llama-dash 懒猫微服使用攻略
> 一句话概览:llama-dash 是本地 LLM 网关控制台,用来管理 llama-swap / llama.cpp 模型、OpenAI 兼容接口、API Key、路由策略、请求日志和运行指标。
https://appstore.lazycat.cloud/#/shop/detail/fun.selfstudio.app.migration.llama-dash
## 适合谁
如果你已经在懒猫微服里放了本地大模型,或者准备把 GGUF 模型通过 `llama.cpp` 跑起来,llama-dash 会更像一个运维面板:它不直接替代模型推理,而是把模型加载状态、请求入口、调用日志、Playground 和指标监控放到同一个网页里。
懒猫版已经接入 LazyCat OIDC。安装后打开应用,优先点击 `Continue with LazyCat`,不用再维护一组单独的控制台账号。

## 开始前准备
1. 在懒猫微服里安装 `llama-dash`。
2. 准备一个 GGUF 模型文件,例如 `llama-3.gguf`、`qwen2.5-7b-instruct-q4_k_m.gguf` 这类可以由 `llama-server` 启动的模型。
3. 把模型文件放入应用持久化模型目录。懒猫包内的容器路径是 `/models`,配置里也应使用这个路径。
4. 如果要给 OpenAI SDK、Continue、Open WebUI、Claude Code 等客户端使用,先决定是否需要 API Key。个人内网测试可以先不创建,长期使用建议创建。
## 01 首次打开:看 Dashboard 是否健康
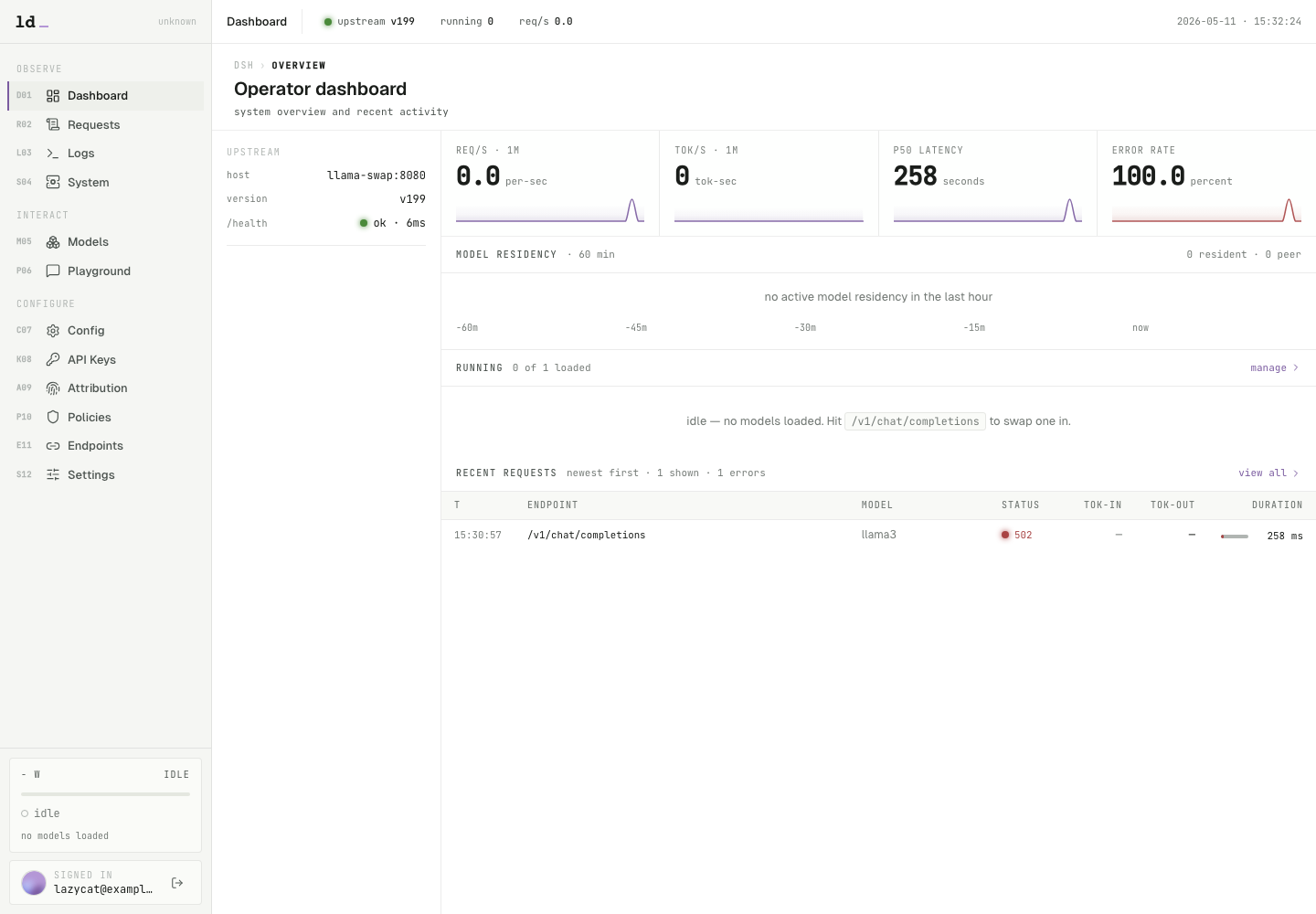
登录后先看 `Dashboard`。这里最重要的是左侧 `upstream` 状态和 `/health`:绿色 `ok` 表示 llama-dash 已经连上内置的 `llama-swap` 后端。上方的 `req/s`、延迟和错误率会随着请求实时变化,下面会显示最近请求。

