
'%3e%3cpath%20d='M9%2021H15'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M5.25001%209.75C5.25001%207.95979%205.96116%206.2429%207.22703%204.97703C8.4929%203.71116%2010.2098%203%2012%203C13.7902%203%2015.5071%203.71116%2016.773%204.97703C18.0388%206.2429%2018.75%207.95979%2018.75%209.75C18.75%2013.1081%2019.5281%2015.8063%2020.1469%2016.875C20.2126%2016.9888%2020.2472%2017.1179%2020.2474%2017.2493C20.2475%2017.3808%2020.2131%2017.5099%2020.1475%2017.6239C20.082%2017.7378%2019.9877%2017.8325%2019.8741%2017.8985C19.7604%2017.9645%2019.6314%2017.9995%2019.5%2018H4.50001C4.36874%2017.9992%204.23997%2017.964%204.12659%2017.8978C4.0132%2017.8317%203.91916%2017.7369%203.85387%2017.6231C3.78858%2017.5092%203.75432%2017.3801%203.75452%2017.2489C3.75472%2017.1176%203.78937%2016.9887%203.85501%2016.875C4.47282%2015.8063%205.25001%2013.1072%205.25001%209.75Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_133'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24%200H0V24H24V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M12%2011C14.2091%2011%2016%209.20914%2016%207C16%204.79086%2014.2091%203%2012%203C9.79086%203%208%204.79086%208%207C8%209.20914%209.79086%2011%2012%2011Z'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M4%2021V20.4857C4%2018.5655%204%2017.6055%204.38753%2016.872C4.72841%2016.2269%205.27235%2015.7024%205.94138%2015.3737C6.70196%2015%207.6976%2015%209.68889%2015H14.3111C16.3024%2015%2017.298%2015%2018.0586%2015.3737C18.7276%2015.7024%2019.2716