
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

Paperwise
AI 原生文档智能平台,支持 OCR、元数据自动提取、文档组织管理和基于文档内容的智能问答。
安装次数
点赞
应用评论
催更次数
桌面端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
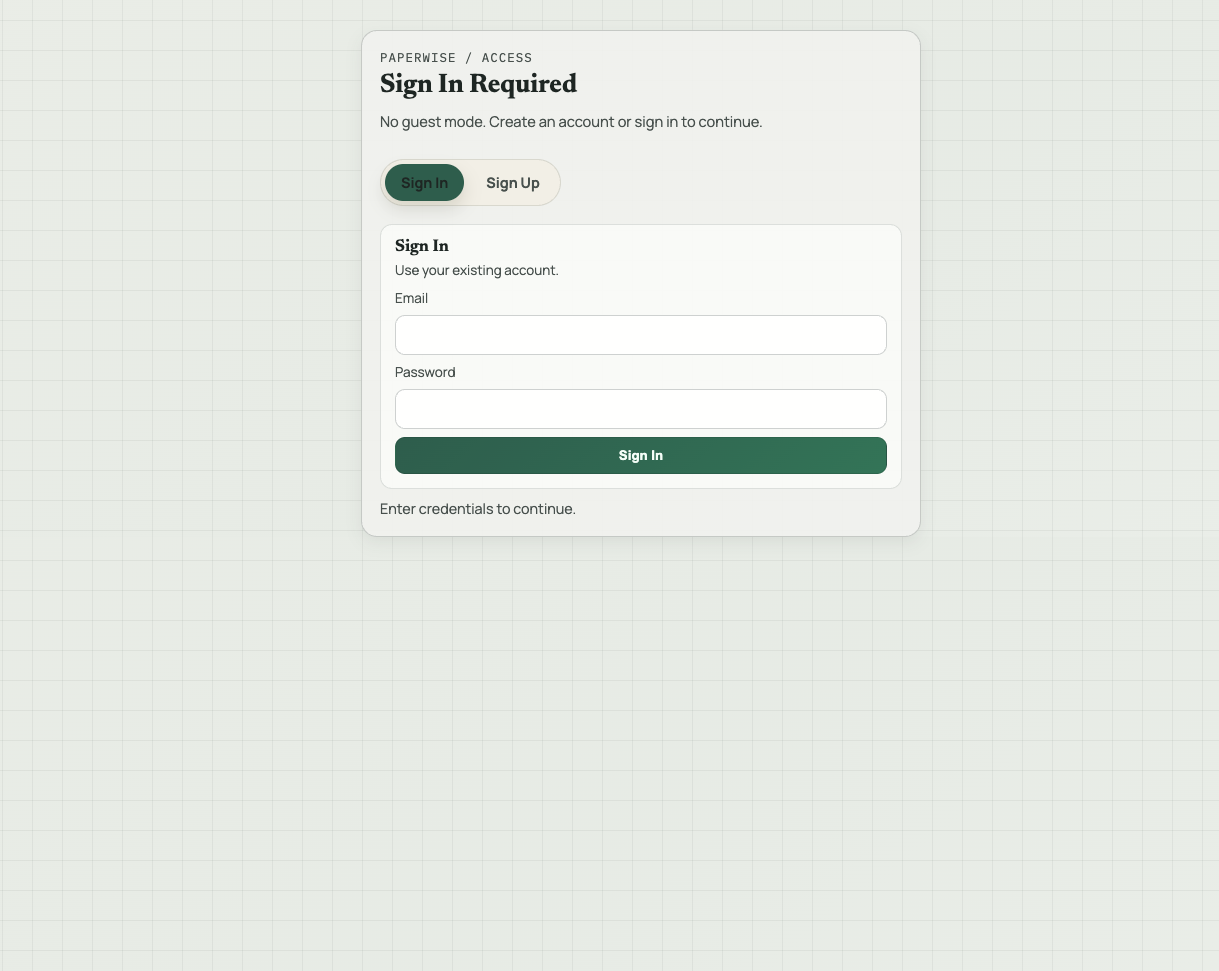
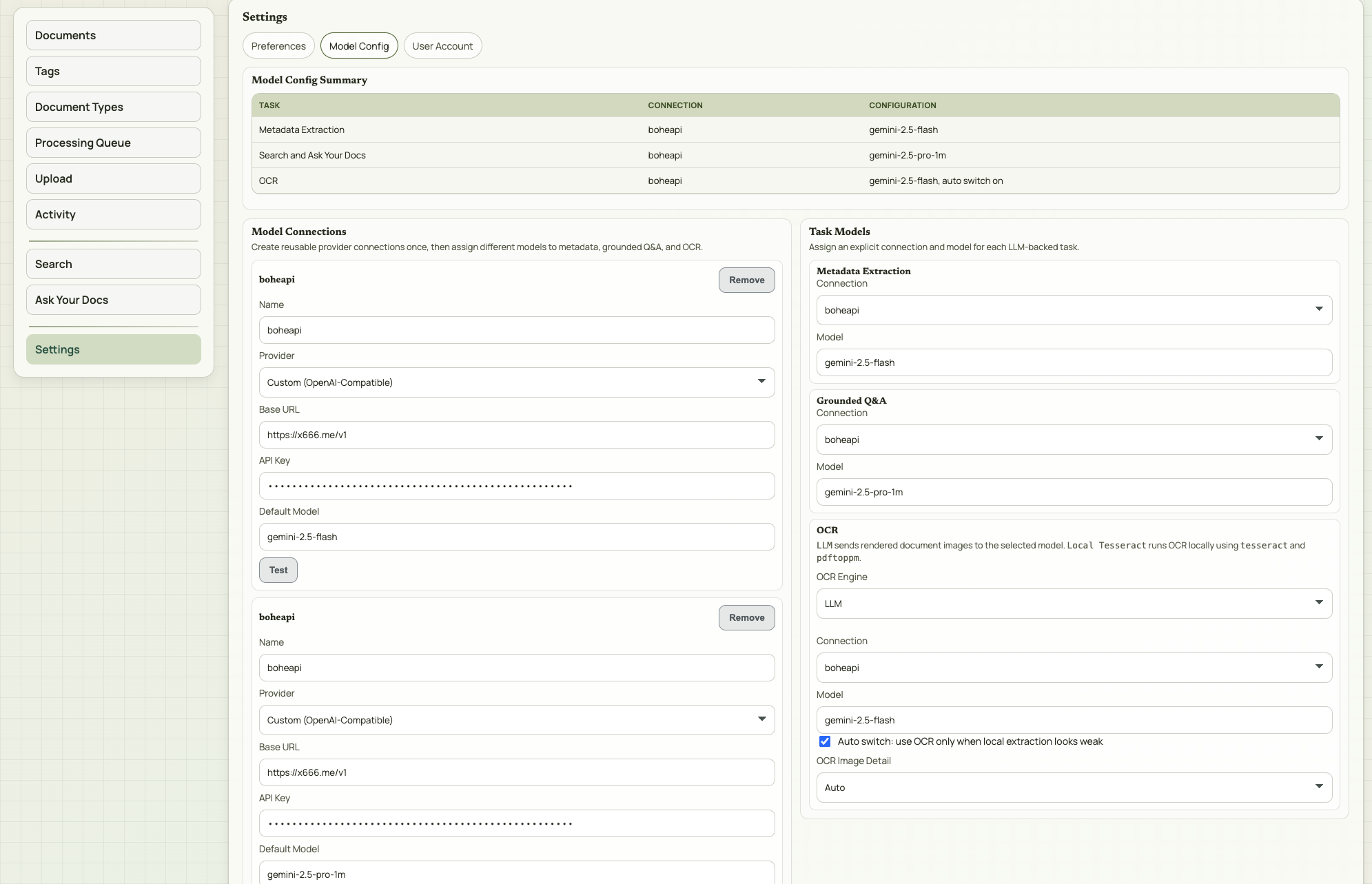
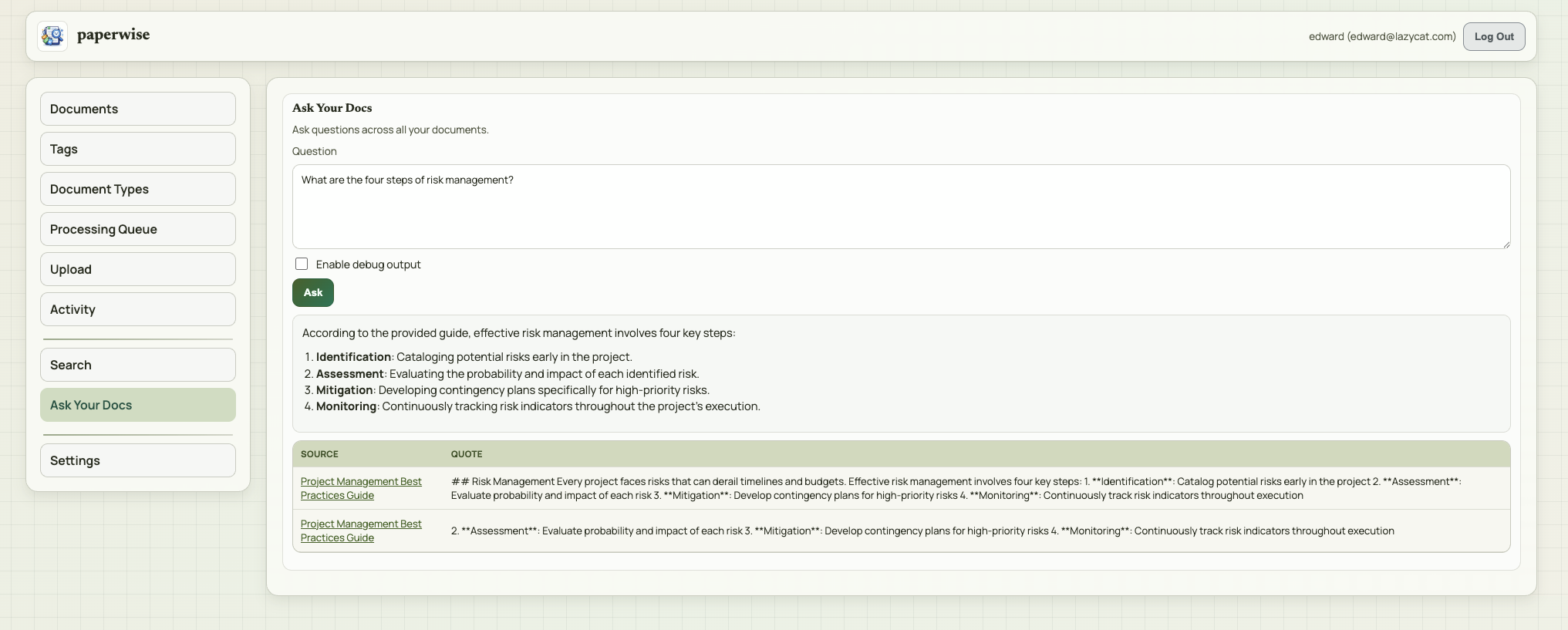
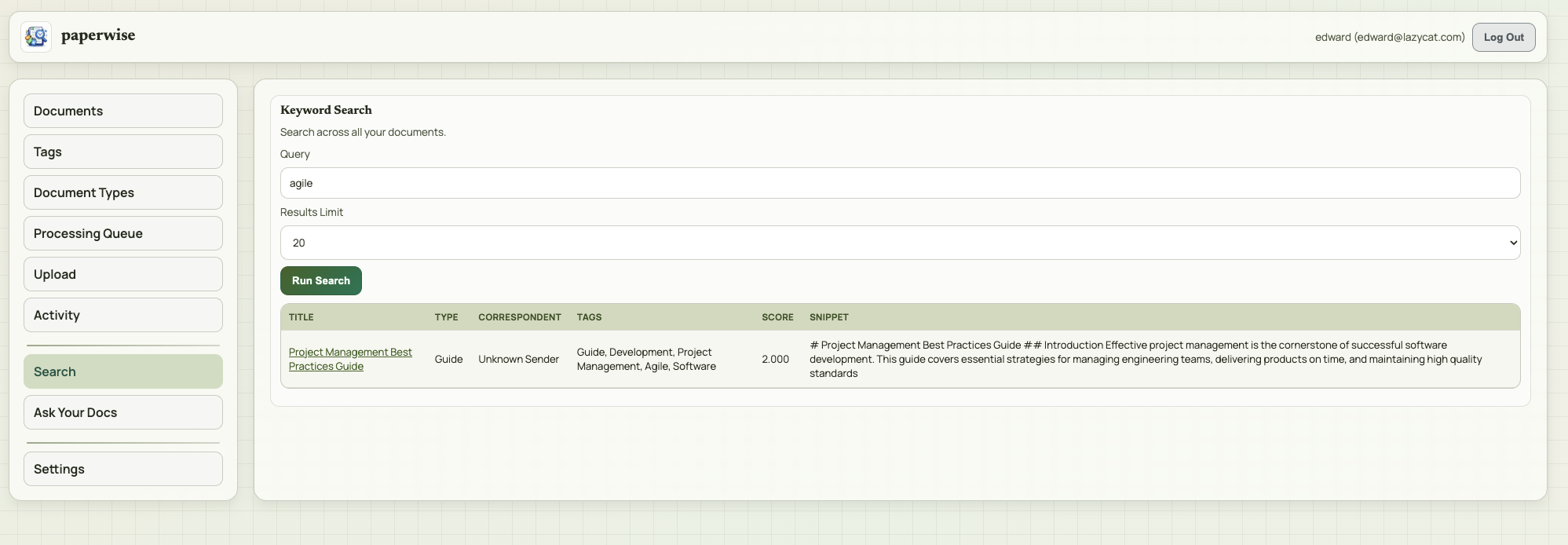
## 功能特性 - 📄 **文档上传与管理** — 支持 PDF、TXT、MD、DOCX、DOC 格式,拖拽上传 - 🔍 **OCR 文字识别** — 支持 LLM OCR(多模态模型)和本地 Tesseract 双模式,可自动切换 - 🏷️ **元数据自动提取** — AI 自动识别标题、日期、类型、标签、通讯方 - 🤖 **Ask Your Docs** — 基于文档内容的 Grounded Q&A,支持引用溯源 - 🔎 **关键字搜索** — 全文搜索所有文档(仅英文) - 📁 **Collections 文档集** — 将文档组织为集合进行分组问答 - 