截图里已经有一次测试请求,因此能看到错误率和最近请求记录。真实接入模型后,成功调用会在这里显示为 200 状态,并逐步积累延迟、Token 和请求量指标。
## 02 添加第一组模型配置
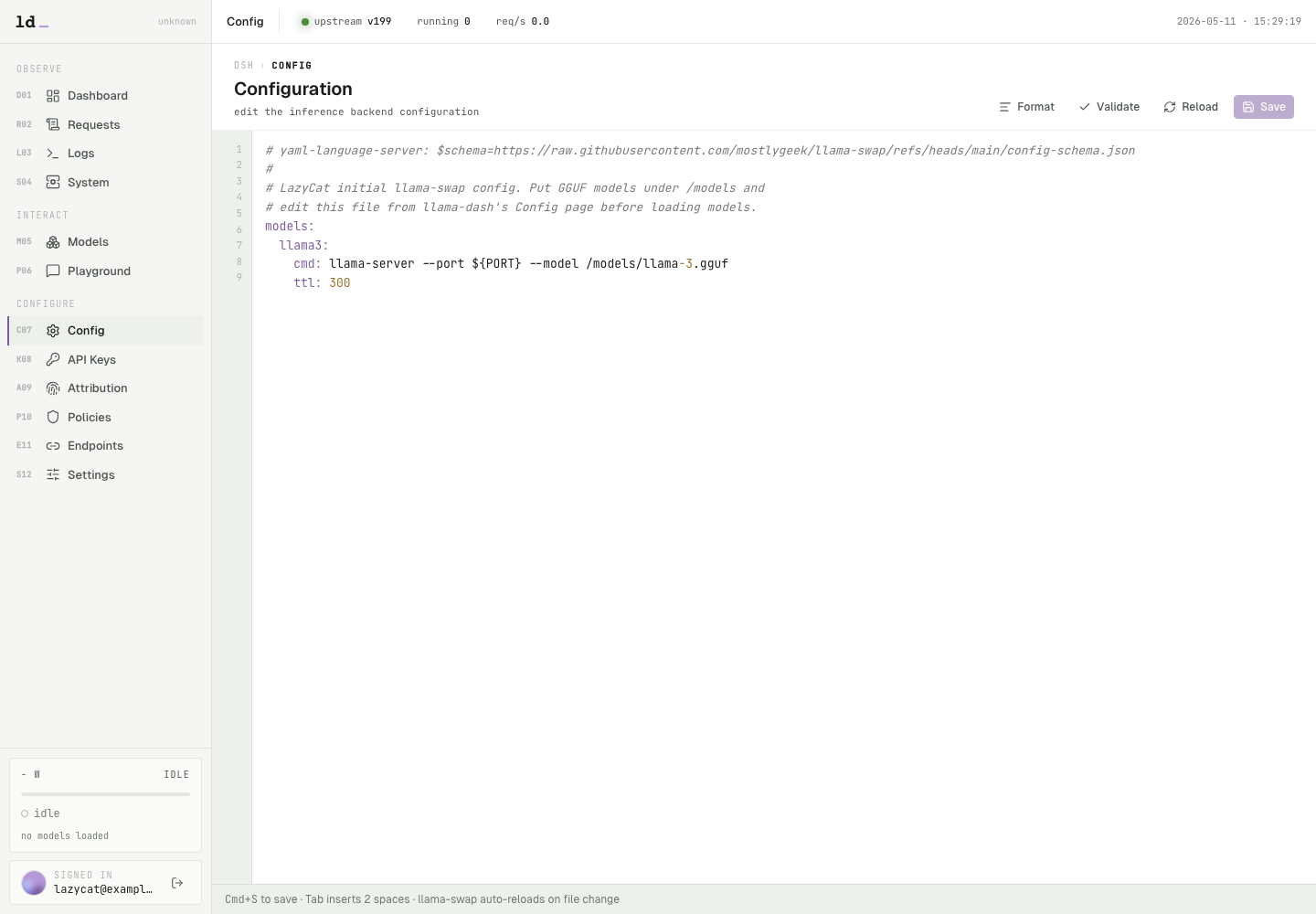
进入 `Config`,这是 llama-swap 的 `config.yaml` 编辑器。懒猫版默认把模型文件目录挂载到 `/models`,所以模型路径建议写成 `/models/你的模型文件.gguf`。

