └────┬────┘ └────┬────┘ └────┬────┘ │ │ │ └────────────┼────────────┘ │ Full Documents ▼ ┌─────────────┐ │ Coordinating│──────> Client │ Node │ └─────────────┘ ``` ### 集群状态管理 集群状态(Cluster State)包含: - 节点信息 - 索引元数据 - 分片分配信息 - 映射定义 - 集群设置 ```json // 查看集群状态 GET /_cluster/state // 查看集群状态大小 GET /_cluster/state?filter_path=metadata.indices.*.state ``` ### 主节点选举 Elasticsearch 使用基于 Raft 的选举算法(7.0+): ``` ┌─────────────────────────────────────────────────────────┐ │ 主节点选举流程 │ ├─────────────────────────────────────────────────────────┤ │ │ │ 1. 节点启动,进入候选状态 │ │ 2. 候选节点向其他节点请求投票 │ │ 3. 获得多数票的节点成为主节点 │ │ 4. 主节点定期发送心跳 │ │ 5. 主节点失联,重新选举 │ │ │ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │ │ Node 1 │ │ Node 2 │ │ Node 3 │ │ │ │(Master) │◄───│ │ │ │ │ │ └─────────┘ └─────────┘ └─────────┘ │ │ │ ▲ ▲ │ │ │ 心跳 │ │ │ │ └──────────────┴──────────────┘ │ │ │ └─────────────────────────────────────────────────────────┘ ``` **防止脑裂**: ```yaml # 配置初始主节点(仅首次启动时需要) cluster.initial_master_nodes: ["node-1", "node-2", "node-3"] ``` ## 本章小结 本章深入介绍了 Elasticsearch 的架构原理: 1. **集群架构**:由协调层、Master 节点、Data 节点、Ingest 节点等组成 2. **节点类型**: - Master:管理集群状态和元数据 - Data:存储数据,执行搜索和聚合 - Coordinating:路由请求,聚合结果 - Ingest:数据预处理 - ML:机器学习任务 3. **数据存储**: - 倒排索引:全文搜索的核心 - Doc Values:排序和聚合的列式存储 - 段:不可变的 Lucene 索引单元 4. **分布式机制**: - 文档路由:hash(routing) % shards - 写入流程:主分片写入 → 副本复制 - 搜索流程:Query Phase → Fetch Phase 理解这些架构原理有助于更好地设计和优化 Elasticsearch 应用。 ## 参考资料 - [Elasticsearch 集群架构](https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cluster.html) - [节点角色](https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html) - [Lucene 倒排索引](https://lucene.apache.org/core/) - [分布式搜索执行](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-shard-routing.html) 
Elasticsearch 快速上手:让搜索变得简单有趣
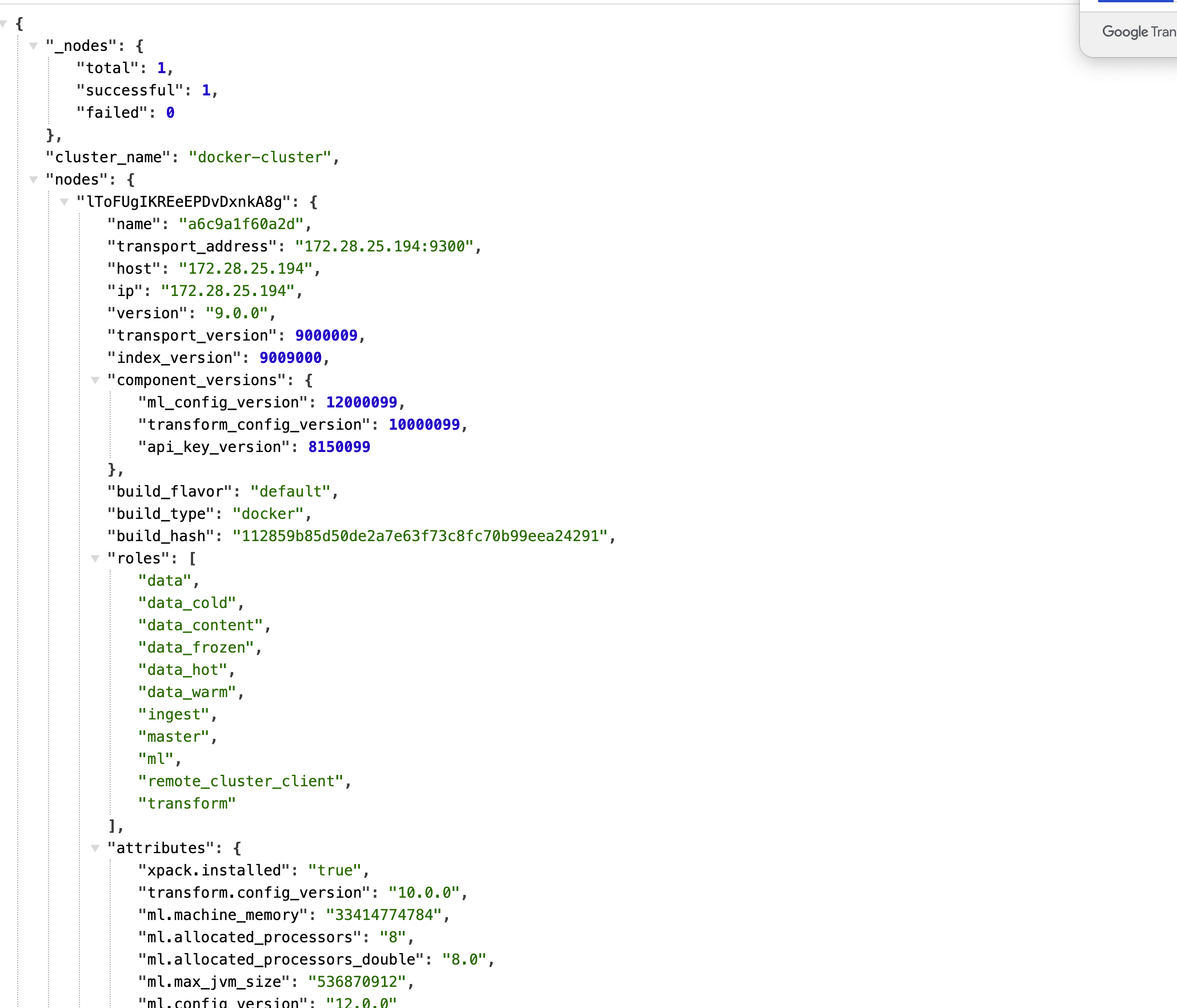
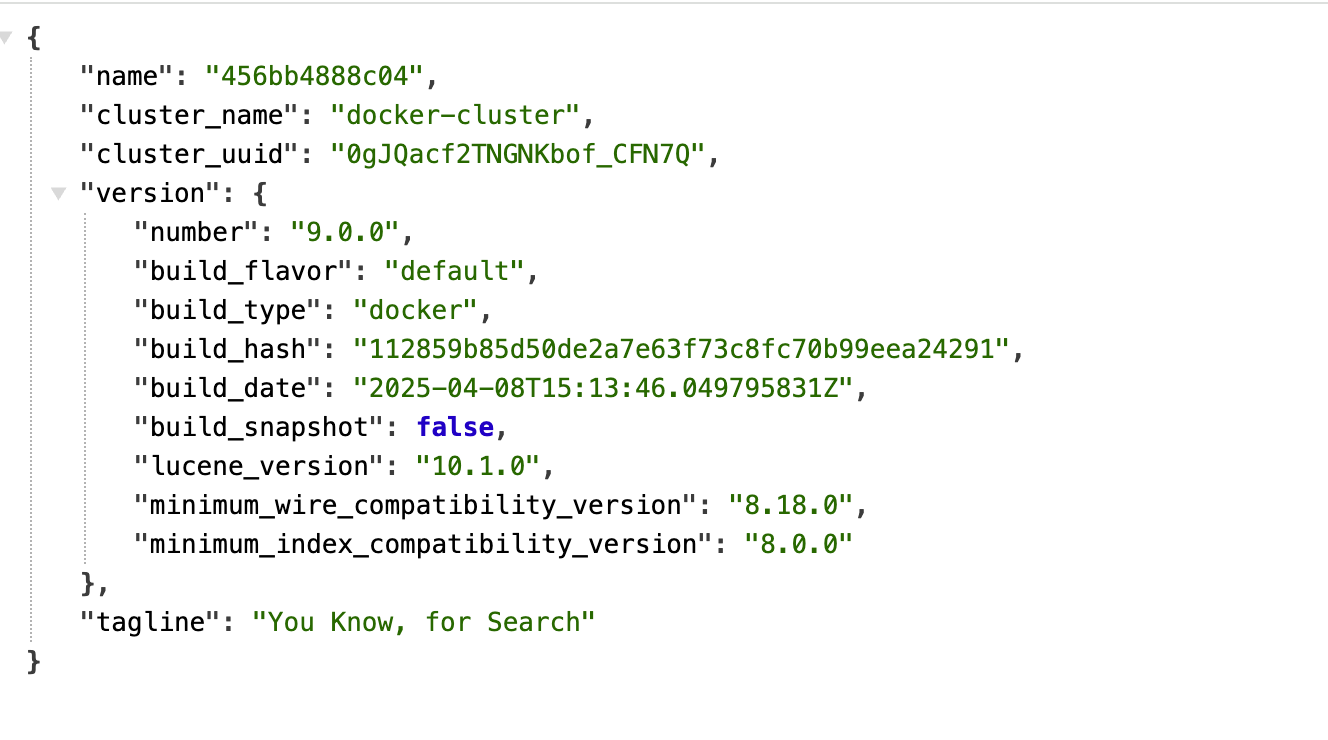
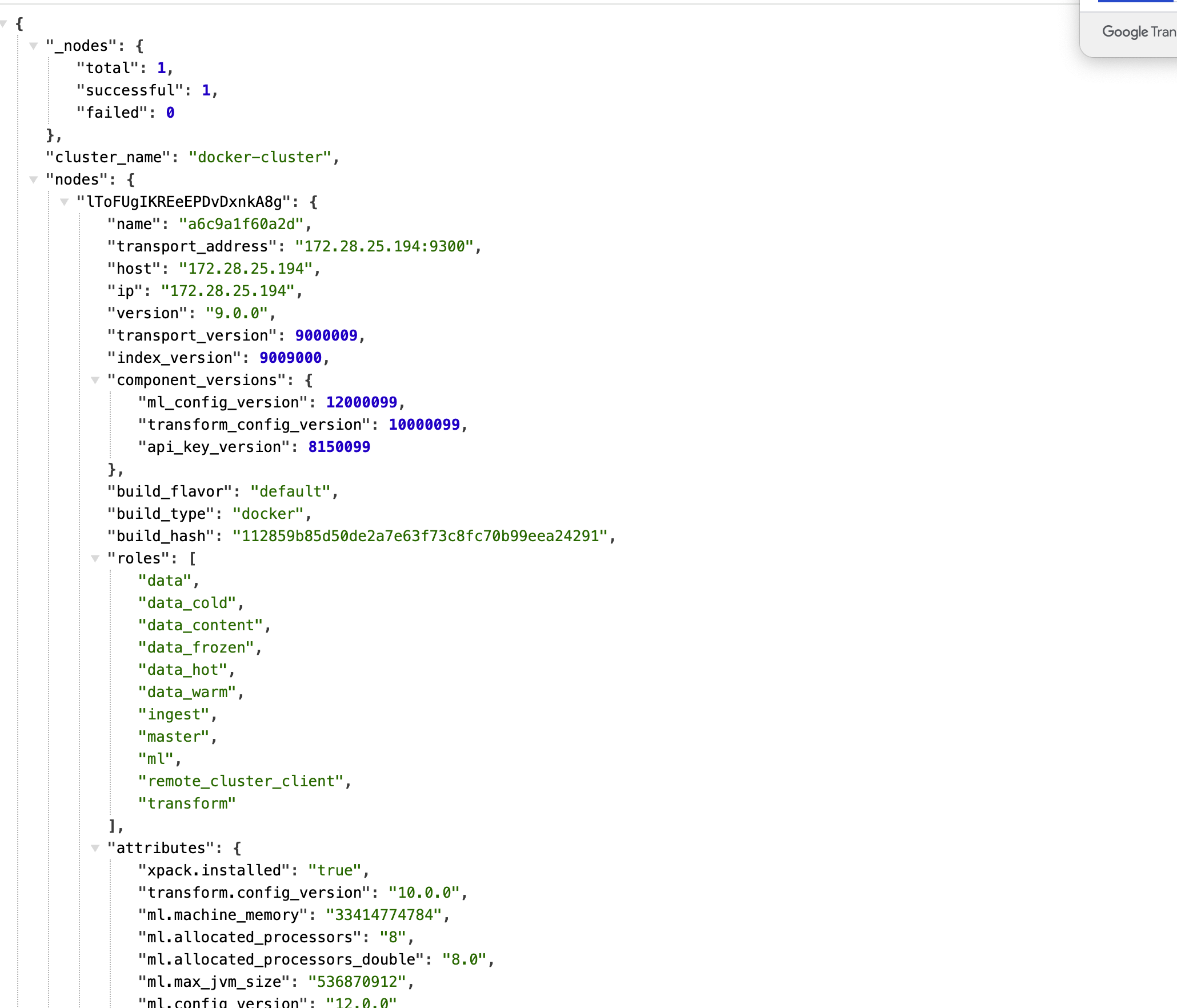
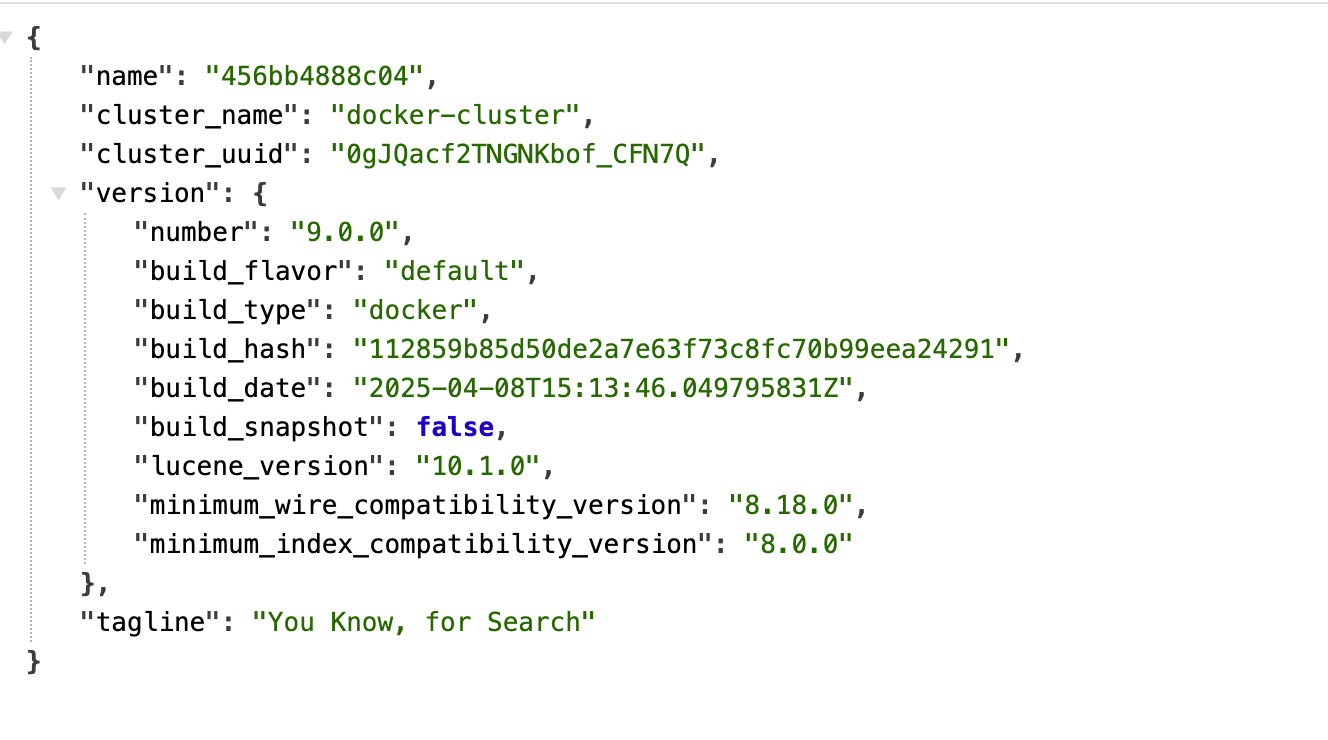