🔁 **文件去重** — 基于 SHA256 校验和自动防止重复上传 - 🎨 **多主题切换** — Atlas / Ledger / Moss / Ember 四套主题 - 👥 **多用户系统** — 用户注册、登录、密码修改,模型配置按用户独立存储 ⚠️ **重要**:请使用**英文文档**测试搜索和问答功能。中文文档可以上传和提取元数据,但搜索和问答不支持中文内容(原项目限制)。 ### 注册账号密码 Paperwise 没有游客模式,首次使用必须创建账号: 1. 在登录页面点击 **Sign Up** 标签 2. 填写 Full Name、Email、Password(建议6 位以上) 3. 点击 **Create Account** 完成注册 4. 自动登录进入主界面 ### 配置 AI 模型(首次使用必做) 文档上传后的元数据提取、OCR、问答功能都需要配置 AI 模型连接。每个用户的模型配置独立存储。 1. 点击左侧导航栏 **Settings** 2. 点击顶部 **Model Config** 子标签 3. 在 **Model Connections** 区域点击 **Add Connection** 4. 选择 Provider(OpenAI / Gemini / Custom) 5. 填写 API Key、Base URL(Custom 类型必填)、Model 6. 保存后在 **Task Assignments** 中为以下三个任务分配模型: - **Metadata Extraction** — 元数据提取(必配,否则无法上传) - **Grounded Q&A** — 文档问答(必配,否则 Ask Your Docs 不可用) - **OCR** — 文字识别(选择 LLM 或 Local Tesseract) > 💡 **快速配置**:只需添加一个 Provider 连接,为三个任务都使用同一个连接即可开始使用。如果文档多为清晰文本 PDF,可先用较快的模型,效果不满意再换更强的模型。 **OCR 模式说明**: | 模式 | 说明 | 适用场景 | |------|------|----------| | LLM OCR | 发送页面图片给多模态模型处理 | 扫描件、表单、图片密集型 PDF | | Local Tesseract | 在容器内使用 tesseract + pdftoppm 本地处理 | 隐私敏感场景、清晰印刷扫描件 | | Auto Switch(自动切换) | 直接文本提取效果不佳时自动回退到 OCR | 混合文档场景 | **官方推荐模型配置:** Paperwise 支持 GPT 和 Gemini 两套模型体系,建议按任务独立配置以获得最佳效果: | 任务 | GPT 推荐 | Gemini 推荐 | 说明 | |------|----------|-------------|------| | OCR | `gpt-5-mini` | `gemini-2.5-flash` | 