%2016.2269%2019.6125%2016.872C20%2017.6055%2020%2018.5655%2020%2020.4857V21'%20stroke='black'%20stroke-width='2'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_4762_139'%3e%3crect%20width='24'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

AmicoScript
本地优先的隐私音频转录工具,基于 OpenAI Whisper 模型,支持说话人分离和 AI 智能分析
安装次数
点赞
应用评论
催更次数
桌面端
'%20fill='%23898989'%20fill-rule='nonzero'%3e%3cg%20id='编组-2'%20transform='translate(1443.000000,%20308.000000)'%3e%3cg%20id='路径-2'%20transform='translate(23.000000,%2019.000000)'%3e%3cpath%20d='M7.83273132,9%20L0.267897499,1.54066181%20C-0.0892991662,1.18844644%20-0.0892991662,0.616376893%200.267897499,0.264161526%20C0.625094164,-0.0880538418%201.20525435,-0.0880538418%201.56245102,0.264161526%20L9.73247155,8.32024678%20C9.921308,8.5064498%2010.0123135,8.75546831%209.99866269,9%20C10.0100384,9.24453169%209.921308,9.4935502%209.73247155,9.67975322%20L1.56472615,17.7358385%20C1.20752949,18.0880538%200.627369301,18.0880538%200.270172637,17.7358385%20C-0.0870240282,17.3836231%20-0.0870240282,16.8115536%200.270172637,16.4593382%20L7.83273132,9%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
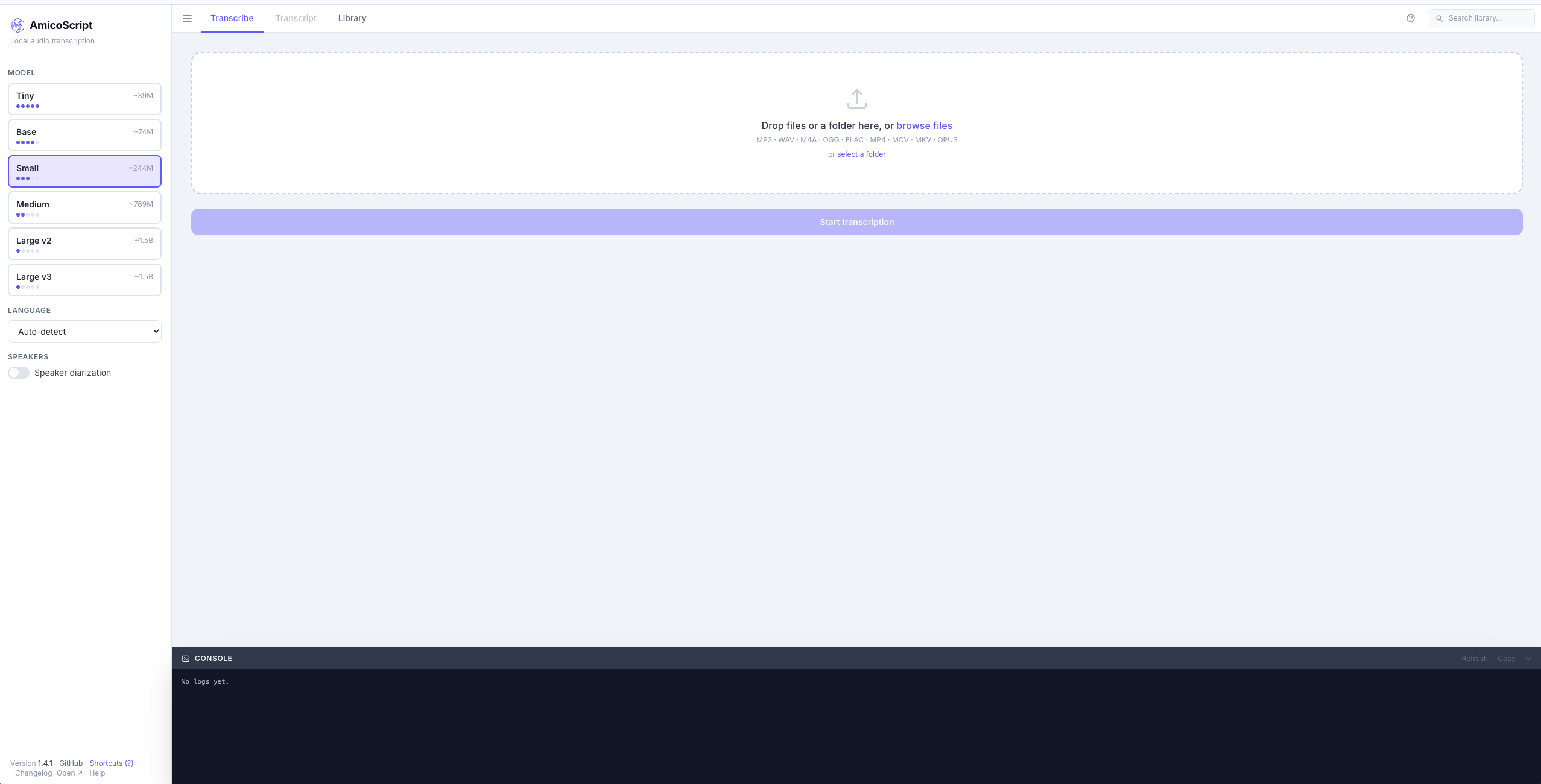
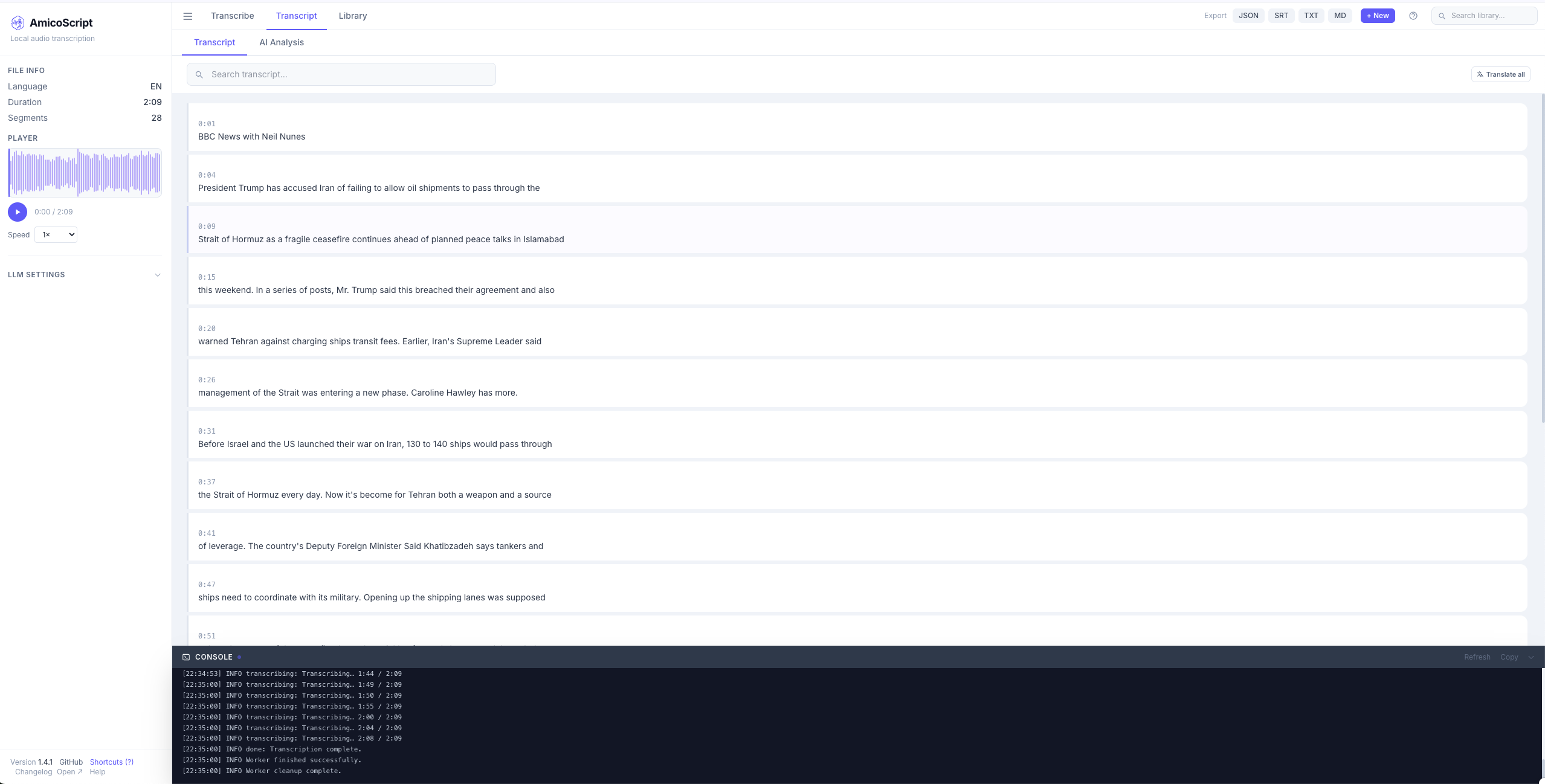
应用描述
## 功能特性 - 🎧 **音频/视频转录** — 支持 MP3、WAV、M4A、OGG、FLAC、MP4、MOV、MKV 等格式 - 📚 **批量处理** — 支持同时上传多个文件批量转录 - 🧠 **多级 Whisper 模型** — 从 tiny(~39M)到 large-v3(~1.5B),灵活选择精度与速度 - 🗣️ **说话人分离** — 基于 pyannote 的说话人识别(需 HuggingFace Token) - 🤖 **AI 分析** — 摘要、行动要点、翻译、自定义提示词(支持 Ollama / OpenAI 兼容 API) - 🌍 **实时英文翻译** — 转录时可同步翻译为英文 - 🔍 **全文检索** — 基于 SQLite FTS5 的全局搜索 - 🗂️ **文件夹和标签** — 灵活组织和管理转录内容 - ✏️ **逐段编辑** — 修正转录结果 - 📤 **多格式导出** — JSON、SRT、TXT、Markdown - ⌨️ **快捷键** — 快速导航和操作 ### 使用方法 1. 