## Elasticsearch 到底是啥? 简单来说,Elasticsearch(简称 ES)就是一个**超级强大的搜索引擎**。想象一下,你有几百万条数据,如果用传统数据库一条条找,可能要找到天荒地老。但用 ES,几毫秒就能搞定! 它就像是给你的数据装了个 Google 搜索引擎,不管是商品、日志、文章,还是用户信息,都能秒速查找。 ### 谁在用它? - **维基百科**:全球最大的百科全书,搜索功能全靠它 - **GitHub**:代码搜索就是用的 ES - **Stack Overflow**:程序员的救命稻草,问题搜索也是它 - **京东、淘宝**:商品搜索背后的技术支撑 - **滴滴、美团**:位置搜索、商家搜索都有它的身影 https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch ## 如何使用? 截止到目前(2025 年 9 月 11 日 08:51:18),商店中的版本是一个单节点的服务,还没有集成看板功能,所以应用打开后,是这个页面:  上面是 Elasticsearch 服务启动后的欢迎页面,显示了当前节点和集群的状态、版本号(如 9.0.0)、集群名称(如 docker-cluster)等。这说明你的 Elasticsearch 实例已经运行,可以通过 API 进行数据操作和检索。 通过懒猫应用查看器,发现目前的验证是关闭的,不需要密码就能访问服务  ### 查询集群健康状态 打开终端,输入命令 `curl -X GET "https://elasticsearch.你的懒猫.heiyu.space/_cat/health?v"` 如果成功,你将看到类似如下的返回结果,显示集群的状态、节点数量等信息:  ### 查看所有索引 查看当前集群中所有的索引: `curl -X GET "https://elasticsearch.lanmao168.heiyu.space/_cat/indices?v" `  这将列出所有的索引,包括它们的名称、状态等信息。我目前还没有数据,所以都是空的。 用命令行看起来有点费劲,下面我用 postman 演示功能。注意lanmao168 是我的微服,需要你改成自己的。 ## 1. 创建索引 ### 请求方法: * **PUT** ### 请求 URL: ``` https://elasticsearch.lanmao168.heiyu.space/products ``` ### 请求体(Body): ```json {} ``` ### 说明: * 这里我们使用 `PUT` 请求创建一个名为 `products` 的索引。 * 请求体为空 `{}` 即可创建索引。 ### 操作步骤: 1. 打开 Postman,选择 `PUT` 方法。 2. 在 URL 栏中输入 `https://elasticsearch.lanmao168.heiyu.space/products`。 3. 选择 `Body`,并选择 `raw` 格式。 4. 在 `raw` 中选择 `JSON` 格式,内容写 `{}`。 5. 点击 `Send` 按钮发送请求。  如果索引创建成功,你会看到返回类似以下内容: ```json { "acknowledged": true, "shards_acknowledged": true, "index": "products" } ``` --- ## 2. 添加文档 ### 请求方法: * **POST** ### 请求 URL: ``` https://elasticsearch.lanmao168.heiyu.space/products/_doc/1 ``` ### 请求体(Body): ```json { "name": "Smartphone", "brand": "BrandX", "price": 699.99, "category": "Electronics" } ``` ### 说明: * 这里我们使用 `POST` 请求向 `products` 索引中添加一条文档。 * 文档 ID 是 `1`,内容是关于一款名为 `Smartphone` 的产品。 ### 操作步骤: 1. 在 Postman 中,选择 `POST` 方法。 2. 在 URL 栏中输入 `https://elasticsearch.lanmao168.heiyu.space/products/_doc/1`。 3. 选择 `Body`,并选择 `raw` 格式。 4. 在 `raw` 中选择 `JSON` 格式,填入上面的文档内容。 5. 点击 `Send` 按钮发送请求。  如果文档添加成功,你会看到类似以下的返回: ```json { "_index": "products", "_id": "1\n", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 } ``` --- ## 3. 查询文档 ### 请求方法: * **GET** ### 请求 URL: ``` https://elasticsearch.lanmao168.heiyu.space/products/_search ``` ### 请求参数(Params): ```text q=name:Smartphone ``` ### 说明: * 这里我们使用 `GET` 请求来查询 `products` 索引中所有 `name` 字段为 `Smartphone` 的文档。 ### 操作步骤: 1. 在 Postman 中,选择 `GET` 方法。 2. 