快速多模态模型,适合扫描件和表单 | | Metadata Extraction | `gpt-5-mini` | `gemini-2.5-flash` | 结构化字段提取的平衡选择 | | Grounded Q&A | `gpt-5.1` | `gemini-2.5-pro` | 跨文档问答场景建议用更强的推理模型 | | 轻量分类/批量处理 | `gpt-5-nano` | `gemini-2.5-flash-lite` | 适合轻量级分类和分流任务 | > 💡 如果文档多为清晰文本 PDF,可先用较快的模型(mini/flash),效果不满意再换更强的模型。 ### 上传文档 1. 点击左侧 **Upload** 进入上传页面 2. 拖拽或点击选择文件(支持 PDF/TXT/MD/DOCX/DOC) 3. 点击 **Upload Selected Files** 4. 转到 **Processing Queue** 查看处理进度 5. 等待状态变为 **Ready** > 💡 Paperwise 会先尝试直接从文档提取文本。如果是扫描件或图片 PDF,则根据你设置的 OCR 模式进行处理。 > ⚠️ 相同文件(SHA256 校验和相同)不会被重复上传。 ### 搜索文档 > ⚠️ **重要限制**:Keyword Search 功能**仅支持英文关键词**搜索,中文关键词会返回空结果(原项目限制)。搜索匹配的是文档**正文内容**(OCR 提取的文本),不搜索标题或标签。 | 步骤 | 操作 | 测试数据 | 预期结果 | |------|------|----------|----------| | 1 | 点击左侧 **Search** | — | 显示关键字搜索界面 | | 2 | 输入**英文**搜索关键词 | `agile` 或 `risk management` | 返回匹配结果 | | 3 | 清空搜索框 | — | 清空结果 | ### Ask Your Docs 问答 > ⚠️ 需先完成模型配置(Grounded Q&A 任务已分配),且至少有一个已处理完成的**英文**文档 | 步骤 | 操作 | 测试数据 | 预期结果 | |------|------|----------|----------| | 1 | 点击左侧 **Ask Your Docs** | — | 显示问答界面 | | 2 | 输入英文问题并提交 | `What are the four steps of risk management?` | AI 返回答案,显示引用来源 | | 3 | 查看 Citations 表格 | — | 显示来源文档和引用片段 |
懒猫评分/评论
0.0
0 条评论
新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
暂无更新日志
此 App 尚未收到足够的评分或评论,无法显示评论列表。