确保顶部导航停留在 **Transcribe** 选项卡,把音频文件拖入 **Drop files or a folder here** 区域(也可点击 browse files 选择) 2. 在左侧面板选择 Whisper 模型(推荐首次使用 `Small` 平衡速度和准确性) 3. 按需设置语言(默认 Auto-detect)或开启说话人分离(Speaker diarization) 4. 点击主区域底部的 **Start transcription** 按钮开始转录 5. 留意底栏 **CONSOLE** 的进度,完成后转录结果将在 **Transcript** 选项卡中展示 ### 配置说话人分离(可选) 说话人分离(Diarization)功能需要 HuggingFace Token: 1. 可在左侧“SPEAKERS”中打开 2. 对应填写HF API Key 3. 首次使用会自动下载 pyannote 模型(约 100MB) 注意:此功能需要结合小猪佩奇使用,请确保网络可访问 #### 配置LM SETTINGS(可选) 1. 在 **Transcript** 选项卡的左侧栏找到 **LLM SETTINGS** 2. **Base URL** 填入:`https://ollama-ai.<boxname>.heiyu.space`或`https://api.deepseek.com/v1`等API url 3. **Model** 填入:`qwen3:14b`(或按需选择其他模型,可点击 Browse 选择) 4. **API Key (optional)** 对应配置API Key 5. 点击 **Test Connection** 验证连接 ⚠️注意:| 纯音乐/歌曲转录效果差 | Whisper 专为语音识别设计,无法识别纯音乐,甚至在转录带有强烈伴奏的歌曲时可能会出现漏词或完全无输出(Segments: 0) | 音频转录 | 建议上传以人声对话、演讲、会议为主的音频 |
懒猫评分/评论
0.0
0 条评论
新功能
版本历史记录'%3e%3cpath%20d='M20%200H0V20H20V0Z'%20fill='white'%20fill-opacity='0.01'/%3e%3cpath%20d='M15.5%2010H4.5'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M10.5%205L15.5%2010L10.5%2015'%20stroke='%23545454'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1991_3173'%3e%3crect%20width='20'%20height='20'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
暂无更新日志
此 App 尚未收到足够的评分或评论,无法显示评论列表。