在 URL 栏中输入 `https://elasticsearch.lanmao168.heiyu.space/products/_search`。 3. 在 `Params` 标签下添加一个参数: * **Key**: `q` * **Value**: `name:Smartphone` 4. 点击 `Send` 按钮发送请求。  返回的结果类似如下: ```json { "took": 283, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 0.2876821, "hits": [ { "_index": "products", "_id": "1\n", "_score": 0.2876821, "_source": { "name": "Smartphone", "brand": "BrandX", "price": 699.99, "category": "Electronics" } } ] } } ``` --- ## 4. 更新文档 ### 请求方法: * **PUT** ### 请求 URL: ``` https://elasticsearch.lanmao168.heiyu.space/products/_doc/1 ``` ### 请求体(Body): ```json { "doc": { "price": 799.99 } } ``` ### 说明: * 这里我们使用 `PUT` 请求来更新文档 ID 为 `1` 的 `price` 字段。 ### 操作步骤: 1. 在 Postman 中,选择 `PUT` 方法。 2. 在 URL 栏中输入 `https://elasticsearch.lanmao168.heiyu.space/products/_doc/1/_update`。 3. 选择 `Body`,并选择 `raw` 格式。 4. 在 `raw` 中选择 `JSON` 格式,填入需要更新的数据。 5. 点击 `Send` 按钮发送请求。  如果更新成功,你会看到返回的 JSON: ```json { "_index": "products", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 } ``` --- ## 5. 删除文档 ### 请求方法: * **DELETE** ### 请求 URL: ``` https://elasticsearch.lanmao168.heiyu.space/products/_doc/1 ``` ### 说明: * 使用 `DELETE` 方法删除 `products` 索引中 ID 为 `1` 的文档。 ### 操作步骤: 1. 在 Postman 中,选择 `DELETE` 方法。 2. 在 URL 栏中输入 `https://elasticsearch.lanmao168.heiyu.space/products/_doc/1`。 3. 点击 `Send` 按钮发送请求。  删除成功后,返回的响应如下: ```json { "_index": "products", "_id": "1", "_version": 3, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 3, "_primary_term": 1 } ``` --- ## 总结 Elasticsearch 不是银弹,但在搜索和日志分析场景下,它确实是个利器。不管你是要做商品搜索、日志分析,还是实时监控,ES 都能帮你轻松搞定。 先用单机版本熟悉功能,有需要再扩展集群,掌握了 ES 的核心概念和使用技巧,你就能在数据的海洋中游刃有余。 ## 相关资源 📚 - [Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html) - [GitHub 仓库](https://github.com/elastic/elasticsearch) - [中文社区](https://elasticsearch.cn/) - [Kibana 在线演示](https://demo.elastic.co/)

Elasticsearch 迁移方法
1. 快照(s3 file FS) 2. 跨集群迁移 3. es-dump 4. remote-reindex 5. Logstash https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch # Elasticsearch 迁移方法 Elasticsearch 迁移是将数据、索引和配置从一个 Elasticsearch 集群转移到另一个集群的过程。以下是几种常见的迁移方法: ## 1. 快照和恢复 (Snapshot and Restore) 这是最推荐的迁移方法,适用于大型数据集。 **步骤:** 1. 