Scraperr 实用攻略:小白也能轻松上手的网页数据抓取神器
## Scraperr 是什么?
简单说,Scraperr 就是个帮你从网页上"偷"数据的工具。别担心,这里说的"偷"是合法的数据抓取 😄。
想象一下,你要收集某个购物网站上所有商品的价格信息,手动复制粘贴得复制到天荒地老,而 Scraperr 可以帮你几分钟搞定。
**核心优势:**
- 🎯 **精准定位**:用XPath选择器精确抓取你想要的内容
- 🚀 **简单易用**:网页界面操作,不需要写复杂代码
- 📦 **自托管**:数据安全掌握在自己手里
- 🔄 **批量处理**:一次提交多个抓取任务
- 📊 **结果可视化**:抓取的数据直接在表格里展示
https://appstore.lazycat.cloud/#/shop/detail/top.j0k3r.scraperr
## 实战攻略
应用安装后,打开即主页面

先注册一个账号

登录进去,左下角会有提示

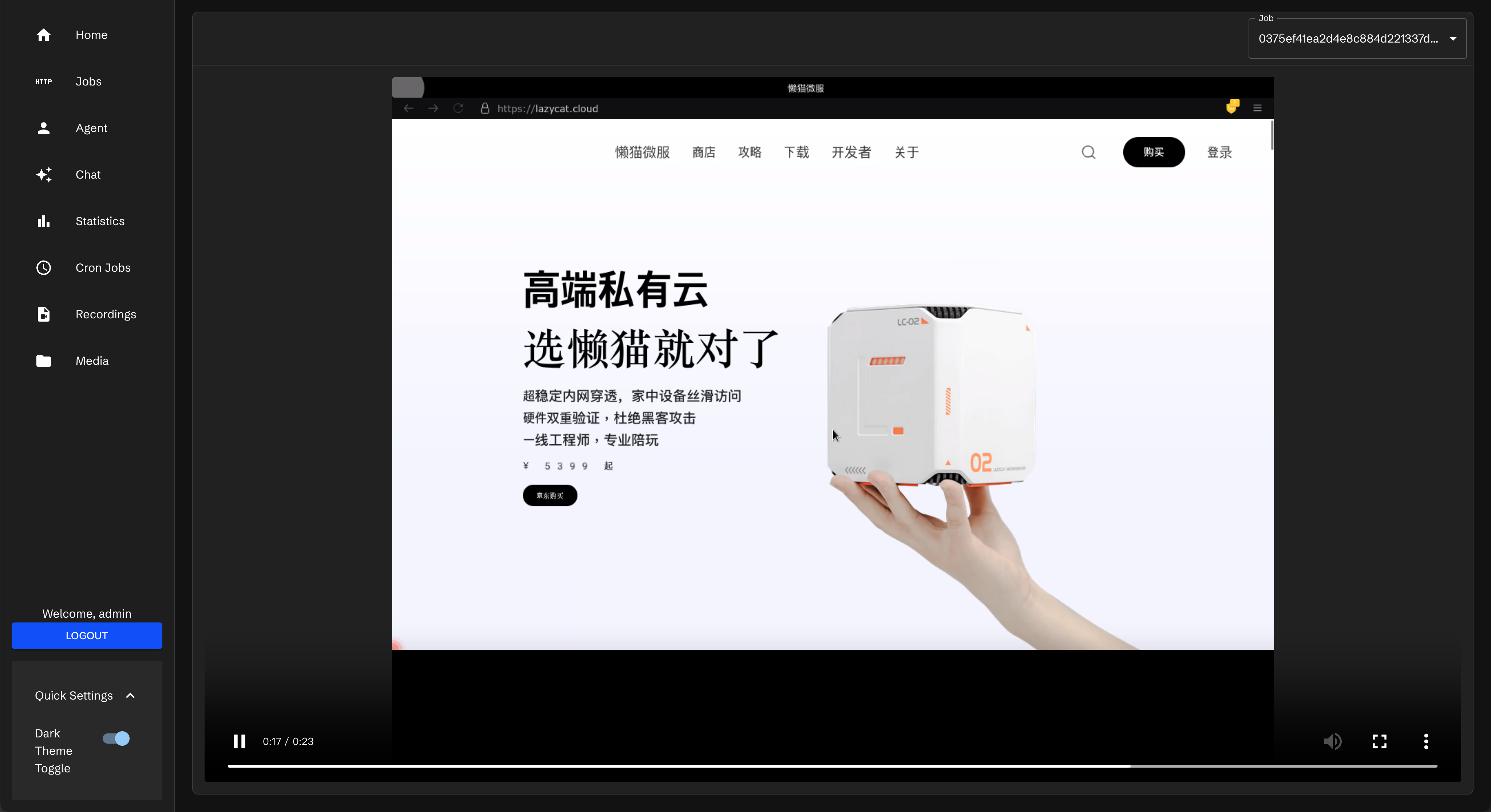
以老王的博客为例https://manateelazycat.github.io/index.html