可以从一个最小配置开始:
```yaml
models:
llama3:
cmd: llama-server --port ${PORT} --model /models/llama-3.gguf
ttl: 300
```
配置要点:
- `llama3` 是对外暴露的模型名,后面客户端请求时会用到。
- `cmd` 中的 `--model` 必须指向真实存在的 GGUF 文件。
- `${PORT}` 由 llama-swap 分配,不要写死端口。
- `ttl` 表示空闲多久后卸载模型,单位是秒。
编辑后先点 `Validate`,通过后再点 `Save`。保存后内置 llama-swap 会自动重载配置。回到 `Models` 页面可以看模型是否出现在列表中。

如果列表为空,通常是配置还没保存、模型文件路径不对,或者启动命令需要根据你的模型和硬件继续调整。
## 03 创建 API Key,给客户端一个稳定入口
`API Keys` 用来控制哪些客户端可以访问代理接口。你可以先在页面右上角点 `Create key`,给不同客户端单独建 key,比如 `open-webui-home`、`continue-laptop`。创建后只展示一次完整密钥,保存到客户端配置里即可,攻略和截图里不要展示真实密钥。

如果页面提示没有配置 API Key,代理会处于开放模式,适合首次内网调试;长期运行建议创建 key,并按模型、RPM、TPM 或月度 Token 配额做限制。
## 04 复制 Endpoint,接入 OpenAI 兼容客户端
打开 `Endpoints`,复制 Base URL。懒猫版的对外入口是:
```text
https://你的 llama-dash 域名/v1
```

