
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

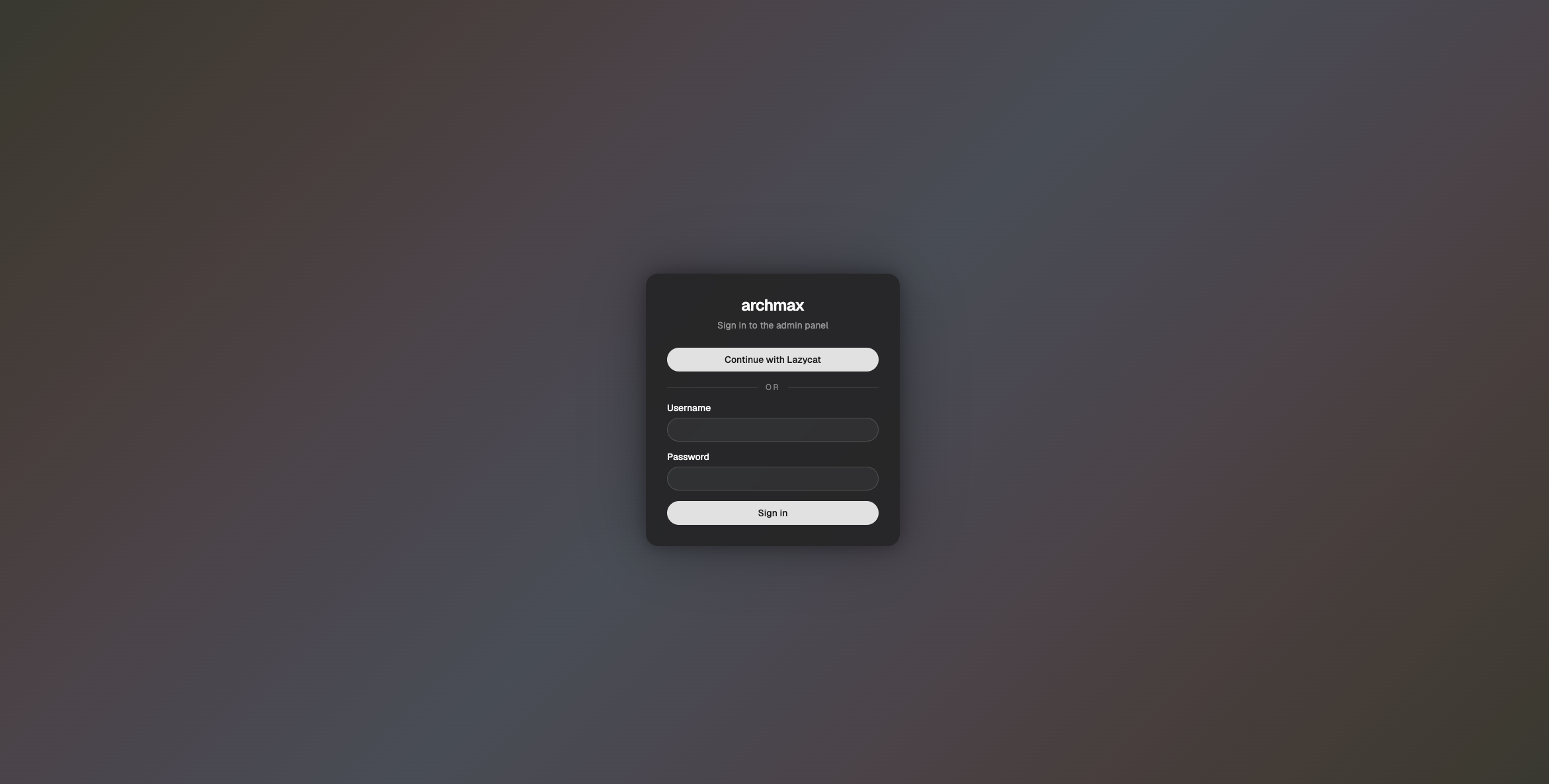
archmax
archmax是一个面向 AI 代理的语义数据层工作台,用来管理语义模型、统一多数据库查询入口,并通过 MCP 安全发布给外部智能体。
安装次数
点赞
应用评论
催更次数
桌面端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
应用描述
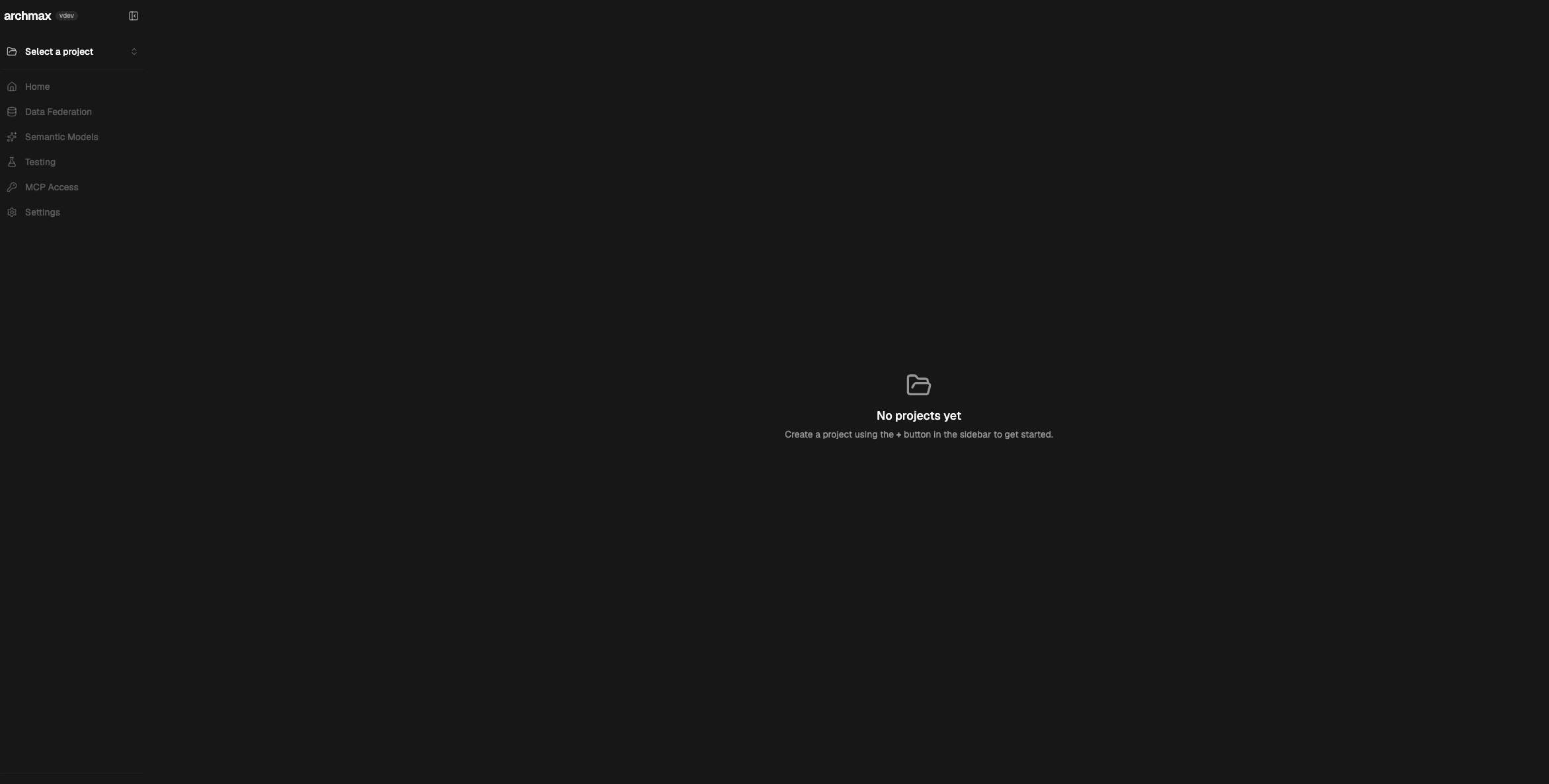
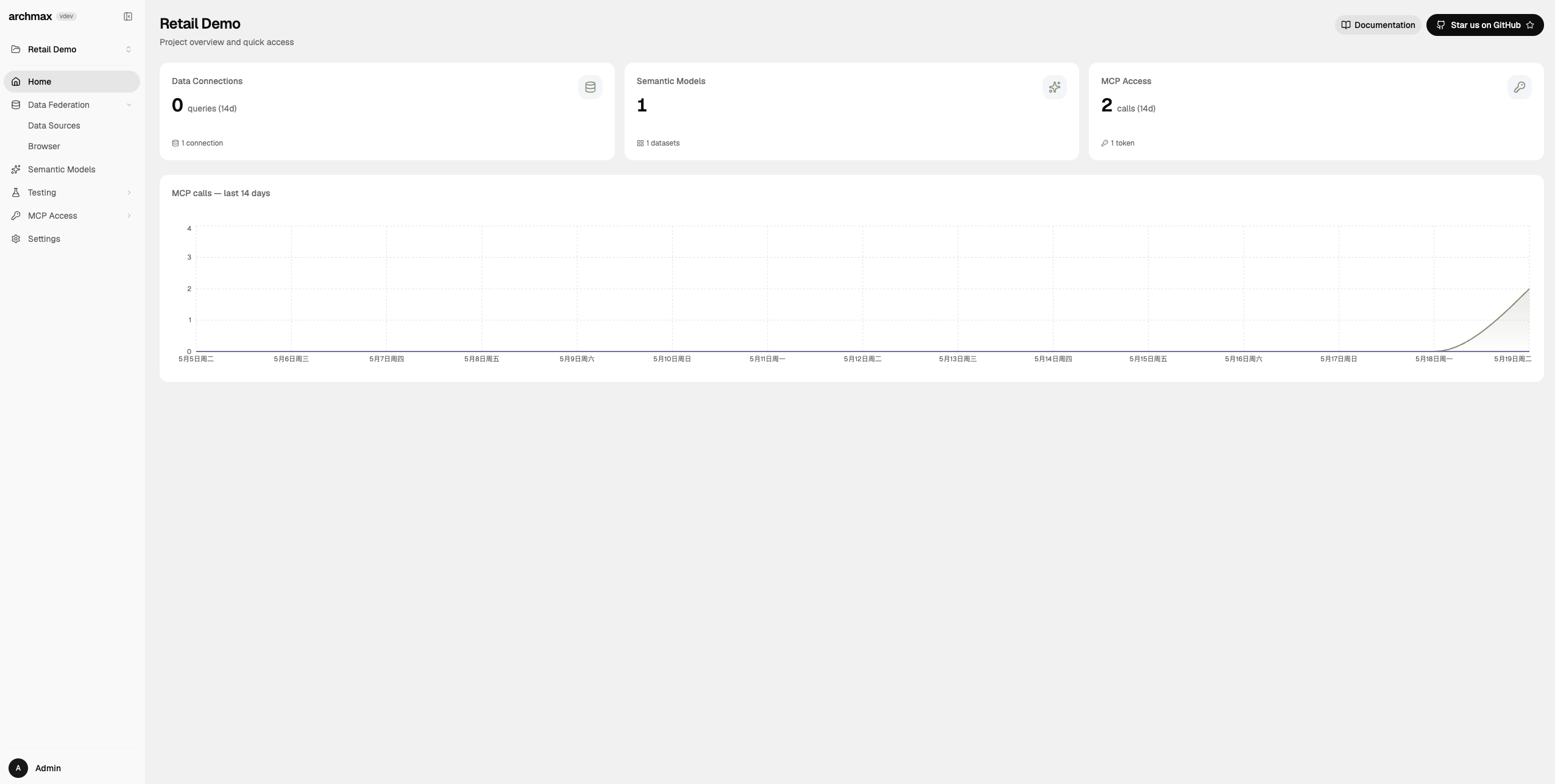
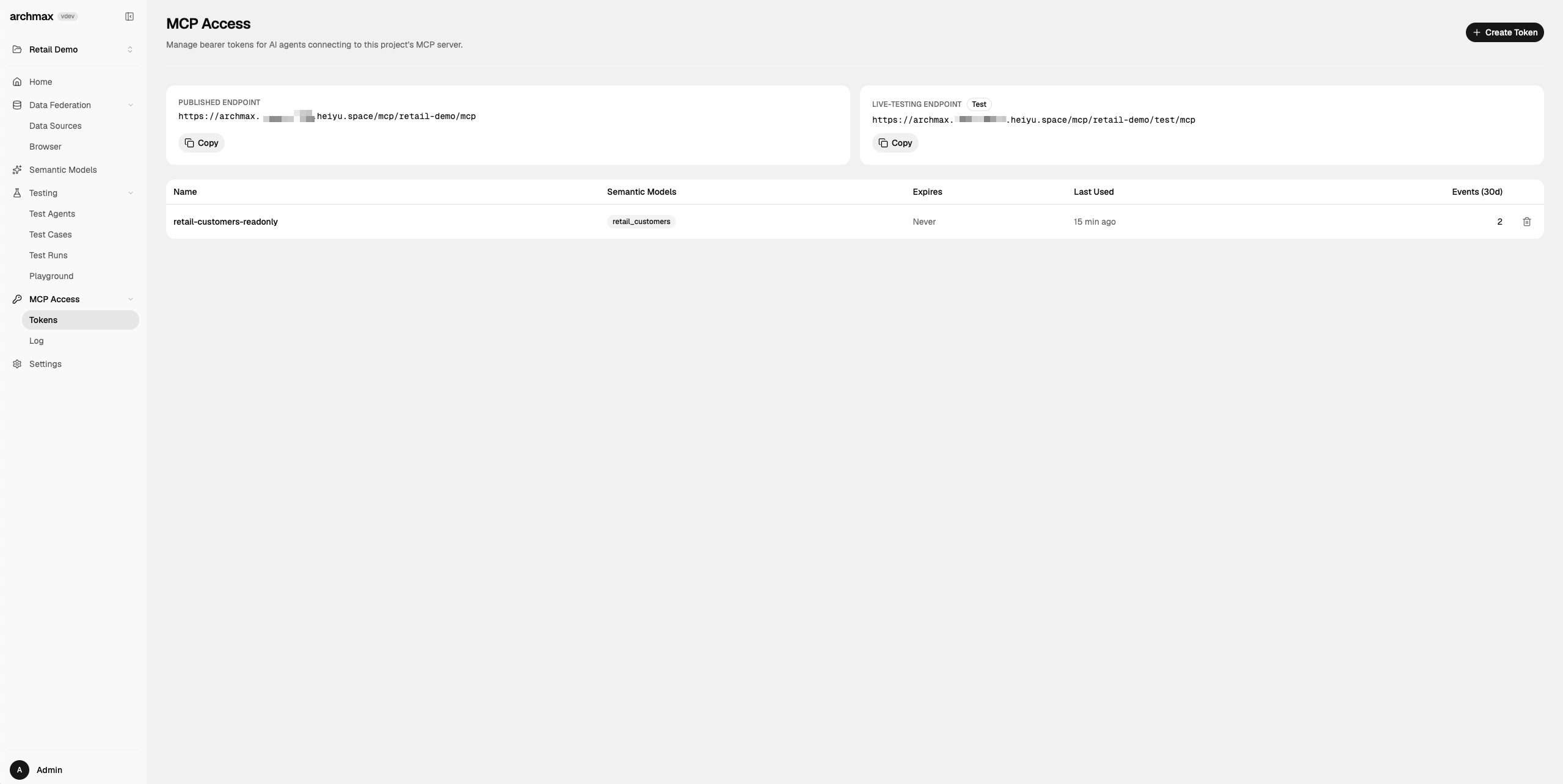
已集成懒猫OIDC登录。 ## 功能特性 - 语义模型管理:把数据库表整理成带字段说明、关系、指标和示例的 OSI YAML 语义模型,减少 AI 直接猜表猜字段。 - 多源数据联邦:统一接入 Postgres、MySQL、MSSQL、SQLite、DuckDB 和 Iceberg REST Catalog,用单一项目视角管理多库数据。 - MCP 发布能力:为每个项目生成受控的 MCP Endpoint 和访问 Token,让 Claude、Cursor 等兼容客户端只读访问语义层。 - AI 辅助建模:通过 `Semantic Model Builder` 自动发现 schema、补字段描述、识别枚举和推断关系。 - 测试与回归:内置 `Test Agents`、`Test Cases`、`Test Runs`、`Playground` 页面,可验证模型是否真的能被代理正确理解和查询。 - 项目设置与版本初始化:`Settings` 页面可维护项目名称、Slug、MCP 分页大小,并提供 `Initialize Git` 与项目删除入口。 - 单容器持久化部署:沿用上游内嵌 MongoDB/Redis 运行形态,只需挂载 `/data` 就能保存项目、MCP Token、发布记录和缓存数据。 ### 日常使用方式 1. 在 `Data Federation -> Data Sources` 页面点击 `New Connection`,按数据源类型填写连接信息。 `archmax` 当前支持 `postgres`、`mysql`、`mssql`、`sqlite`、`duckdb`、`iceberg` 六类连接。 2. 连接建立后点击 `Re-explore schemas`,让系统重新发现表和字段。 3. 进入 `Semantic Models` 页面,使用聊天式 `Semantic Model Builder` 补充业务语义、字段说明、关系和指标定义。 4. 完成整理后点击 `Publish`,把当前语义模型从项目 `src/` 目录装配到 `build/` 目录,再发布为 MCP 可消费版本。 5. 如需给外部智能体接入,在 `MCP Access -> Tokens` 页面创建 MCP Token,并复制页面展示的 `Published Endpoint`。注意:必须先有至少一个 semantic model,`Create Token` 才能提交;如果弹窗里直接显示 `No semantic models in this project.