### 理解XPath(别被吓到,真的很简单)
XPath 就像是网页元素的"地址"。比如你要找某个商品的标题,XPath 会告诉程序:"去第3个div里面的第2个span标签找"。
**实用XPath技巧:**
1. **右键大法**:在网页上右键点击你想抓取的内容 → 检查元素 → 右键选择"Copy XPath",直接复制现成的路径
2. **常用模式**:
- 抓取所有链接:`//a/@href`
- 抓取所有图片:`//img/@src`
- 抓取特定class的文本:`//div[@class='product-title']/text()`
- 抓取包含特定文字的元素:`//span[contains(text(), '价格')]`
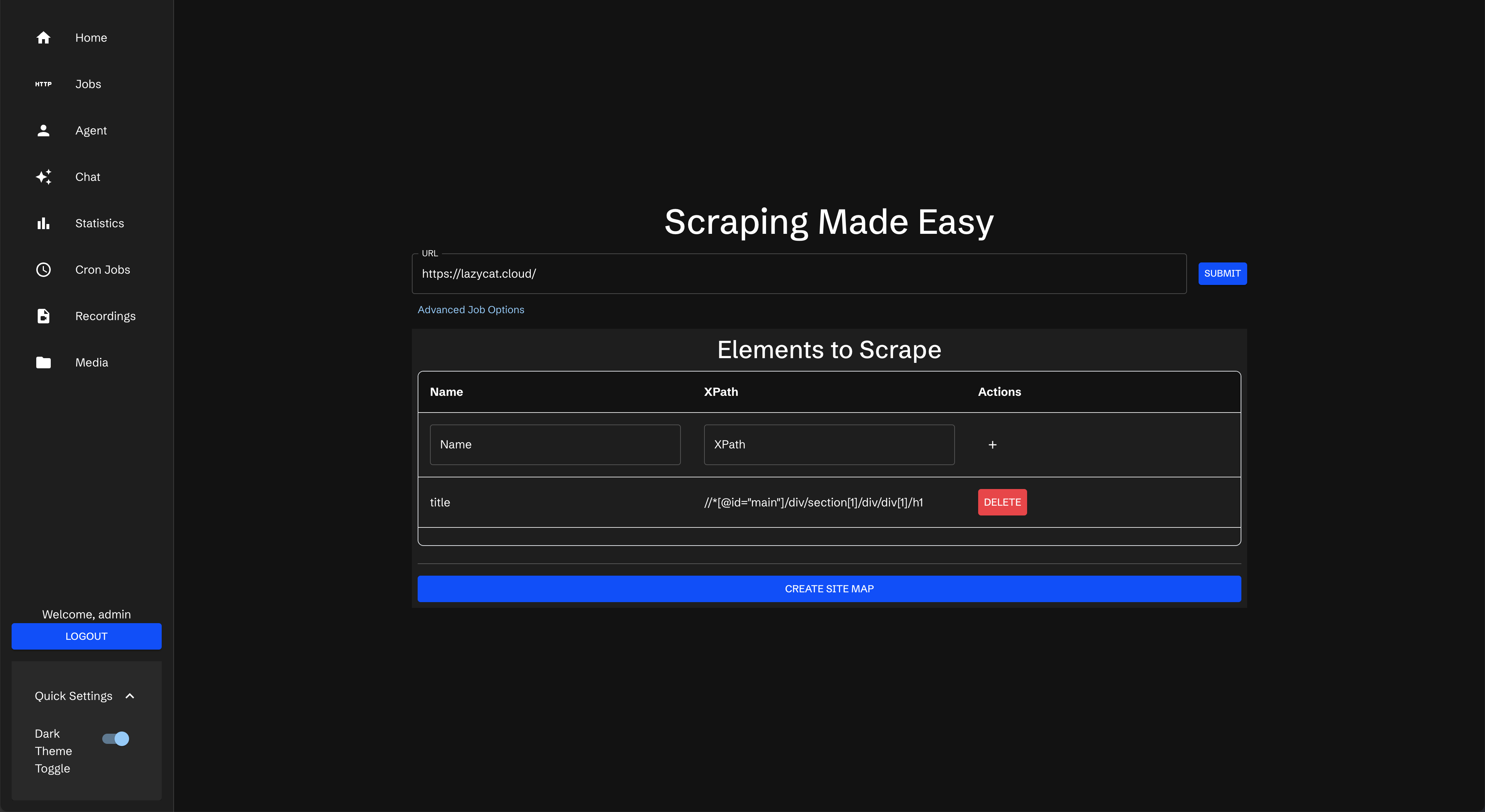
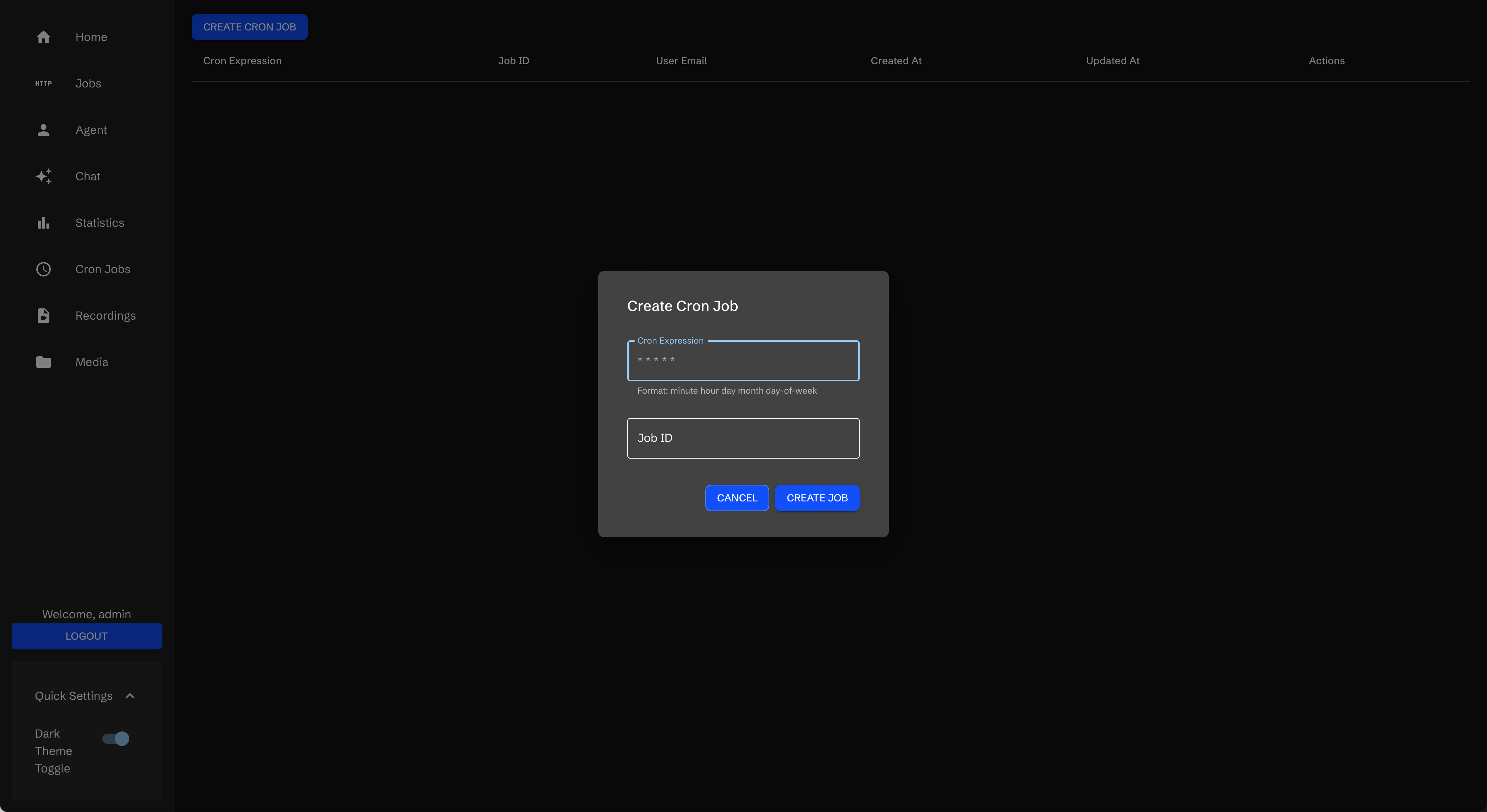
以老王博客为例
URL:老王的博客地址为 https://manateelazycat.github.io/index.html
Name:因为是抓标题,所以输入了 文章标题
XPath:可以在浏览器中获取到/html/body/div[1]/ul
点击提交