页面内置了 curl、Python、TypeScript、Home Assistant、Claude Code、opencode、Continue、Open WebUI 等示例。最小 curl 结构如下:
```bash
curl https://你的 llama-dash 域名/v1/chat/completions \
-H "Authorization: Bearer sk-your-key-here" \
-H "Content-Type: application/json" \
-d '{
"model": "llama3",
"messages": [{"role": "user", "content": "Hello!"}]
}'
```
如果没有启用 API Key,可以先省略 `Authorization` 头做连通性测试;正式使用建议补上。
## 05 用 Playground 先跑小提示词
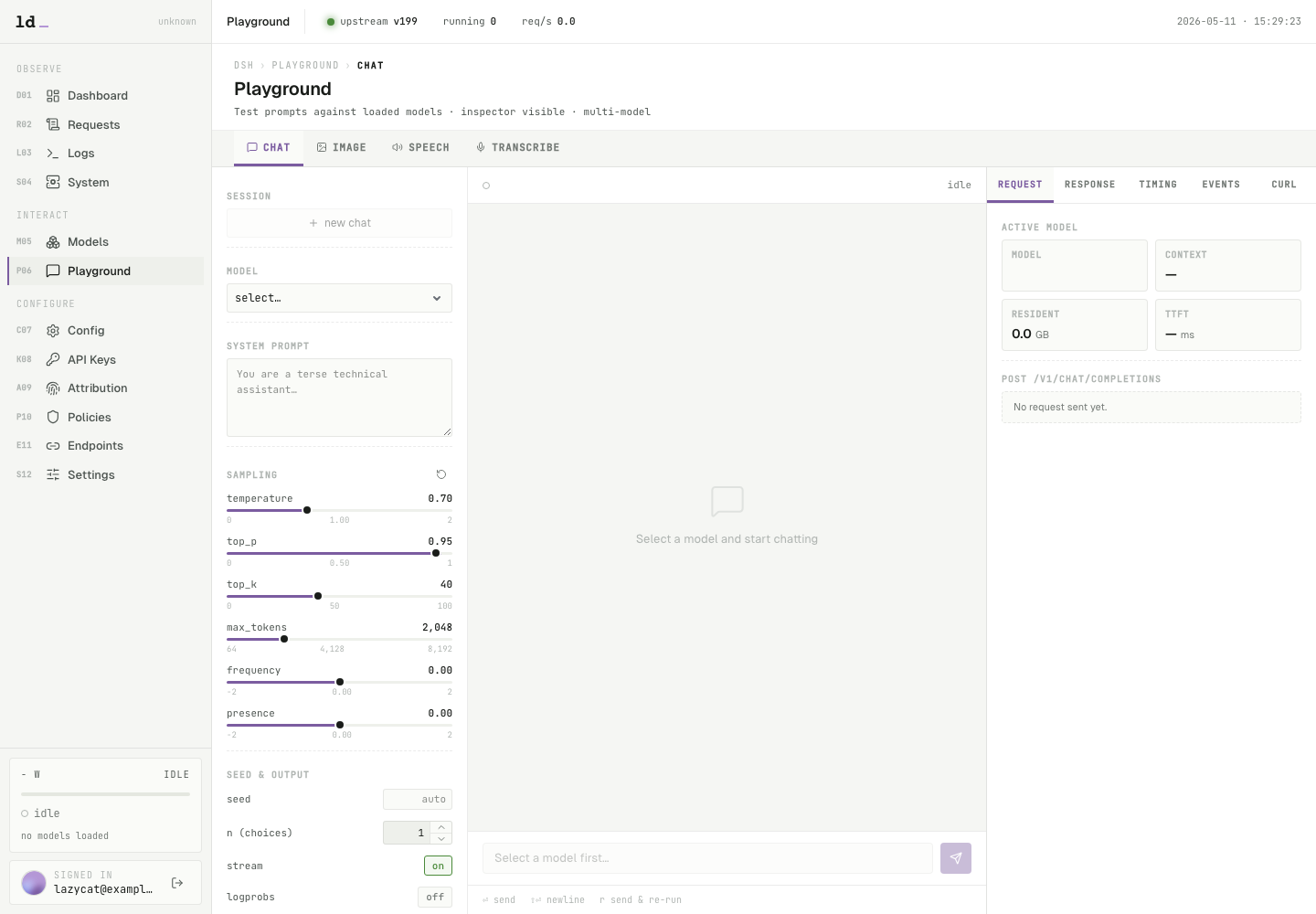
`Playground` 适合做第一条验证请求。选择模型后,输入一个短提示词,例如“用三句话介绍你自己”,再发送。右侧 Inspector 会显示 request、response、timing 和事件流。