`,说明当前项目里还没有可选的模型文件。 6. 懒猫部署时要在 `lzc-manifest.yml` 里通过 `application.public_path` 放开 `/mcp/` 前缀,否则 `/mcp/<slug>/mcp` 和 `/mcp/<slug>/test/mcp` 会被盒子入口层重定向到 `/sys/login`,外部 MCP 客户端即使拿到 token 也无法直接接入。当前实测在放开 `/mcp/` 后,`Published Endpoint` 和 `Live-Testing Endpoint` 都已能返回 MCP 协议响应。 7. 若需验证模型效果,可在 `Testing` 分组下使用 `Test Agents`、`Test Cases`、`Test Runs`、`Playground`。 8. 在 `Settings` 页面可维护 `Project Identity`、`MCP Configuration`,并按需执行 `Initialize Git` 或 `Delete project`。 ### MCP 接入前准备 1. 先准备一个真实存在、并且已经能在 `Browser` 里读到表的数据库文件或外部数据库连接。本仓库当前最容易复现的测试数据是: `duckdb` 文件:`/data/external/retail-demo.duckdb` 2. `MCP Access` 只认 semantic model 文件,不认聊天记录本身。至少要在项目数据目录里存在一个模型 YAML,推荐路径形如: `/data/projects/<projectId>/src/<modelName>.yaml` 当前实测里,如果项目目录下没有 `src/` 子目录,应用也会回退读取项目根目录里的 YAML,例如: `/data/projects/<projectId>/retail_customers.min.yaml` 3. 如果你采用拆分数据集的写法,每个 dataset 还可以放在: `/data/projects/<projectId>/src/<modelName>/<datasetName>.yaml` 4. model 里的 `source` 需要指向应用里真实 attach 成功的连接路径,格式是: `<connection-slug>.<schema>.<table>` 例如本次 DuckDB 回归可写成:`retail_demo.main.customers` 5. `Published Endpoint` 和 `Live-Testing Endpoint` 的来源不同: `Published Endpoint` 读取项目 `build/` 目录里的已发布模型; `Live-Testing Endpoint` 临时装配当前 `src/` 目录里的模型,适合在正式发布前联调。 6. 只有完成 `Publish` 之后,`Published Endpoint` 才会真正拿到可消费的 assembled model。仅看到端点地址,不代表该端点已经有模型内容。 7. `Create Token` 时必须选中至少一个 semantic model 作为 scope。若弹窗里出现 `No semantic models in this project.`,就要先补模型文件,再回到 UI 创建 token。 8. 即使 token 创建成功,也还要从终端或外部 MCP 客户端再验证一次 `Published Endpoint` / `Live-Testing Endpoint`。本次实测里,请求需要带上 `Accept: application/json, text/event-stream`,然后先调用 `initialize`,再带 `mcp-session-id` 调 `tools/list` / `tools/call`。 ### 注意事项 1. `AI 服务 API Key` 不填写时,`Semantic Model Builder`、Testing Playground 和自动标题生成不可用,但项目管理、MCP 发布和 Git 初始化功能仍可使用。 2. `AI 服务 Base URL` `Test Agents -> Create Agent` 表单默认展示的是 `https://openrouter.ai/api/v1`。如果你使用 OpenAI、Azure OpenAI、Ollama 或其他 OpenAI 兼容接口,请改成对应地址;不要填写不带协议的地址,也不要只填域名片段。 3. `默认模型` 需要与上面的 OpenAI 兼容服务真实模型名一致,例如 `gpt-4.1`、`anthropic/claude-sonnet-4.6` 等。
懒猫评分/评论
0.0
0 条评论
新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
暂无更新日志
此 App 尚未收到足够的评分或评论,无法显示评论列表。