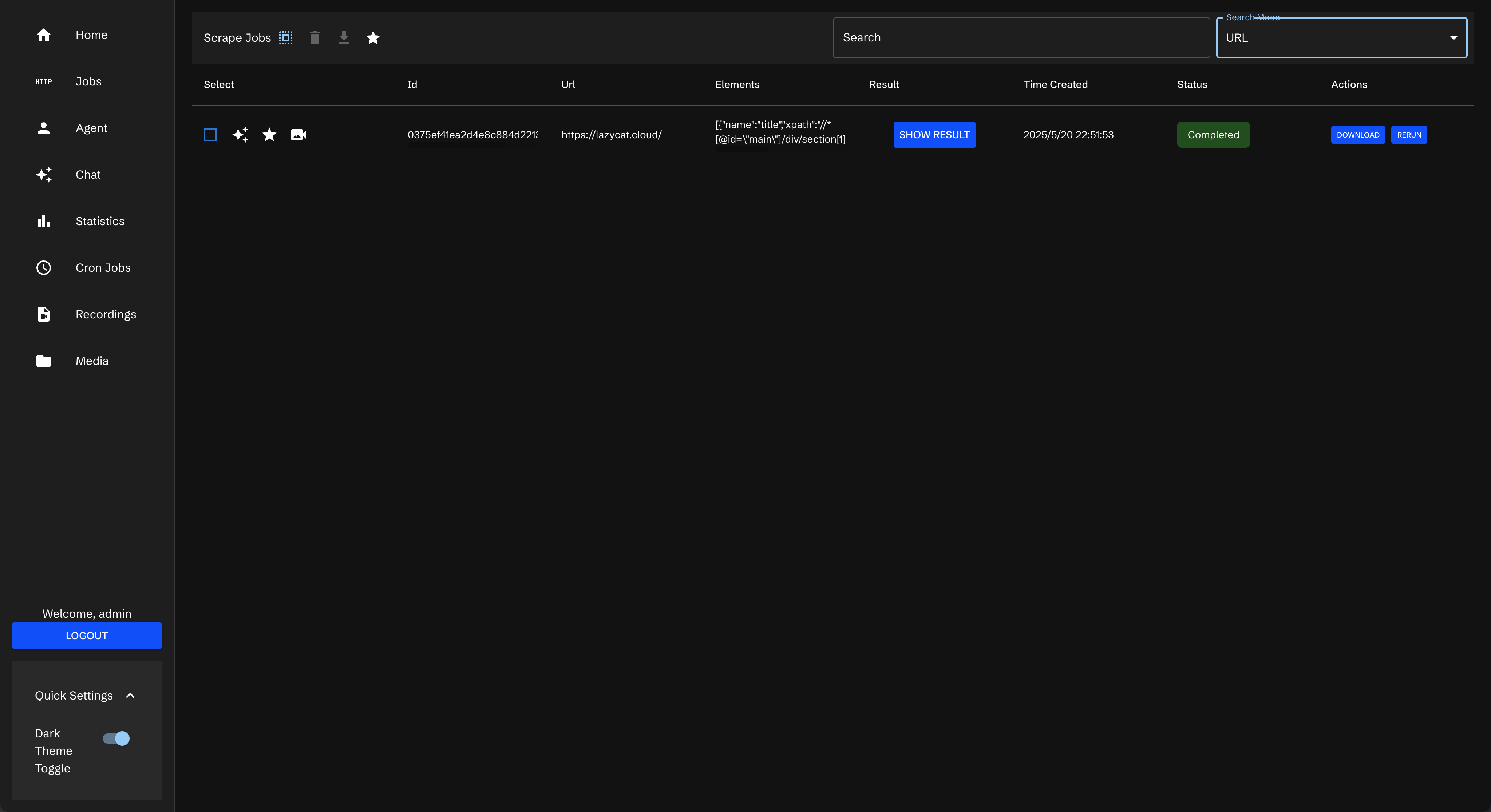
左下角会提示创建了一个Job

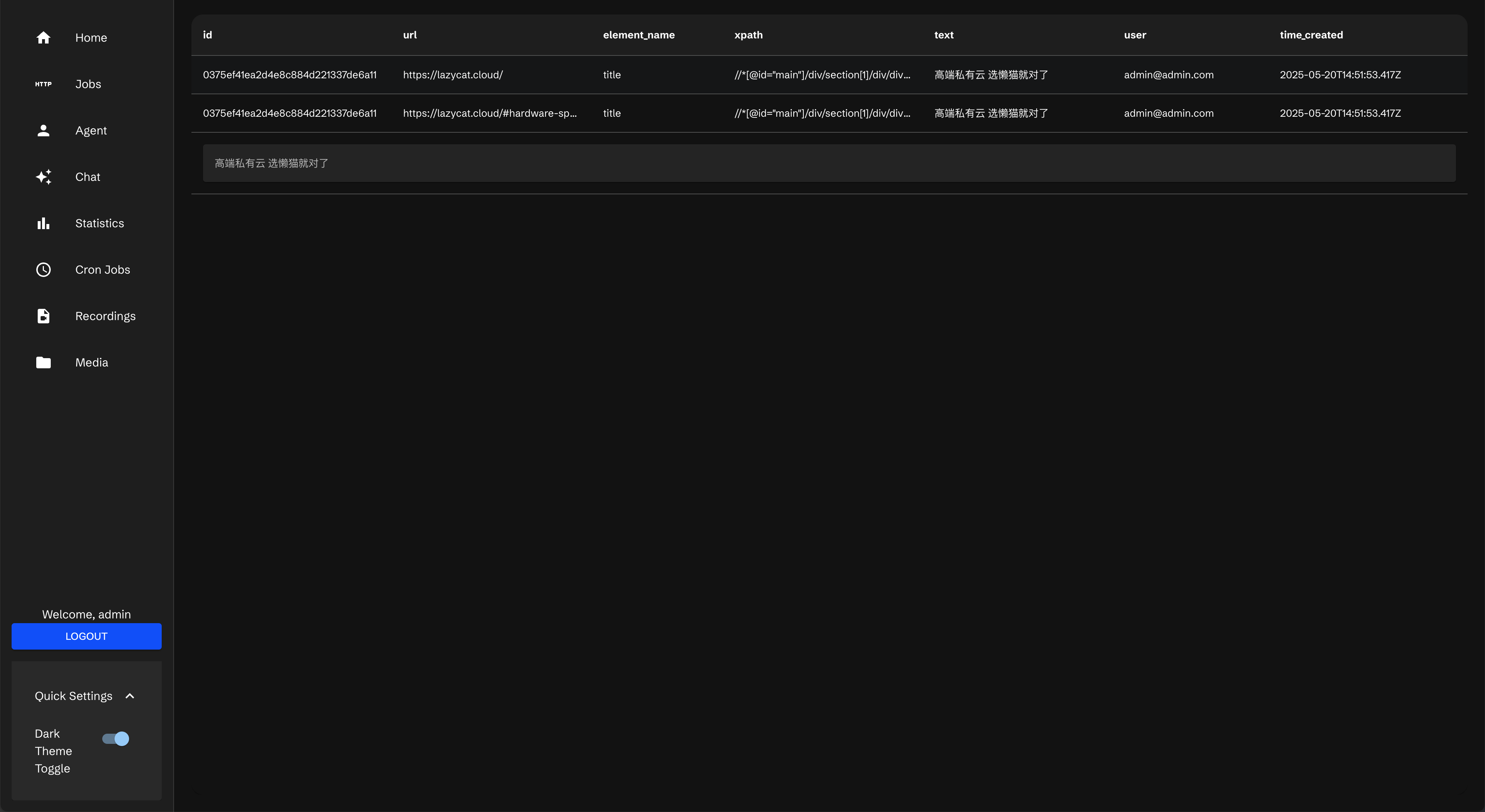
到左侧Job里可以看到

它有一定概率会失败,如果成功后会显示complete
点击 showresult

点进去,可以看到内容都抓到了

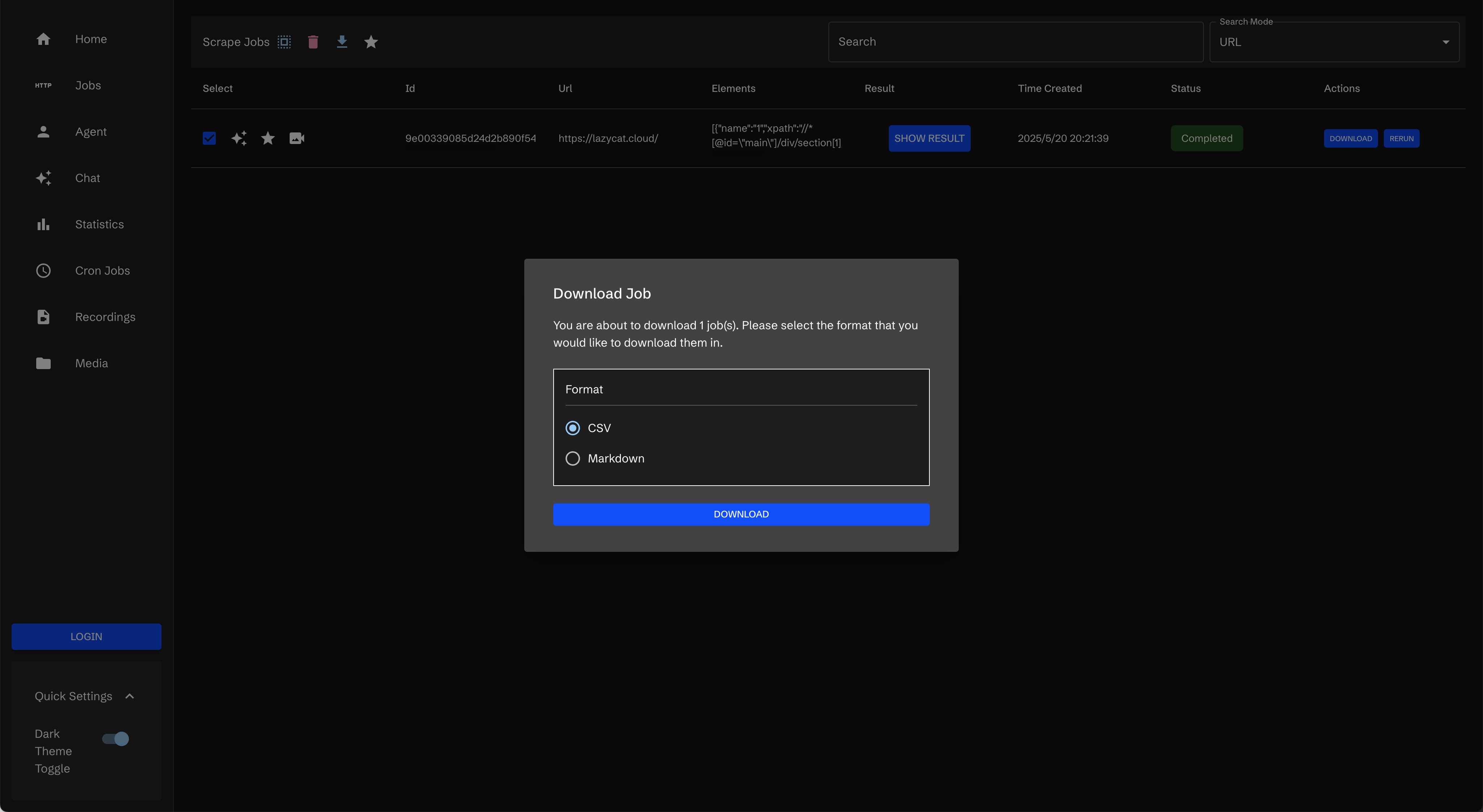
还可以下载下来


我下载的csv中文乱码了

markdown没问题

### 注意事项(重要!)合规使用
1. **检查robots.txt**:访问`网站域名/robots.txt`看看是否允许抓取
2. **遵守使用条款**:不要抓取明确禁止的内容
3. **控制频率**:不要太频繁请求,给服务器留点喘息空间
## 总结
Scraperr 是个不错的工具,特别适合需要定期抓取数据但又不想写复杂爬虫代码的朋友。界面清爽,功能齐全,而且支持自托管,数据安全有保障。
有了这个工具,以后收集数据就轻松多了。不过记得合规使用,做个有素质的数据收集者 😊
---
*提示:本文仅为技术交流,使用时请遵守相关法律法规和网站使用条款。*

'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)

'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
此 App 尚未收到足够的评分或评论,无法显示评论列表。