如果模型下拉框为空,先回到 `Config` 检查模型名和文件路径。如果发送后一直没有响应,去 `Logs` 或 `Requests` 看后端启动错误。
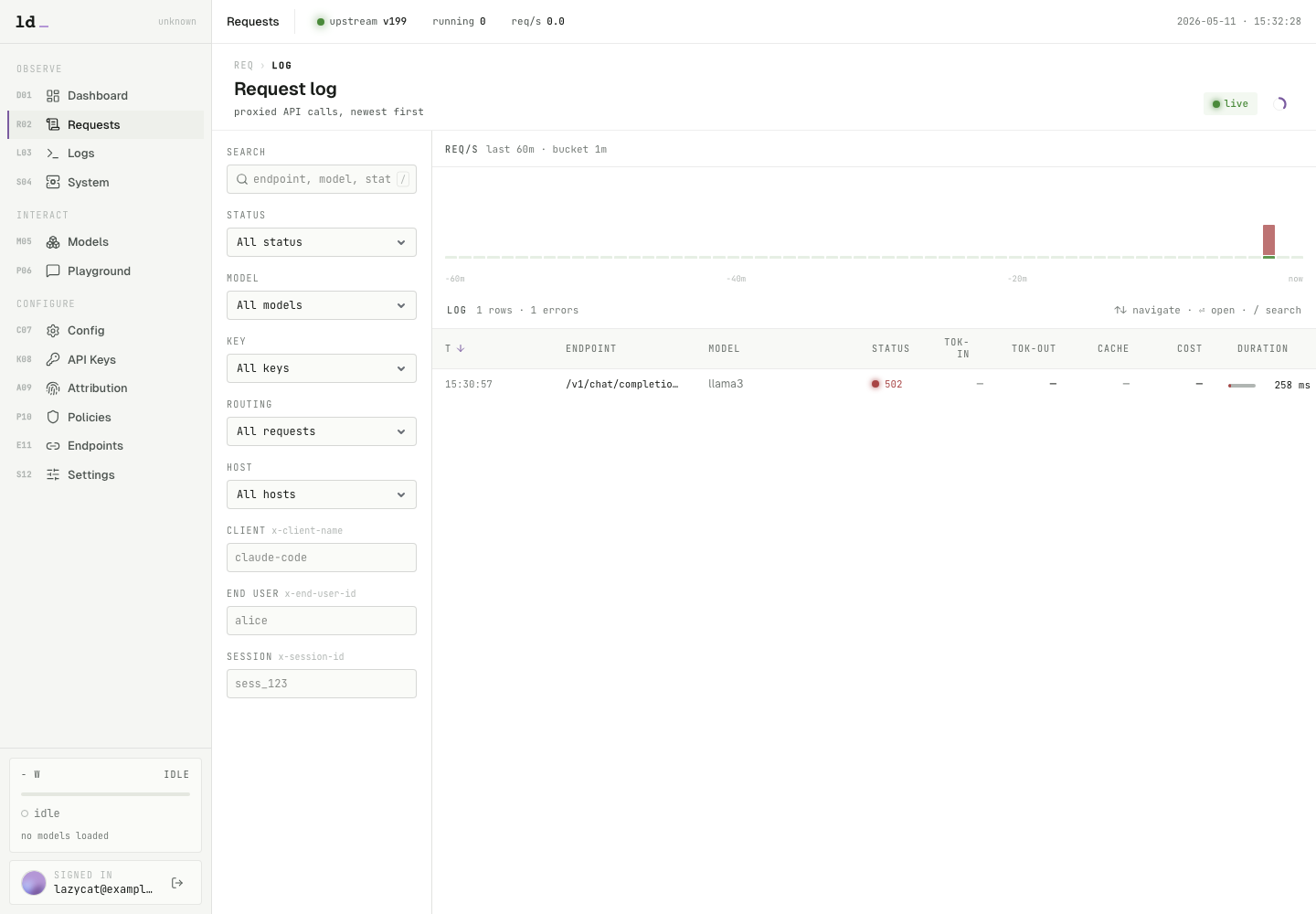
## 06 用 Request Log 排查问题
所有完成的 `/v1/*` 请求都会进入 `Requests`。你可以按状态码、模型、API Key、路由规则、客户端和 end user 过滤。下面这张图是一条故意在未放入模型文件时发出的测试请求,所以状态是 502;如果模型配置正确,同样位置会显示 200 或流式请求的完成状态。

点开一条请求,可以看到方法、端点、模型、状态码、耗时、请求体、响应头、客户端来源和路由结果。排查“模型没启动”“路径写错”“客户端用错模型名”时,这个详情页比只看客户端报错更直接。

## 07 进阶:System、Policies 和 Metrics
`System` 页面适合确认运行环境、GPU 采样、后端健康和版本信息;`Policies` 可以做模型改写、拒绝规则、鉴权透传和外部 `/v1` 上游转发;`/metrics` 则可以接 Prometheus,长期观察请求量、延迟、Token、队列、运行模型和 GPU 指标。

建议先把一个本地模型跑通,再逐步增加这些能力:
- 给不同客户端创建不同 API Key,方便统计和限流。
- 用 `Attribution` 把 `x-client-name`、`x-end-user-id`、`x-session-id` 映射到请求日志。
- 用 `Policies` 给 Claude Code、Continue 或 Open WebUI 设定不同路由。
- 用 `Settings` 设置全局请求大小限制,避免意外把超大上下文打到本地模型。
## 常见问题
- **登录后又回到登录页**:刷新一次应用入口,优先使用 `Continue with LazyCat`。如果仍失败,确认应用版本已经接入 OIDC。
- **Dashboard 是绿色,但模型列表为空**:说明 llama-dash 和 llama-swap 通了,但还没有可用模型。检查 `/models` 下是否有 GGUF 文件,并确认 `Config` 保存成功。
- **请求返回 502**:通常是模型启动命令失败、模型文件不存在、模型名写错,或者硬件资源不足。点开 `Requests` 详情,再去 `Logs` 看 llama-swap 的启动输出。
- **客户端能连上但没有日志**:确认客户端 Base URL 是 `/v1`,而不是直接指向 llama-swap;只有经过 llama-dash 的请求才会进入日志和指标。
- **需要远程客户端访问**:只给可信客户端发 API Key,并在 `API Keys` 里限制可用模型和速率。

'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)


'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

此 App 尚未收到足够的评分或评论,无法显示评论列表。