在源集群上创建共享文件系统仓库 ```json PUT /_snapshot/my_backup { "type": "fs", "settings": { "location": "/mnt/backups/my_backup" } } ``` 2. 创建快照 ```json PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true { "indices": "*", "ignore_unavailable": true, "include_global_state": false } ``` 3. 将备份文件复制到目标集群可访问的位置 4. 在目标集群上注册相同的仓库 5. 从快照恢复 ```json POST /_snapshot/my_backup/snapshot_1/_restore ``` ## 2. 使用 Elasticsearch Reindex API 适用于小规模数据或需要转换数据的迁移。 **步骤:** 1. 在目标集群创建索引(可选,可定义新映射) 2. 使用 reindex 从远程集群拉取数据 ```json POST _reindex { "source": { "remote": { "host": "http://source-cluster:9200" }, "index": "source_index" }, "dest": { "index": "dest_index" } } ``` ## 3. Logstash 迁移 使用 Logstash 作为数据管道进行迁移。 **示例配置:** ``` input { elasticsearch { hosts => ["http://source-cluster:9200"] index => "source_index" } } output { elasticsearch { hosts => ["http://target-cluster:9200"] index => "target_index" } } ``` ## 4. 使用 Elasticsearch-dump 工具 适用于小型索引的迁移。 **安装:** ```bash npm install elasticdump -g ``` **使用:** ```bash # 导出映射 elasticdump \ --input=http://source:9200/my_index \ --output=my_index_mapping.json \ --type=mapping # 导出数据 elasticdump \ --input=http://source:9200/my_index \ --output=my_index_data.json \ --type=data # 导入到目标集群 elasticdump \ --input=my_index_mapping.json \ --output=http://target:9200/my_index \ --type=mapping elasticdump \ --input=my_index_data.json \ --output=http://target:9200/my_index \ --type=data ``` ## 迁移注意事项 1. **版本兼容性**:确保目标集群版本兼容源集群版本 2. **网络带宽**:大数据量迁移需要考虑网络带宽 3. **停机时间**:根据业务需求规划可能的停机窗口 4. **验证数据**:迁移后务必验证数据完整性和一致性 5. **安全性**:确保迁移过程中的数据传输安全 选择哪种方法取决于您的具体需求、数据量、Elasticsearch 版本和可用资源。 # 更多 Elasticsearch 迁移方法 除了之前提到的方法,这里还有几种额外的 Elasticsearch 迁移方案,适用于不同场景: ## 5. 跨集群复制 (CCR - Cross Cluster Replication) **适用场景**:需要持续同步的迁移或零停机时间迁移 **要求**: - 需要 Elasticsearch 7.0+ 商业版(白金许可) - 两个集群必须能够相互通信 **步骤**: 1. 在源集群(leader)上启用 CCR: ```json PUT /_cluster/settings { "persistent": { "cluster.remote.remote_cluster.seeds": ["<target_cluster_transport_address>:9300"] } } ``` 2. 在目标集群(follower)上创建跟随索引: ```json POST /<index_name>/_ccr/follow { "remote_cluster": "remote_cluster", "leader_index": "<index_name>" } ``` 3. 当数据同步完成后,可以停止复制关系 ## 6. 自定义工具迁移 对于特殊需求,可以开发自定义迁移工具: - **基于Scroll API的批量导出**: ```python from elasticsearch import Elasticsearch, helpers es_source = Elasticsearch(['source_host']) es_target = Elasticsearch(['target_host']) query = {"query": {"match_all": {}}} scroll_size = 1000 docs = helpers.scan(es_source, index="source_index", query=query, size=scroll_size) helpers.bulk(es_target, docs, index="target_index") ``` 

Elasticsearch服务昨天还好好的,为什么今天突然访问不了了?
在使用 Elasticsearch 搭建本地或云端搜索服务时,难免会遇到服务偶发性或持续性无法访问的问题。本文将从服务状态、端口监听、网络配置、安全组等五个维度,系统梳理排查思路,帮助大家快速定位并解决访问失败的原因s https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch ## 🚢 一、Docker 部署场景下的排查方法 如果你是通过官方的 Docker Compose 部署 EasySearch,一般不会出现太大问题。但如果你像我一样在群晖或 NAS 上做过自定义配置,以下通用排查方法可以帮助你快速定位问题: --- ### 1️⃣ 容器是否正常运行? ```bash docker ps -a | grep easysearch ``` 若容器状态为 `Exited`,说明启动失败。请查看容器日志进一步排查: ```bash docker logs <容器名> ``` 如果你看到了如下错误信息,而你使用的是自签证书,可以暂时忽略: ``` javax.net.ssl.SSLHandshakeException: Empty client certificate chain javax.net.ssl.SSLHandshakeException: Received fatal alert: certificate_unknown ``` --- ### 2️⃣ 容器是否监听端口? 进入容器内部查看: ```bash docker exec -it <容器名> bash netstat -tlnp ``` 期望看到监听地址为 `0.0.0.0:9200` 和 `0.0.0.0:9300`,说明服务对外暴露成功。例如: ``` tcp 0 0 0.0.0.0:9200 0.0.0.0:* LISTEN 7/java tcp 0 0 0.0.0.0:9300 0.0.0.0:* LISTEN 7/java ``` --- ### 3️⃣ Docker 端口映射是否配置正确? 检查 `docker-compose.yml` 中 `ports` 映射是否正确,或者用以下命令查看实际映射情况: ```bash docker ps ``` 确认是否已将容器内部端口映射到宿主机。 宿主机上也可以通过 `netstat` 或 `ss` 命令查看端口监听: ```bash netstat -tlnp | grep 9200 ``` 确保监听地址是 `0.0.0.0:9200`,而非 `127.0.0.1`。 - `-t`:显示 TCP 连接 - `-l`:仅显示监听状态(Listening)的端口 - `-n`:以数字方式显示地址和端口(避免 DNS 解析) - `-p`:显示监听端口的程序 PID 和名称 --- ### 4️⃣ 网络配置是否连通? 使用 `curl` 测试: ```bash curl http://yourhost:9200 ``` 如需远程访问,需确认: - 容器监听的是 `0.0.0.0` - 映射端口已开放 - 网络桥接配置正常 --- ## 🧩 二、非 Docker 部署场景的排查方法 ### 1️⃣ 服务是否启动? ```bash ps aux | grep search ``` 也可查看 `nohup.out` 或 logs 目录中的日志文件,看是否存在环境变量、路径错误、权限不足等问题。 --- ### 2️⃣ 是否监听了正确的地址? ```bash netstat -tulnp | grep java ``` EasySearch 默认只监听本地,建议修改配置文件: ```yml # config/Elasticsearch.yml network.host: 0.0.0.0 http.port: 9200 ``` --- ### 3️⃣ 防火墙是否放行? 确认 Linux 主机的防火墙设置: ```bash sudo ufw status sudo iptables -L -n ``` 确保目标端口(如 9200、9300)已允许外部访问。 --- ## 🌐 三、通用排查项(适用于所有部署方式) ### ✅ 云服务器:检查安全组 云服务商(如 AWS、阿里云)通常还需配置安全组或防火墙规则,确保目标端口对外开放。 ### ✅ DNS 设置是否正确 使用 `dig` 和 `ping` 测试域名解析与连通性: ```bash dig +short yourdomain.com ping yourdomain.com ``` 可用 `traceroute` 进一步分析路径:(我在 MacOS 下测试的) ```bash sudo traceroute -P TCP -p 9200 192.168.X.X traceroute to 192.168.X.X (192.168.X.X), 64 hops max, 40 byte packets 1 192.168.X.X (192.168.X.X) 3.756 ms 3.208 ms 3.142 ms ``` ## ✅ 总结:排查 Elasticsearch 的四步法 ```markdown 1. 服务是否启动? 2. 端口是否监听? 3. 网络是否打通? 4. 安全组是否放行? ``` 无论是本地部署还是云端部署,掌握上述排查方法,你就能迅速定位并解决 Elasticsearch 无法访问的问题。 

Elasticsearch指南 修改索引主分片的三种方式(split shrink reindex)
https://appstore.lazycat.cloud/#/shop/detail/xu.deploy.elasticsearch Elasticsearch的架构中,索引的主分片数(`index.number_of_shards`)一旦创建就无法直接修改。这给实际使用带来挑战: - 设得太少,查询/写入瓶颈出现; - 设得太多,资源浪费、集群不稳; - 想变更结构,却发现配置是“写死”的。 本文将带你深入了解三种常见但本质不同的索引重构方式:`split`、`shrink`、`reindex`,教你如何选择合适方案、安全操作,并解释为什么**split + shrink 无法取代 reindex**。 --- ## 📌 一张图概览三种方式 | 方法 | 是否重建索引 | 可否原名使用 | 改分片数限制 | 是否保留数据 | 是否改结构(mapping/settings) | 常见用途 | | --------- | ------------ | --------------- | ----------------------- | ------------ | ------------------------------ | -------------------- | | `split` | ✅ 新建索引 | ❌ 不支持 | 只能 × 倍数(如 1→2→4) | ✅ 是 | ❌ 否 | 提升写入并发/读性能 | | `shrink` | ✅ 新建索引 | ❌ 不支持 | 只能 ÷ 因数(如 4→2→1) | ✅ 是 | ❌ 否 | 合并历史数据分片 | | `reindex` | ✅ 新建索引 | ✅ 支持(先删) | 任意 | ✅ 是 | ✅ 支持 | 自定义结构/分片/升级 | --- ## 🔧 一、split:将分片数量倍增(如 1 → 2 → 4) > **适用于:** 提升并发能力、增加查询/写入并行度。 <!-- more --> ### ✅ 条件要求: - 原始索引必须设置 `index.blocks.write: true`(只读);主要是防止写入继续增长。 - 新分片数必须是原主分片的 **倍数**; - 不能使用原名,目标索引必须另起新名。 ### 🛠 操作示例: ````bash # 设置只读 PUT /abc/_settings { "settings": { "index.blocks.write": true } } 如果不设置为只读的话,就报错: ```json { "error": { "root_cause": [ { "type": "illegal_state_exception", "reason": "index abc must be read-only to resize index. use \"index.blocks.write=true\"" } ], "type": "illegal_state_exception", "reason": "index abc must be read-only to resize index. use \"index.blocks.write=true\"" }, "status": 500 } ```` #### 拆分索引(1 → 4) ``` POST /abc/_split/abc_split_2shards { "settings": { "index.number_of_shards": 2 } } ``` 执行结果如下: ``` { "acknowledged": true, "shards_acknowledged": true, "index": "abc_split_2shards" } ``` 如果不是倍数也会报错: ```json { "error": { "root_cause": [ { "type": "illegal_argument_exception", "reason": "the number of source shards [13] must be a factor of [25]" } ], "type": "illegal_argument_exception", "reason": "the number of source shards [13] must be a factor of [25]" }, "status": 400 } ``` 查看索引的信息: ``` GET /abc_split_2shards/_settings?flat_settings=true ``` > /\_settings:Elasticsearch 提供的 API 端点,用于查看索引设置。 > ?flat_settings=true:查询参数,使返回结果以扁平化的键值对形式展示(而非嵌套结构)。 可以看到目标的索引也是只读的,这在 Easysearch 里是 ElasticSearch 不一样的地方。 ```json { "abc_split_2shards": { "settings": { "index.blocks.write": "true", "index.creation_date": "1750747232004", "index.number_of_replicas": "1", "index.number_of_shards": "2", "index.provided_name": "abc_split_2shards", "index.resize.source.name": "abc", "index.resize.source.uuid": "3NY_W5B_TzimoEGdoA74cg", "index.routing.allocation.initial_recovery._id": null, "index.routing_partition_size": "1", "index.uuid": "e2BQiTRKTlaTS5OE8kmiXw", "index.version.created": "1130099", "index.version.upgraded": "1130099" } } } ``` 然后使用这个来解锁 write block。 ``` PUT /abc_split_2shards/_settings { "settings": { "index.blocks.write": false } } ``` 如果你不想让目标索引变成只读。也可以在\_split 的时候加上 "index.blocks.write": false。 ```json POST /abc_split_2sharxds/_split/qwe { "settings": { "index.blocks.write": false, "index.number_of_shards": 26 } } ``` ## 🔧 二、shrink:将分片数量整除压缩(如 8 → 4 → 1) > **适用于:** 历史归档数据压缩、节省内存、提升查询效率。 ### ✅ 条件要求: - 所有主分片必须集中在同一节点; - 原索引必须只读; - 新分片数必须是旧分片数的 **因数**; - 同样不能保留原名,需新建索引名。 ### 🛠 操作示例: ````bash # 强制所有主分片调度到 node-1 PUT /source_index/_settings { "settings": { "index.blocks.write": true, "index.routing.allocation.require._name": "node-1", "index.number_of_replicas": 0 } } 如果不是只读同样报错: ```json { "error": { "root_cause": [ { "type": "illegal_state_exception", "reason": "index test1 must be read-only to resize index. use \"index.blocks.write=true\"" } ], "type": "illegal_state_exception", "reason": "index test1 must be read-only to resize index. use \"index.blocks.write=true\"" }, "status": 500 } ```` ### 合并为一个分片 ``` POST /source_index/_shrink/source_index_1 { "settings": { "index.blocks.write": false, "index.number_of_shards": 1 } } ``` ### 解锁 ``` PUT /source_index_1/_settings { "settings": { "index.blocks.write": false } } ``` ## 🔧 三、reindex:拷贝数据 + 新建结构 + 替换旧索引 > **适用于:** 任意修改分片数、字段结构、settings,或实现“看起来改了原索引”的效果。 ### ✅ 优势: - 唯一支持**任意分片数修改**; - 可自由重构 mapping、settings; - 可支持**保留原名**(删除旧索引 + 重新创建); - 可带条件、分页、脚本拷贝数据; - 是唯一可模拟“修改原索引分片”的方式。 ### 🛠 操作步骤(保留原名但改变结构): ```bash # 1. 创建临时索引结构(你想要的新结构) PUT /my_index_v2 { "settings": { "index.number_of_shards": 5, "index.number_of_replicas": 1 }, "mappings": { "properties": { "user": { "type": "keyword" }, "message": { "type": "text" } } } } # 2. 拷贝数据 POST /_reindex { "source": { "index": "my_index" }, "dest": { "index": "my_index_v2" } } # 3. 删除旧索引(谨慎) DELETE /my_index # 4. 创建同名索引(新结构) PUT /my_index { "settings": { "index.number_of_shards": 3, "index.number_of_replicas": 1 }, "mappings": { "properties": { "user": { "type": "keyword" }, "message": { "type": "text" } } } } # 5. 再次拷贝数据(回填) POST /_reindex { "source": { "index": "my_index_v2" }, "dest": { "index": "my_index" } } 6. 查看索引,并且删除目标索引 GET _cat/indices/my_index*?v  最后删除my_index_v2 即可 DELETE /my_index_v2 ``` --- ## ⚠️ 为什么 shrink + split 不能替代 reindex? 很多用户会问:能不能 `shrink → split` 或 `split → shrink` 拼接出任意分片数? 答案是:**数学上不成立 + 实战限制太多。** | 操作 | 说明 | | --------------- | --------------------------------------------------------------------- | | split 只能倍增 | 例如:1 → 2 → 4 → 8 ✅,但不能变成 3、5、6 ❌ | | shrink 只能整除 | 例如:8 → 4 → 2 → 1 ✅,但不能变成 3、5 ❌ | | 二者组合 | 受限于倍数 × 因数关系,**不是万能变换**(大多数目标分片数根本到不了) | ### ✅ 唯一万能方式:`reindex` 可以任意: - 调整分片数 ✅ - 修改字段结构 ✅ - 改 settings ✅ - 保留索引名 ✅ --- ## ✅ 最佳实践总结 | 场景 | 推荐方式 | 理由 | | ---------------------------- | ------------------------------- | ------------------------ | | 写入并发不足(1 → 4) | split | 快速、低风险 | | 存储/查询优化(8 → 1) | shrink | 节省资源、适合归档 | | 修改索引结构、字段、settings | reindex | 最灵活、唯一支持任意结构 | | 想保留原名但改分片数 | reindex(配合 delete/recreate) | 只有它能实现 | | 不想中断服务 | reindex + alias 切换 | alias 实现无缝替换 | --- ## 🚀 附加建议 S\* split/shrink 一般用于 **线上小范围结构调整**; - reindex 用于 **升级、清洗、结构优化**等更大粒度的改造; - 如果你不想中断服务,强烈建议使用 **alias + reindex** 做平滑切换; - 不建议用 shrink + split 拼接方案,实际运维性差、数学关系苛刻。 
懒猫评分/评论
0.0
0 条评论
新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
ES 单节点,后续上 kibana 和多节点
此 App 尚未收到足够的评分或评论,无法显示评论列表。